ML assignment #1
Problem:
implement classification model to train the Iris dataset and make predictions.
Environment:
Navigator and Jupyter notebook
Language:
python 2.7
Module:
graphlab, matplotlib
Workflow:
1、decision tree using trainset and testset
首先使用graphlab.SFrame.read_csv(“Iris.csv”)導入數據集,然後將數據集,然後將其random split為trainset 和 testset,使用graphlab.decision_tree_classifier.create(train_data,target = target,features = features)
訓練model.該function會自動進行pruning 來防止overfitting.
訓練結果:

接著使用model.evaluate()分析預測準確率,準確率結果為:0.9629629629629629
使用model.predict()對testset做出prediction,檢驗訓練模型. 並用 matplotlib畫出confusion matrix.
confusion matrix:
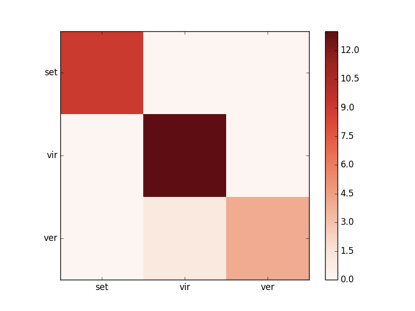
2、decision tree using K-fold cross validation
首先使用 graphlab.cross_validation.KFold(iris,10)將iris數據集進行10-fold拆分. 然後loop進行模型訓練,計算平均誤差.
最後的平均正確率結果為: 0.926666666667, 更佳符合實際.
3、decision using boosting
graphlab.boosted_trees_classifier.create(train_data,target=target,features=features)
對 train_data用boosting進行訓練,從結果中可以發現,耗時優於上面其他decision tree 算法.

接著使用model.evaluate()分析預測準確率,準確率結果為:0.9629629629629629
使用model.predict()對testset做出prediction,檢驗訓練模型. 並用 matplotlib畫出confusion matrix.
4、using random forest graphlab.random_forest_classifier.create(train_data,target=target,features=features)
對 train_data進行random forest訓練.
結果如下:
會發現耗時較長,效率較差.
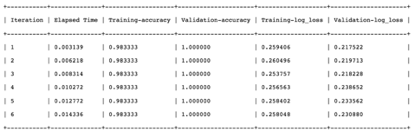
Conclusion:
總共使用了四種方法來對Iris 數據集進行模型訓練,其中1,3,4準確率相等,2略低但更符合test結果.所有的模型的confusion matrix均相同.