面临的挑战:
1、硬件:宕机、例行重启、僵死;交换机故障
2、网络:抖动、丢包
3、流量突增(比如刘翔在奥运会中跌倒,流量会突增)
4、依赖第三方服务
架构防御:
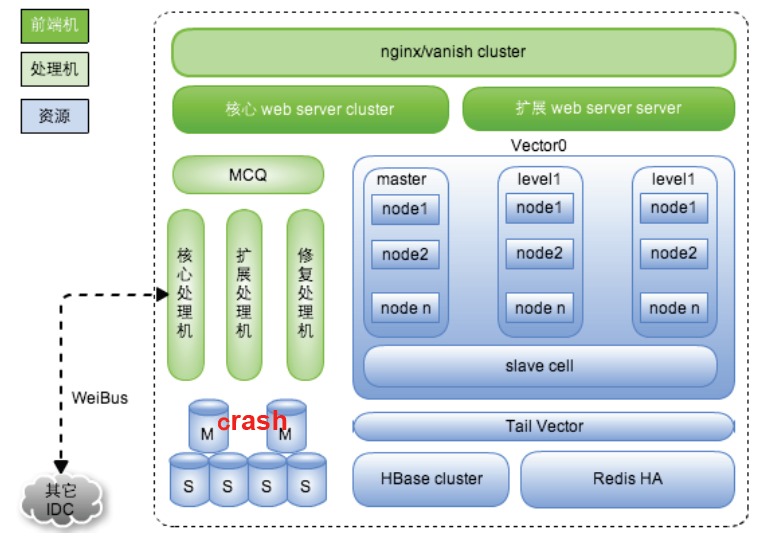
(1)mySQL是核心存储业务的依托,但是当mySQL全部宕机后,依然会有办法处理。此时,修复处理机会来进行处理,业务可以通过内存资源(vector0+tail Vector)来搞定。流量高峰时候,可以在vector0中增加level1的数量,流量少时减少即可。
(2)单点故障、单层故障都可以处理
主动监控运维:
1、传统监控运维局限性:(1)定期采集来分析(机器、资源数据,我们更关心业务数据;采集的某一时刻,我们需要某一段时间的数据;)
