搜索结果排序是搜索引擎最核心的构成部分,很大程度上决定了搜索引擎的质量好坏。虽然搜索引擎在实际结果排序时考虑了上百个相关因子,但最重要的因素还是用户查询与网页内容的相关性。(ps:百度最臭名朝著的“竞价排名”策略,就是在搜索结果排序时,把广告客户给钱最多的排在前列,而不是从内容质量考虑,从而严重影响了用户体验)。这里要讲的就是:给定用户搜索词,如何从内容相关性的角度对网页进行排序。判断网页内容是否与用户查询相关,这依赖于搜索引擎所采用的检索模型,常见的检索模型有:布尔模型、向量空间模型、概率模型和机器学习排序算法等。在我的项目中,使用了向量空间模型(Vector Space Model,VSM),因此这篇文章主要总结一下向量空间模型相关的内容。
向量空间模型是一种文档表示和相似性计算的工具,不仅在搜索领域,在自然语言处理、文本挖掘等领域也是普遍采用的工具。
1. 文档表示
作为表示文档的工具,向量空间模型把每个文档看做是由 t 维特征组成的一个向量,特征的定义可以采取不同方式,最常见的是以单词作为特征,就是从一篇文档中抽取出 t 个关键词,其中每个特征会根据某种算法计算其权重,这 t 维带有权重的特征向量就用来表示这一篇文档。
