卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 它包括卷积层(convolutional layer)和池化层(pooling layer)。
对比:卷积神经网络、全连接神经网络
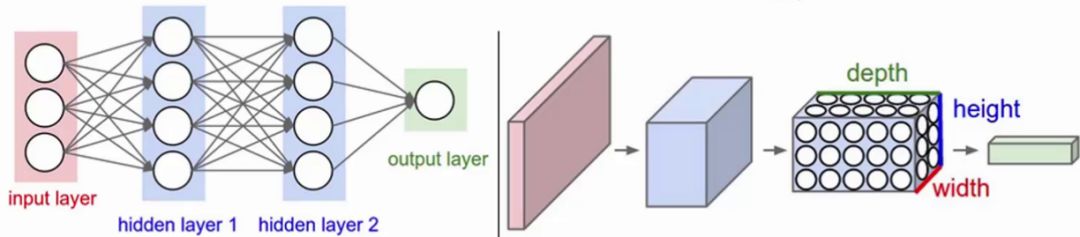
左图:全连接神经网络(平面),组成:输入层、激活函数、全连接层
右图:卷积神经网络(立体),组成:输入层、卷积层、激活函数、池化层、全连接层
在卷积神经网络中有一个重要的概念:深度
卷积层
卷积:在原始的输入上进行特征的提取。特征提取简言之就是,在原始输入上一个小区域一个小区域进行特征的提取,稍后细致讲解卷积的计算过程。
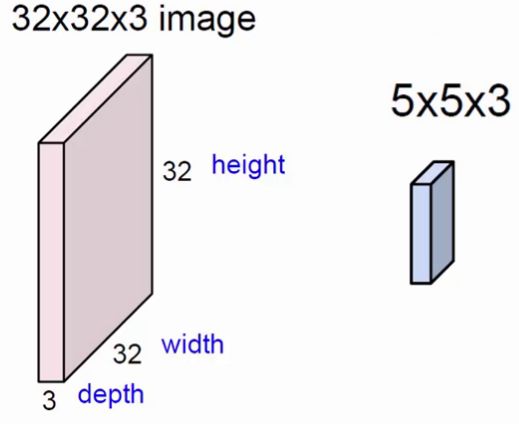
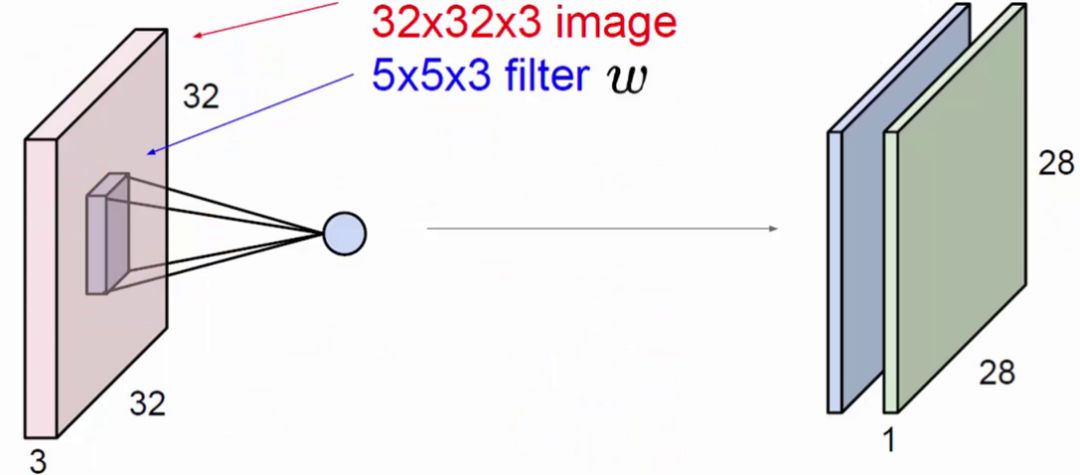
上图中,左方块是输入层,尺寸为32*32的3通道图像。右边的小方块是filter,尺寸为5*5,深度为3。将输入层划分为多个区域,用filter这个固定尺寸的助手,在输入层做运算,最终得到一个深度为1的特征图。
上图中,展示出一般使用多个filter分别进行卷积,最终得到多个特征图。
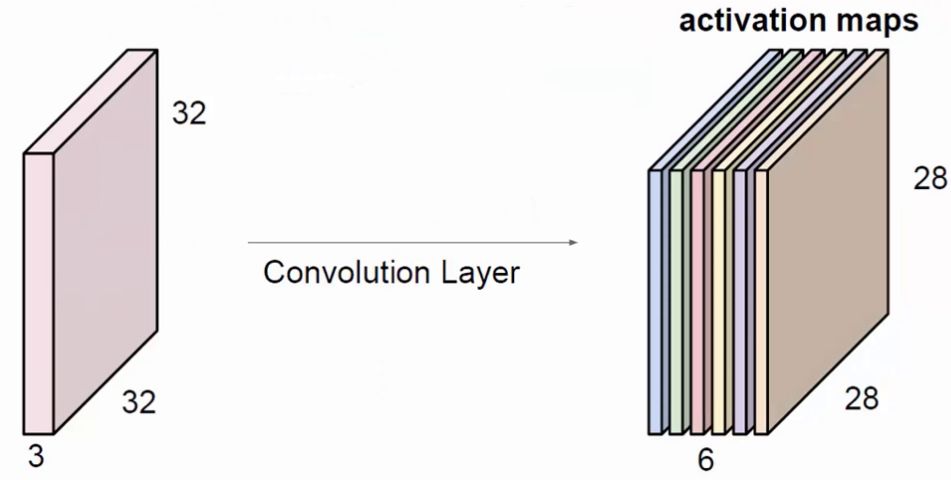
