DBCC CHECKDB注意到有关数据文件页面。一旦整个表的所有页(或一组表,如果配料已启用-看到同样的博客文章我上面提到的),所有的事实都聚集在一起,他们都应该相互抵消。当有额外的事实(在索引B树都指向同一个页面在一个较低的水平如两页),或丢失的事实(如LOB片段没有任何其他LOB片段或数据/索引记录指向它),则DBCC CHECKDB可以告诉有一个腐败。
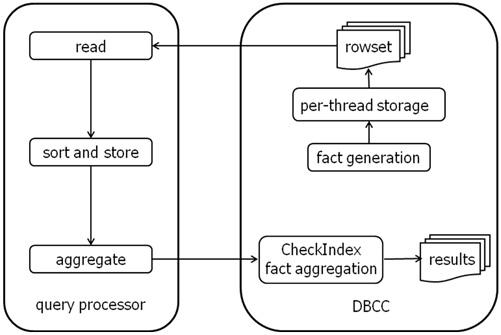
由于DBCC CHECKDB正在生成数据库基本上是随机页面所有这些因素(它读取物理顺序表中的页面,而不是逻辑顺序),必须有前聚集可以发生的事实的一些排序。这是使用查询处理器的所有驱动。在每个线程DBCC CHECKDB读取页面,生成的事实,并让他们给查询处理器进行排序和汇总。一旦所有的阅读完毕之后,事实再返还给内部并行线程DBCC CHECKDB找出损坏是否存在。
表明这一机制的画面看起来如下:
如果你正在做的任何跟踪或分析而DBCC CHECKDB正在运行时,你会看到下面的查询:
DECLARE @BlobEater VARBINARY(8000);
选择@BlobEater = CheckIndex(ROWSET_COLUMN_FACT_BLOB)
FROM <其实行集的内存地址>
GROUP BY ROWSET_COLUMN_FACT_KEY
>>带有ORDER BY
ROWSET_COLUMN_FACT_KEY,
ROWSET_COLUMN_SLOT_ID,
ROWSET_COLUMN_COMBINED_ID,
ROWSET_COLUMN_FACT_BLOB
OPTION(ORDER GROUP);
这个查询的部分的解释里面的SQL Server 2008中记录和即将里面的SQL Server 2012的书,我已经从我的DBCC内幕章下面引用它:
该查询带来的查询处理器和DBCC CHECKDB代码一起执行事实生成,事实排序,事实存储和事实聚集算法。是查询的部分如下:
- @BlobEater这是一个没有以外的其他使用来自任何输出目的的虚拟变量CheckIndex功能(永远不应该有任何,但语法要求的话)。
- CheckIndex(ROWSET_COLUMN_FACT_BLOB)这里面自定义聚合函数DBCC CHECKDB,查询处理器排序和分组的事实为整个事实聚集算法的一部分调用。
- <其实行集的内存地址>这是OLEDB行集的内存地址DBCC CHECKDB提供给查询处理器。查询处理器查询此行集行(包含生成的事实)作为整个事实生成算法的一部分。
- GROUP BY ROWSET_COLUMN_FACT_KEY这触发了查询处理器的聚集。
- >>带有ORDER BY <字段列表>这是仅供内部使用,提供了有序的聚合,凝聚工序语法。正如我先前所解释的,DBCC CHECKDB聚合代码是基于这样的假设,从查询处理器事实的凝集流的顺序被强制(即,它要求每个组内的键的排列顺序是顺序在查询中的四个键)。
- OPTION(订单组)这是一个查询优化器暗示的力量流聚集。它迫使查询优化器进行排序分组列,避免哈希聚集。