下图展示了4个文档在3维向量空间中如何表示,比如对于文档2,它由3个带有权重的特征组成{w21, w22, w23}。在实际应用中,维度通常是非常高的,达成千上万维,这里只是为了简化说明。用户查询也被看成是一个特殊的文档,也将其转换成 t 维的特征向量,之所以也将其转化为一个 t 维向量,是为了计算文档相似性,后面会说的。
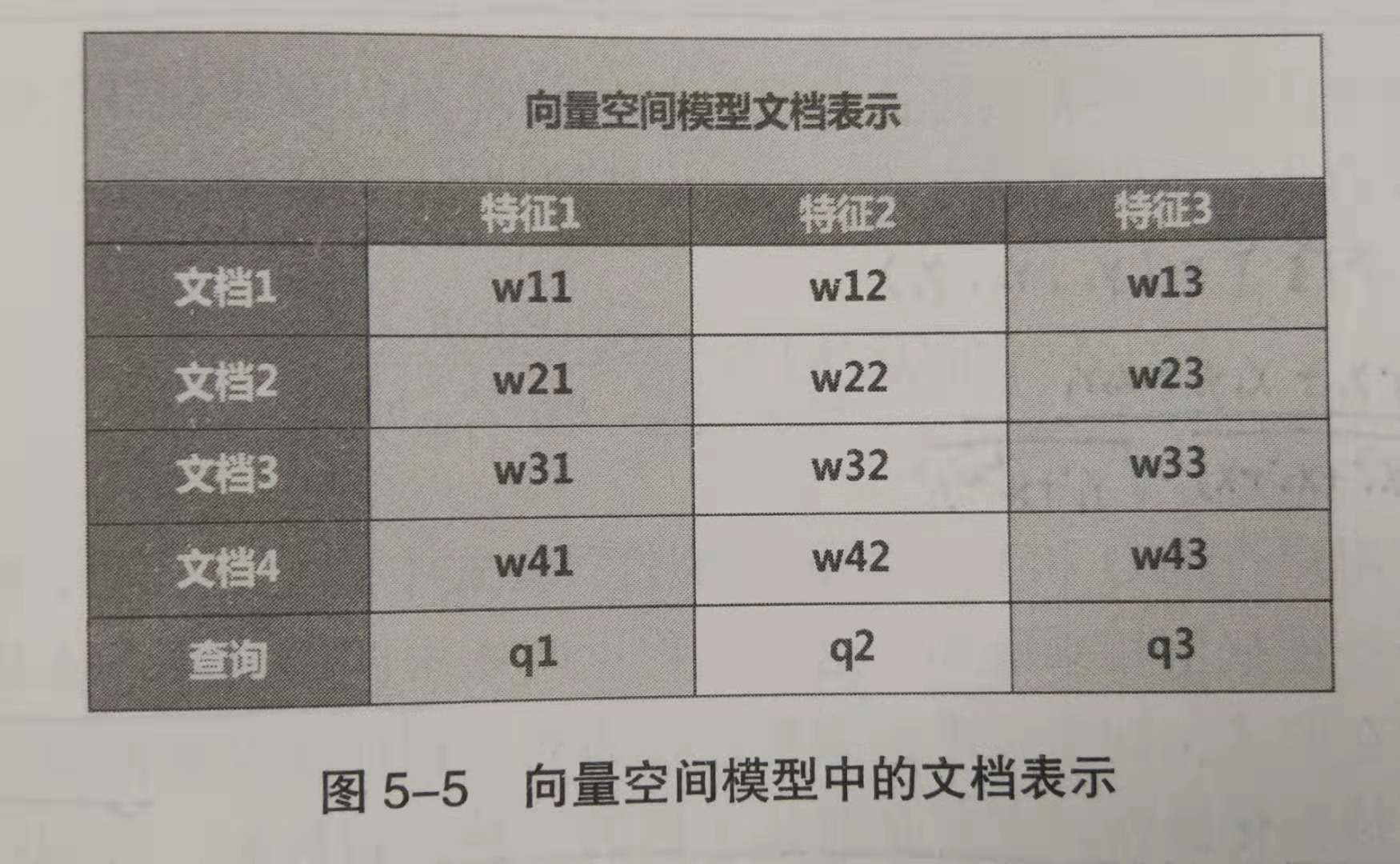
下面是一个文档表示的实例,对于文档D4、D5及用户查询,通过提取关键词进行特征转换,可表示如下。
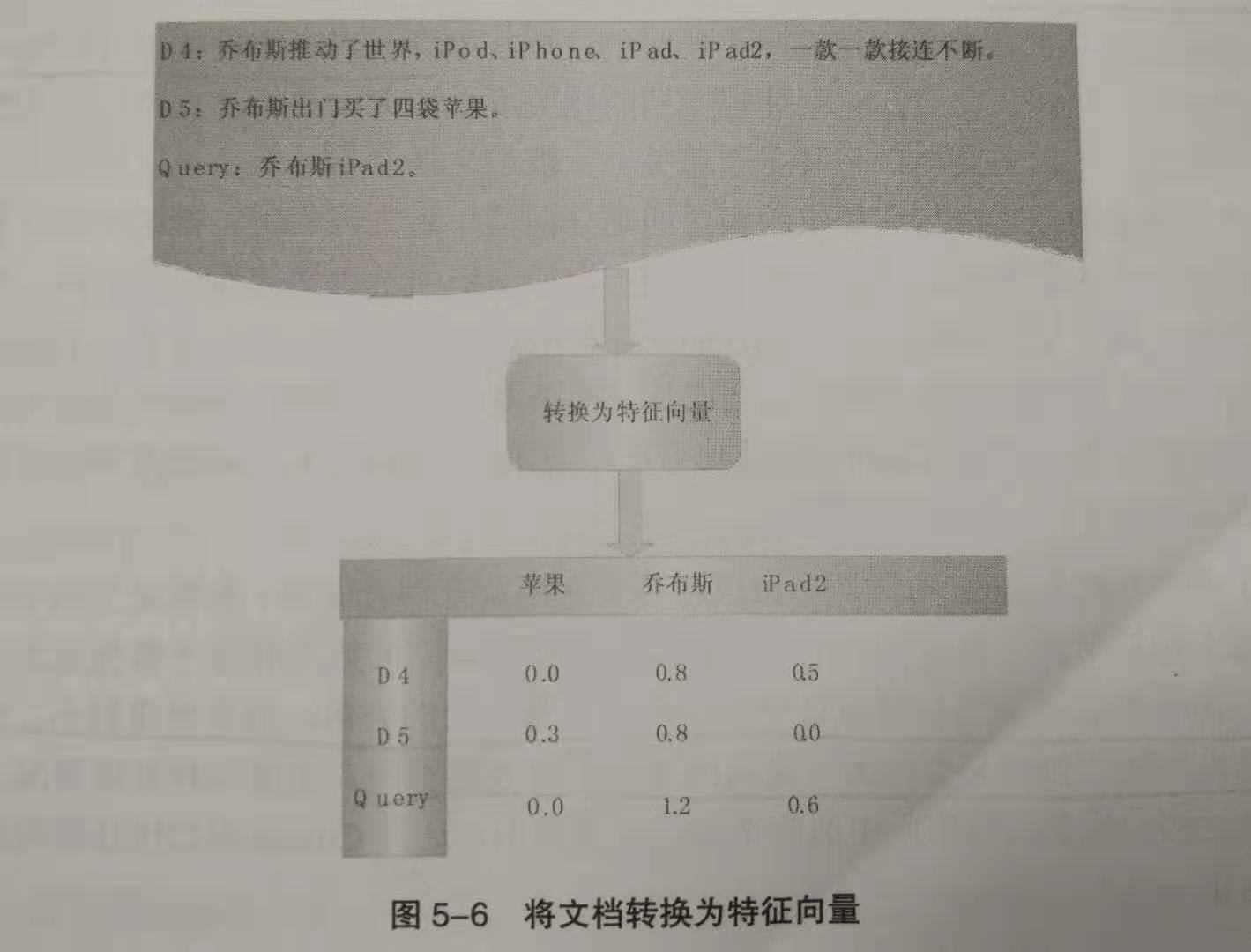
2. 特征向量和特征权重计算
对于初次接触该问题的人,肯定会疑惑,对于一篇几百字几千字的文章,如何生成足以准确表示该文章的特征向量呢?就像论文一样,摘要、关键词毫无疑问就是全篇最核心的内容,因此,我们要设法提取一篇文档的关键词,并对每个关键词计算其对应的特征权值,从而形成特征向量。这里涉及一个非常简单但又相当强大的算法,即TF-IDF算法。
TF-IDF算法涉及两个最重要的概念,即词频(Term Frequency,TF)和逆文档频率(Inversed Document Frequency,IDF)。