上图使用了6个filter分别卷积进行特征提取,最终得到6个特征图。将这6层叠在一起就得到了卷积层输出的结果。
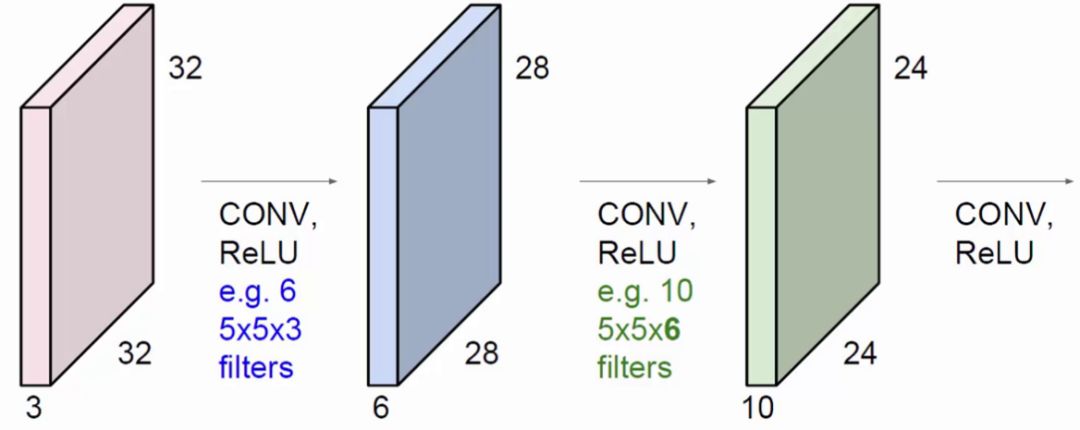
卷积不仅限于对原始输入的卷积。蓝色方块是在原始输入上进行卷积操作,使用了6个filter得到了6个提取特征图。绿色方块还能对蓝色方块进行卷积操作,使用了10个filter得到了10个特征图。每一个filter的深度必须与上一层输入的深度相等。
直观理解卷积

以上图为例:
第一次卷积可以提取出低层次的特征。
第二次卷积可以提取出中层次的特征。
第三次卷积可以提取出高层次的特征。
特征是不断进行提取和压缩的,最终能得到比较高层次特征,简言之就是对原式特征一步又一步的浓缩,最终得到的特征更可靠。利用最后一层特征可以做各种任务:比如分类、回归等。
卷积计算流程
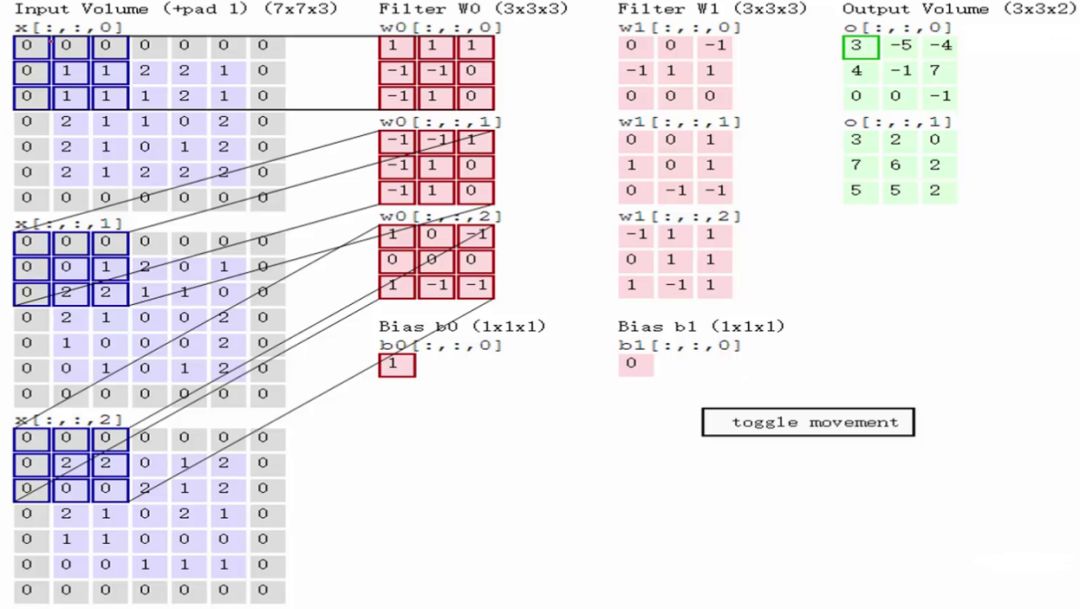
左区域的三个大矩阵是原式图像的输入,RGB三个通道用三个矩阵表示,大小为7*7*3。
Filter W0表示1个filter助手,尺寸为3*3,深度为3(三个矩阵);Filter W1也表示1个filter助手。因为卷积中我们用了2个filter,因此该卷积层结果的输出深度为2(绿色矩阵有2个)。