(2)分析的是现象,不是原因,对解决问题的时机会受影响
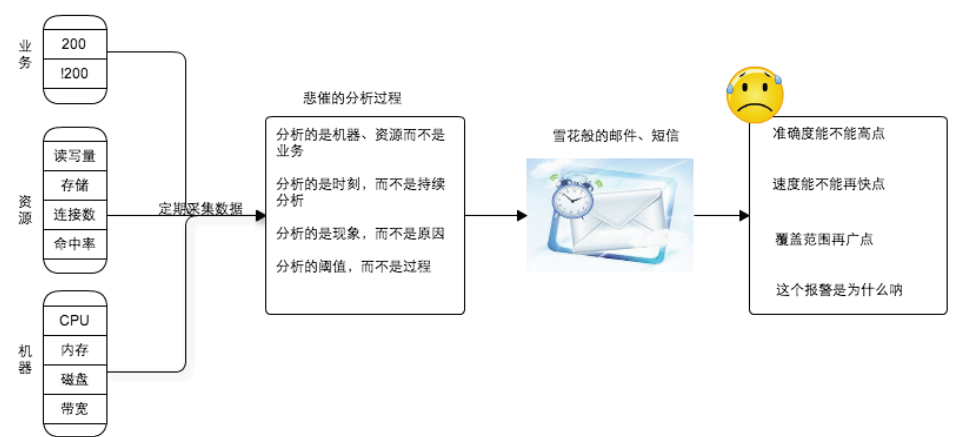
2、主动监控运维的提出:
(1)多维度监控(业务维度、机器、资源)
(2)趋势与过程监控
(3)实时监控(10s级别)
日志标准化:(实时来收集日志;每个前端机都有收集日志的工具)
1、万能的日志
(1)系统信息(CPU、内存、带宽、负载等)
(2)access日志
(3)资源、服务日志
2、统一的日志格式( IP 时间 UUID 用户ID 所属业务 日志内容…)
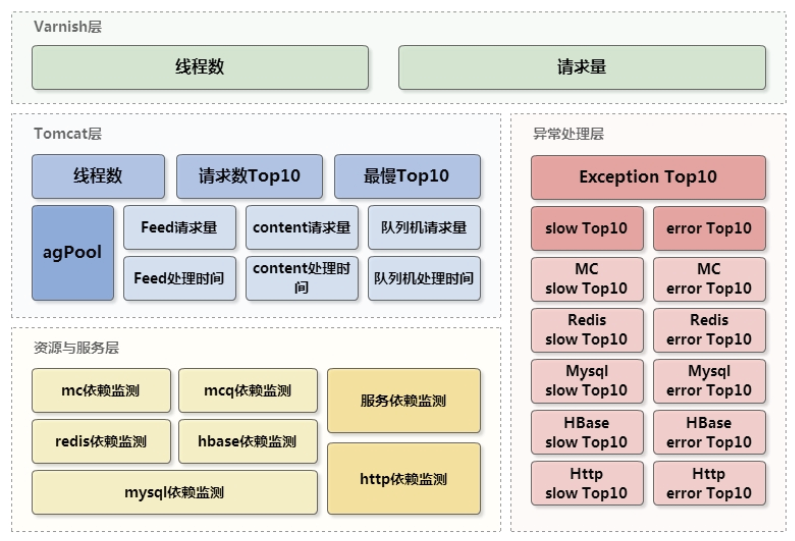
健康状况分析平台:
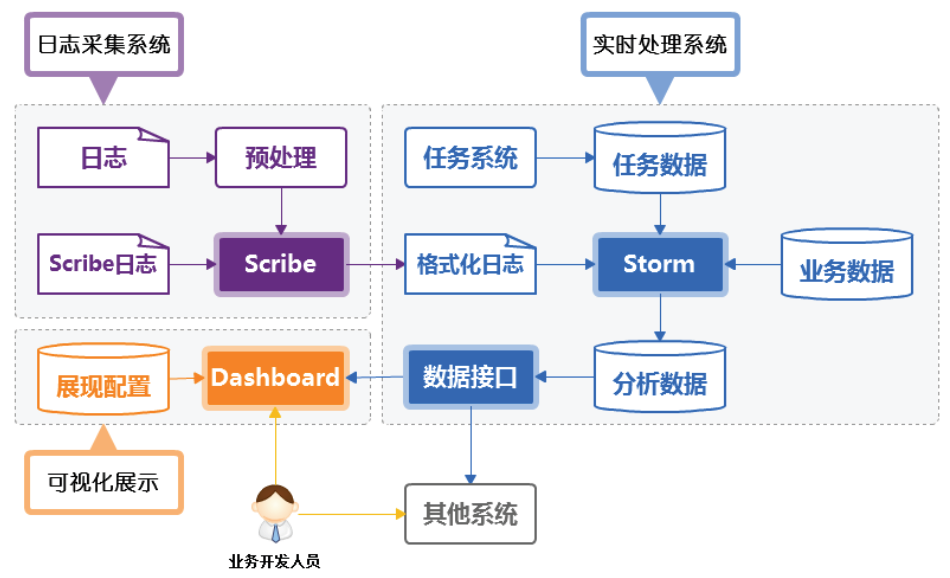
该平台依赖storm(计算能力强,每个节点都是中间节点)
其中,dashboard的使命为:面向业务的监控、趋势与过程监控、面向原因的监控、辅助原因分析
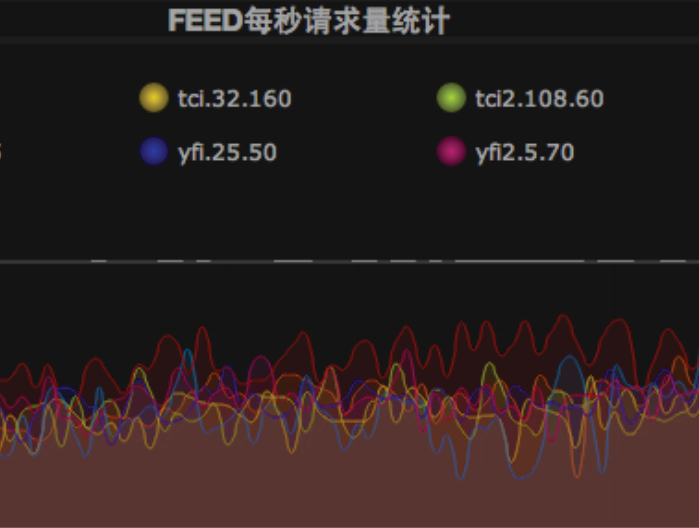


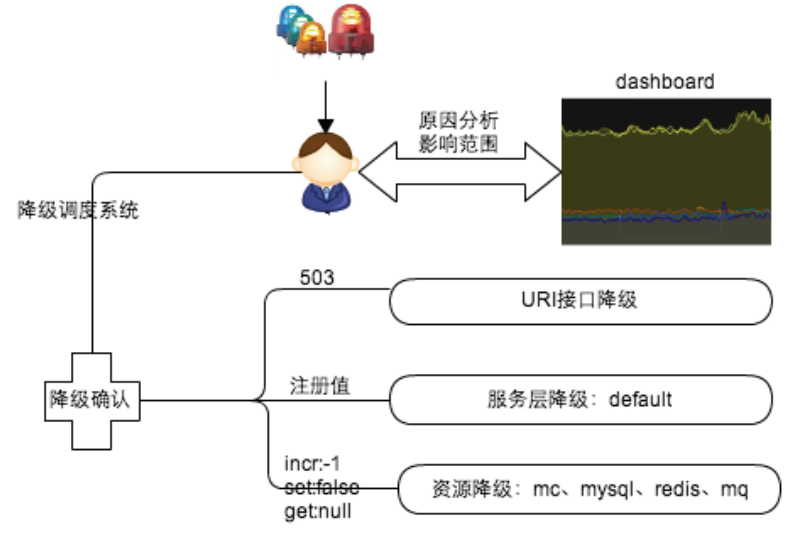
故障响应处理
1、时间就是一切;报警响应(报警灯亮起、报警灯提供受影响模块);问题分析->利用dashboard确认
2、按既定预案处理
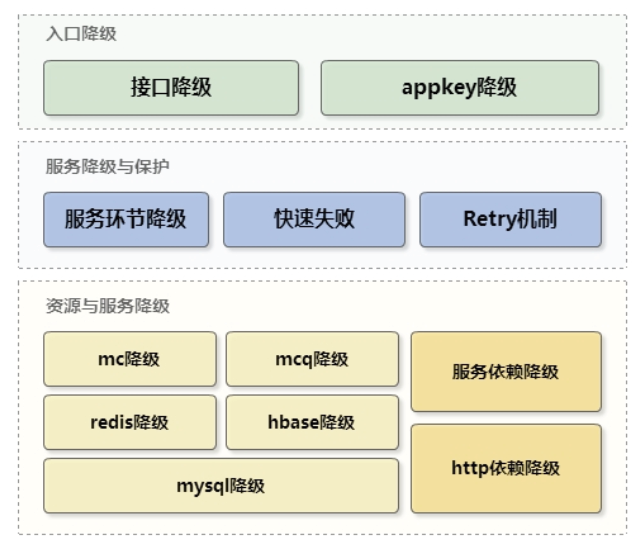
3、服务降级(接口降级、资源降级、服务降级)