词频因子即一个单词在一篇文档中出现的次数,一般来说,在一篇文档中反复出现的词,往往能够表示文档的主题信息。
逆文档频率因子代表的是文档集合范围内的一种全局因子,给定一个文档集合,那么每个单词的IDF值就是唯一确定的,与具体的文档无关。IDF考虑的不是文档本身的特征,而是特征单词在整个文档集合范围内的相对重要性。这与词频因子有很大的不用,TF只反映了某个单词在具体某篇文档中的重要性程度。
在计算得到TF和IDF值之后,就可以计算一个关键词对应的权重了,即 weight = TF * IDF。
上面说的比较简略,回看TF-IDF算法之关键词提取 这篇文章。
3. 相似性计算
将文档转换为特征向量之后,就可以计算文档之间或者查询关键词与文档之间的相似性了。关于余弦相似性的计算方法和原理,在TF-IDF算法与余弦相似性这篇文章中已经详细说明了,稍微有区别的是,在那篇文章中只是简单的用词频向量进行相似性计算,而现在我们已经计算出了用于表示一篇文章的特征向量,就应该使用特征向量来计算不同文章之间的相关性。
总结:
向量空间模型的核心就是TF-IDF算法,这篇文章主要也只是对之前两篇文章的回顾和汇总。
参考:
1. 《这就是搜索引擎》 张俊林著 (本文主要是该书的读书笔记,算不上原创)
2. 阮一峰老师的博客