Bias b0是Filter W0的偏置项,Bias b1是Filter W1的偏置项。
OutPut是卷积后的输出,尺寸为3*3,深度为2。
计算过程:
输入是固定的,filter是指定的,因此计算就是如何得到绿色矩阵。第一步,在输入矩阵上有一个和filter相同尺寸的滑窗,然后输入矩阵的在滑窗里的部分与filter矩阵对应位置相乘:
即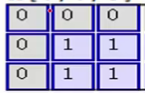 与
与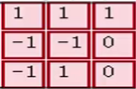 对应位置相乘后求和,结果为0
对应位置相乘后求和,结果为0
即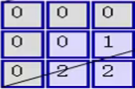 与
与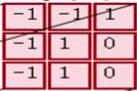 对应位置相乘后求和,结果为2
对应位置相乘后求和,结果为2
即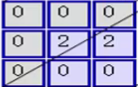 与
与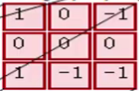 对应位置相乘后求和,结果为0
对应位置相乘后求和,结果为0
第二步,将3个矩阵产生的结果求和,并加上偏置项,即0+2+0+1=3,因此就得到了输出矩阵的左上角的3:
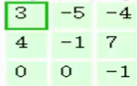
第三步,让每一个filter都执行这样的操作,变可得到第一个元素:
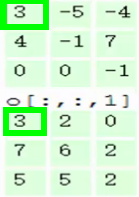
第四步,滑动窗口2个步长,重复之前步骤进行计算
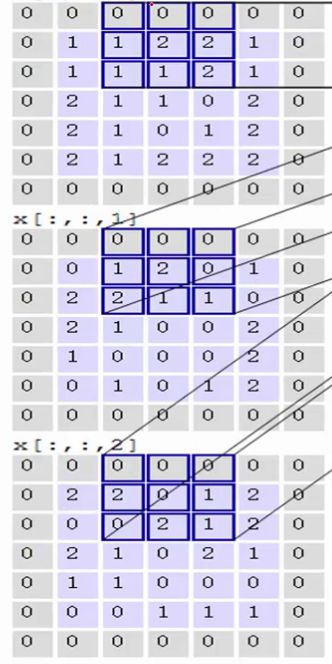
第五步,最终可以得到,在2个filter下,卷积后生成的深度为2的输出结果:
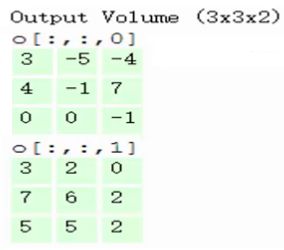
思考:
①为什么每次滑动是2个格子?

滑动的步长叫stride记为S。S越小,提取的特征越多,但是S一般不取1,主要考虑时间效率的问题。S也不能太大,否则会漏掉图像上的信息。
②由于filter的边长大于S,会造成每次移动滑窗后有交集部分,交集部分意味着多次提取特征,尤其表现在图像的中间区域提取次数较多,边缘部分提取次数较少,怎么办?
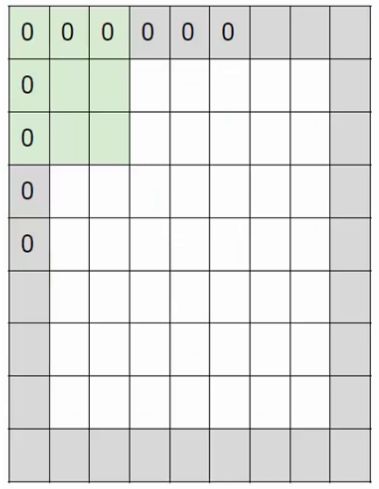
一般方法是在图像外围加一圈0,细心的同学可能已经注意到了,在演示案例中已经加上这一圈0了,即+pad 1。 +pad n表示加n圈0.

③一次卷积后的输出特征图的尺寸是多少呢?
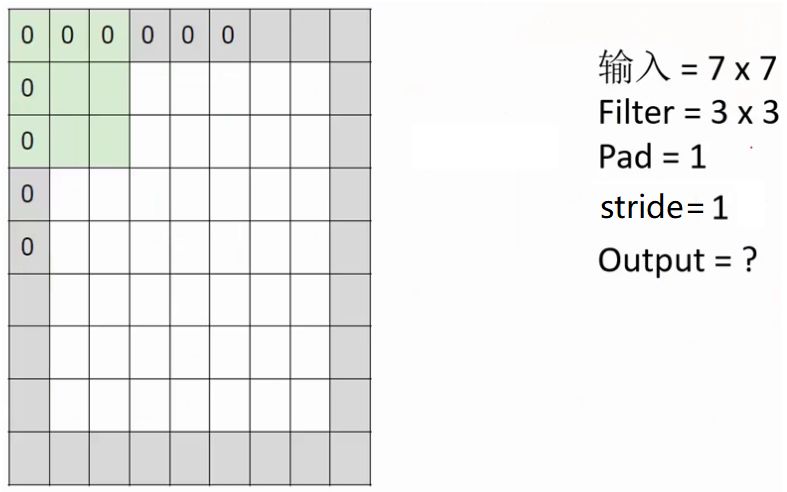
请计算上图中Output=?
