0. Paper link
1. Overview
MobileNets是一种基于深度可分割卷积的轻量流线型结构,引进了两个简单的全局超参数在延迟与准确率之间达到了平衡,并且超参数让model builder可以按照不同的应用场景的限制去选择合适大小的模型,网络的主要贡献是把传统的卷积拆成了“deepwise convolution”与“pointwise convolution”来减少卷积过程的计算量与参数数量,同时利用了两个超参数来改变了网络的宽度与输入图片的分辨率。文章做的实验也比较好,是一篇值得学习各方面得文章,不仅仅是他的网络结构。
2. Depthwise Separable Convolution
2.1 architecture
MobileNet的网络结构基于Depthwise Separable Convolution, 它把传统的卷积操作拆成了两部分,一部分是Depthwise convolution,即对输入的每个channel使用一个卷积核,来达到对每一层做convolution的操作。另一部分是pointwise convolution,利用1 × 1卷积把Depthwise convolution的输出组合起来,从而达到传统convolution的效果,具体可以看下图:

2.2 computational cost
对于一个传统的卷积操作:假设输入与输出的feature map都是(D_F × D_F × M),卷积核为(D_K × D_K × M × N), 其中(D_F)与(D_K)是尺寸(作者假设输入等于输出并且都是正方形,实际网络模型可以处理任何大小与长宽比),M是通道数,N是卷积核的个数。
传统卷积操作如下(加padding):
传统卷积computational cost 如下:
depthwise convolution计算如下:
depthwise convolution的computational cost如下:
所以Depthwise Separable convolution cost:
他们之间computational cost的比例为:
3. Network Structure
MobileNet除了第一层是全卷积其他层的卷积都是使用Depthwise Separable convolutions,除了最后一层FC层数值直接送到softmax层之外,所有层后面都跟着BN层以及ReLU激活函数, 一个average pooling层在FC层之前把空间卷积减为1。
下图为 Depthwise Separable convolution的结构:

下表为一个MobileNet的整体结构:

以下为文中的一些具体实行细节,自己经验不多,直接翻译来增加一些知识储备。
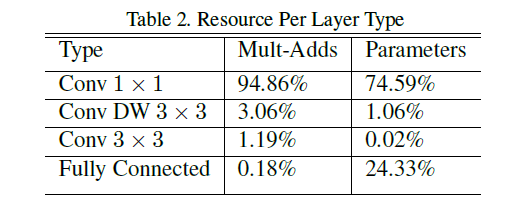
非结构化的稀疏矩阵操作通常不比密集矩阵运算快,除非是非常稀疏的矩阵。我们的模型结构将几乎全部的计算复杂度放到了1x1卷积中。这可以通过高度优化的通用矩阵乘法(GEMM)功能来实现。通常卷积由GEMM实现,但需要在称为im2col的内存中进行初始重新排序,以将其映射到GEMM。这个方法在流行的Caffe包中正在使用。1x1的卷积不需要在内存中重新排序而可以直接被GEMM(最优化的数值线性代数算法之一)实现。MobileNet在1x1卷积花费了95%计算复杂度,也拥有75%的参数(见表二)。几乎所有的额外参数都在全连接层。
下图为不同层的参数量:
使用类似于InceptionV3的异步梯度下降的RMSprop,MobileNet模型在TensorFlow中进行训练。然而,与训练大模型相反,我们较少地使用正则化和数据增加技术,因为小模型不容易过拟合。当训练MobileNets时,我们不使用sideheads或者labelsmoothing,通过限制croping的尺寸来减少图片扭曲。另外,我们发现重要的是在depthwise滤波器上放置很少或没有重量衰减(L2正则化),因为它们参数很少。
4. Width Multiplier: Thinner Models
加入一个超参数Width Multiplier (alpha)来使得模型更小更快,用来对网络中的每一层进行“瘦身”(thin)。输入的通道(M)变为(alpha M)输出的通道(N)变为(alpha N),因此加上Width Multiplier的cost为:
其中 (alpha in (0, 1]),Width multiplier有减少计算复杂度和参数数量((alpha ^ 2))的作用。
5. Resolution Multiplier: Reduced Representation
加入第二个超参数resolution multiplier ( ho)来统一减少输入图片跟中间每一层的特征。现在Depthwise Separable convolution 的计算量如下:
其中 ( ho in (0, 1]) 通常网络的输入像素设为224, 192, 160, 128.另外 ,resolution multiplier 也有减少计算复杂度和参数数量(( ho ^ 2))的作用。
Experiments
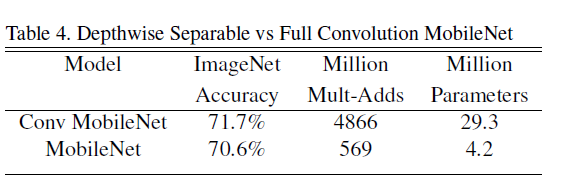
下图比较了MoilbeNet全卷积与Depthwise Separable convolution的性能,可以发现仅仅在准确率低了1%左右,参数却少很多
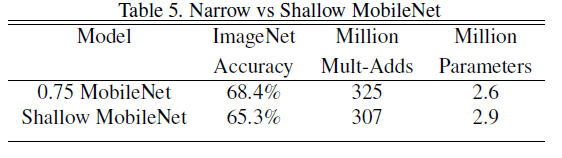
下面比较了 “浅层”网络与“瘦”网络的性能
下面实验在固定 ( ho) 改变 (alpha)来观察在ImageNet上的准确率变化

