zoukankan
html css js c++ java
python--scrapy框架爬取分页数据与详情页数据
我们以abckg网址为例演示。
首先爬取详情页。
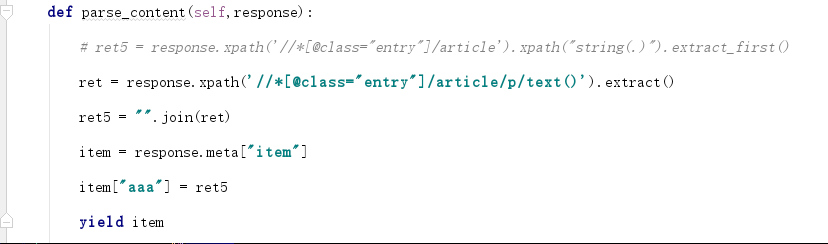
另外一种解析内容页:
然后是爬取分页:
还有一种方法就是设置一个方法循环爬取:
查看全文
相关阅读:
微信小程序-默认选中状态
微信小程序-翻页(优化)
openLayers3 中实现多个Overlay
2月的最后一天
2月27日
杂记--写于狂风乱作的夜晚
安装部署程序
superMap Object 属性查看的一点代码
坚持不懈的学习吧,少年
Windows API中几个函数的总结
原文地址:https://www.cnblogs.com/kitshenqing/p/11047468.html
最新文章
linux ssh scp sftp 生成密钥对
UnsupportedClassVersionError:JVMCFRE003bad 问题分析与解决
Oracle blob demo
读取Java文件到byte数组的三种方式
php 文件操作
php date
php 上传文件
PHP include
PHP 提交自动验证的订单
PHP 提交表单
热门文章
html 圣诞树
html 田字格
小程序输入框
小程序全局ajax
微信授权处理
授权
微信小程序-tab切换
全局js
全局ajax 请求
微信小程序-传递参数
Copyright © 2011-2022 走看看