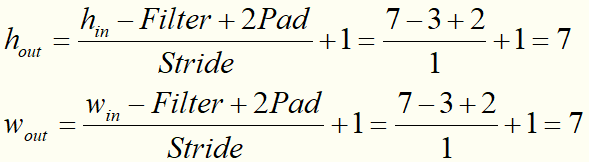
注意:在一层卷积操作里可以有多个filter,他们是尺寸必须相同。

卷积参数共享原则

在卷积神经网络中,有一个非常重要的特性:权值共享。
所谓的权值共享就是说,给一张输入图片,用一个filter去扫这张图,filter里面的数就叫权重,这张图每个位置是被同样的filter扫的,所以权重是一样的,也就是共享。
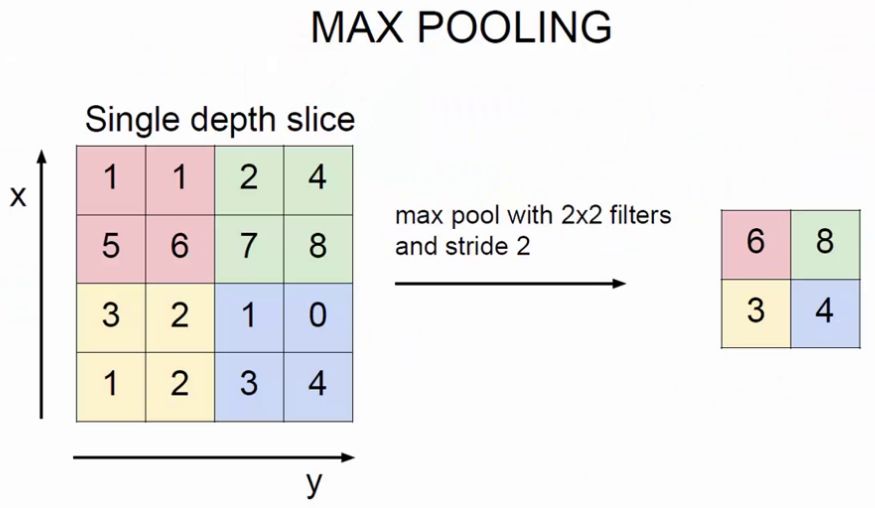
池化层
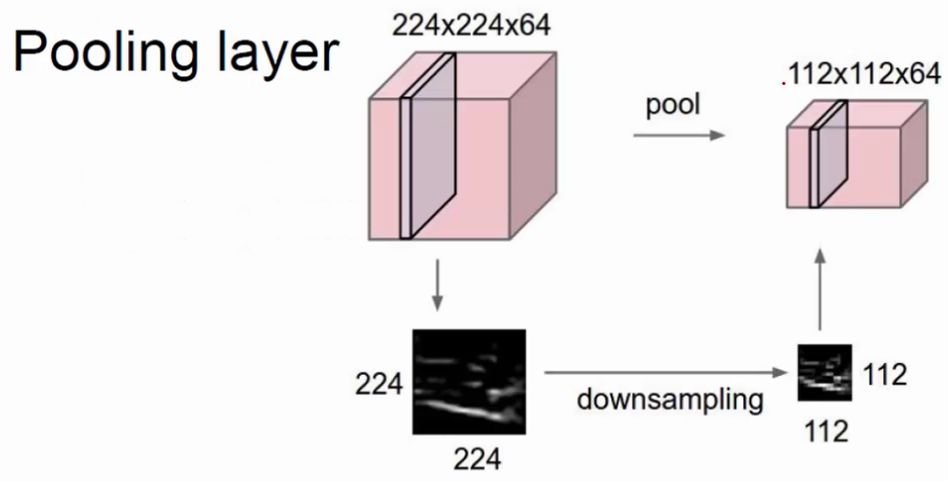
上图显示,池化就是对特征图进行特征压缩,池化也叫做下采样。选择原来某个区域的max或mean代替那个区域,整体就浓缩了。下面演示一下pooling操作,需要制定一个filter的尺寸、stride、pooling方式(max或mean):
卷积神经网络的组成

卷积——激活——卷积——激活——池化——......——池化——全连接——分类或回归