下面实验在固定(alpha)改变( ho)来观察在ImageNet上的准确率变化
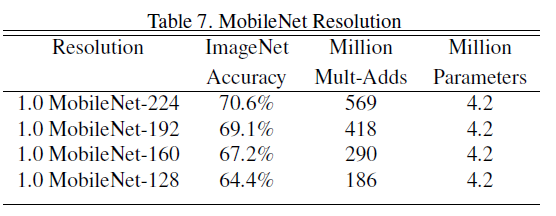
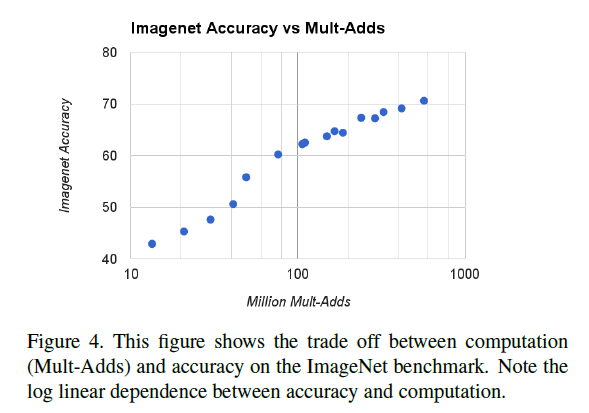
下面实验比较了随着计算量增大准确率的变化
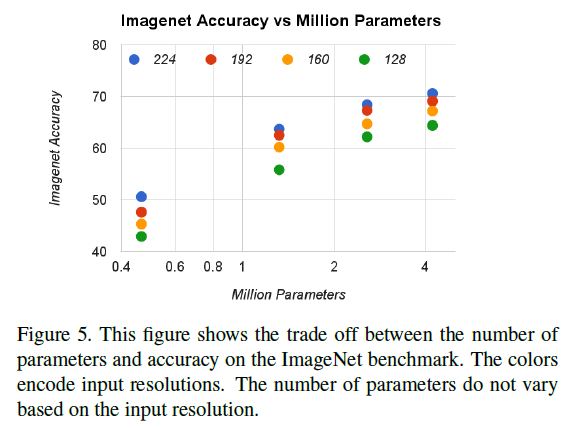
下面实验比较了 (alpha in {1, 0.75, 0.5, 0.25}) (
ho in {224, 192, 160, 128})一共16个模型的实验性能
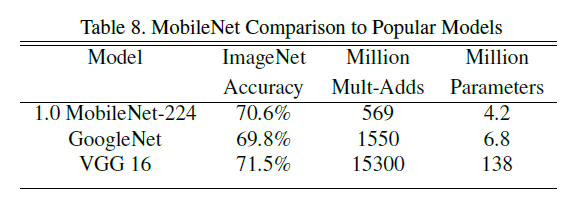
下面实验比较了MobileNet与VGG GoogLeNet 之间的准确、计算量与参数
下面实验比较了smaller MobileNet与Squeezenet AlexNet 之间的准确、计算量与参数

下面实验比较了各版本MobileNet与inception V3在细粒度分类方面的准确、计算量与参数

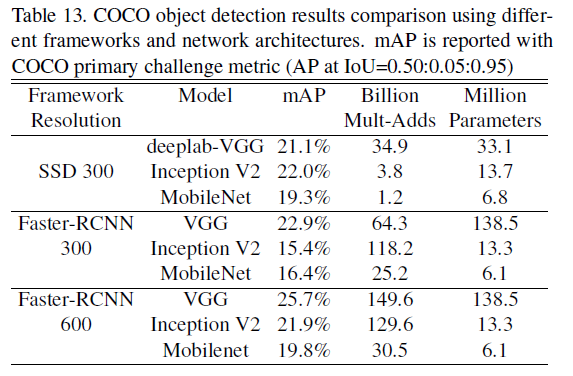
下面实验比较了各版本MobileNet与其他网络在目标检测方面的准确、计算量与参数