前向传播与反向传播
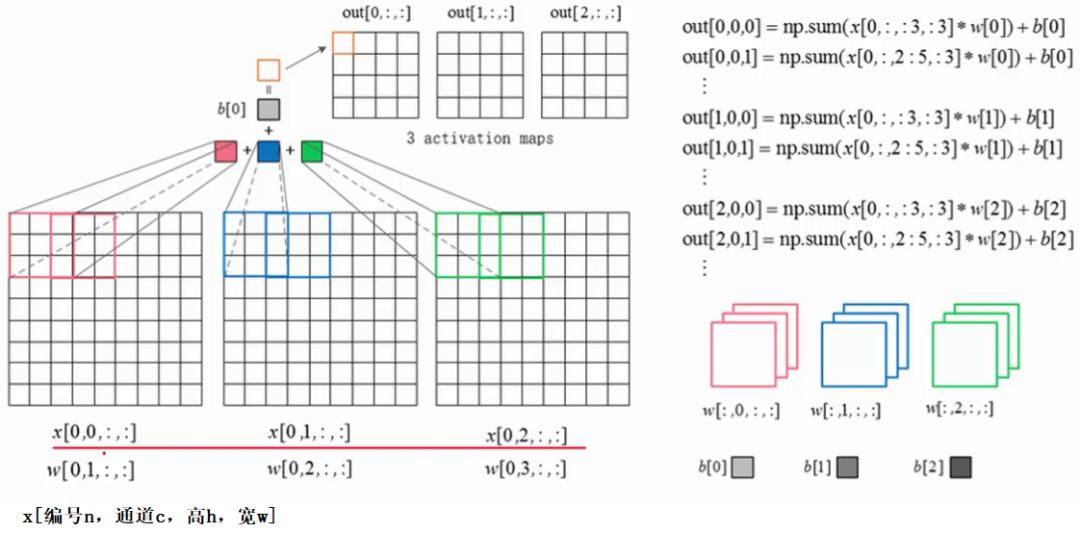
之前已经讲解了卷积层前向传播过程,这里通过一张图再回顾一下:
下面讲解卷积层的反向传播过程:
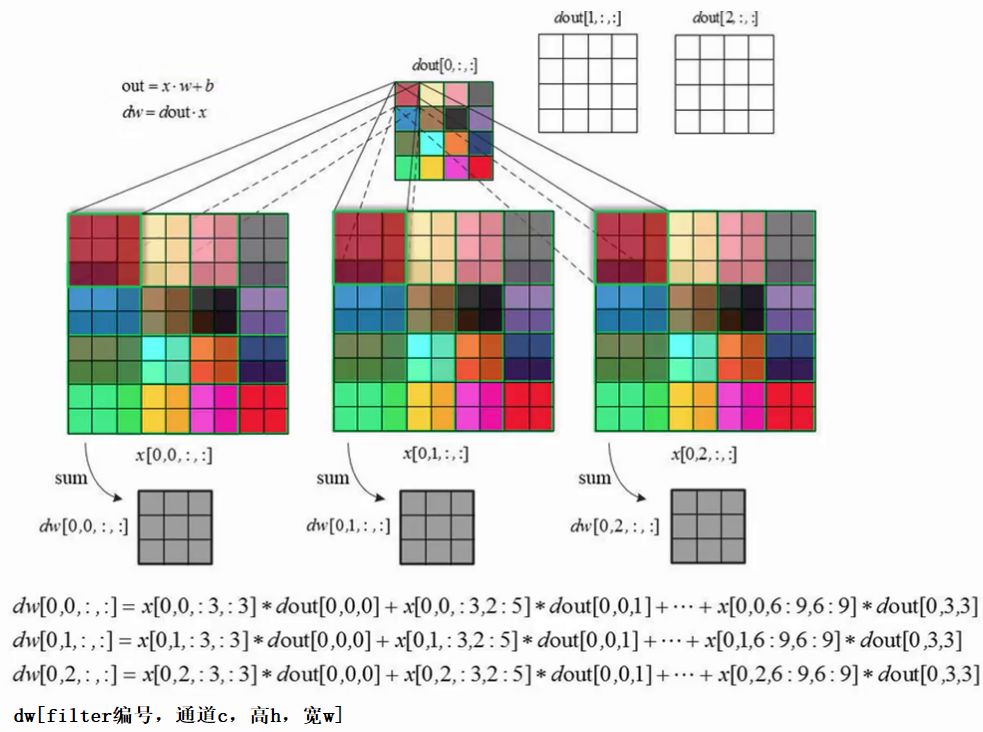
反向传播的目的:更新参数w。因此要先算出dJ/dw。假设上一层会传过来一个梯度dJ/dout,根据链式求导法则,因此dJ/dw = dJ/dout * dout/dw =dJ/dout * x 。在计算机中方便为变量命名的缘故,将dJ/dout记为dout,dJ/dw记为dw,即图中的情况。后面也用这个记号来讲。
首先要清楚:dw 和 w 的尺寸是一样的。一个点乘以一个区域还能得到一个区域。那么反向传播过程就相当于:用dout中的一个元素乘以输入层划窗里的矩阵便得到一个dw矩阵;然后滑动滑窗,继续求下一个dw,依次下去,最后将得到的多个dw相加,执行 w = w - dw 就完成了反向传播的计算。
上面的反向传播可以更新一个filter中的参数,还要求其他的filter。


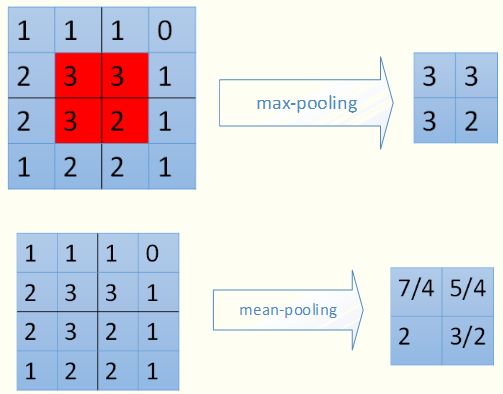
下面用图示来看一下2种不同的pooling过程——池化层的前向传播:
在池化层进行反向传播时,max-pooling和mean-pooling的方式也采用不同的方式。
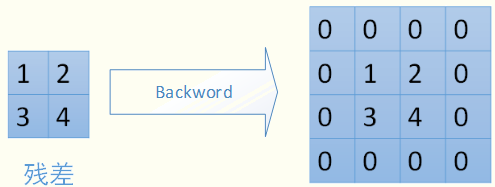
对于max-pooling,在前向计算时,是选取的每个2*2区域中的最大值,这里需要记录下最大值在每个小区域中的位置。在反向传播时,只有那个最大值对下一层有贡献,所以将残差传递到该最大值的位置,区域内其他2*2-1=3个位置置零。具体过程如下图,其中4*4矩阵中非零的位置即为前边计算出来的每个小区域的最大值的位置
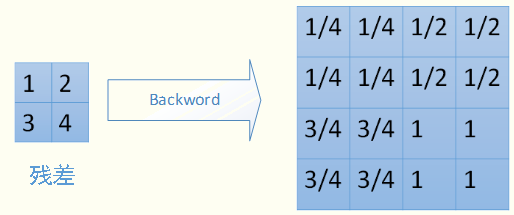
对于mean-pooling,我们需要把残差平均分成2*2=4份,传递到前边小区域的4个单元即可。具体过程如图:
卷积网络架构实例
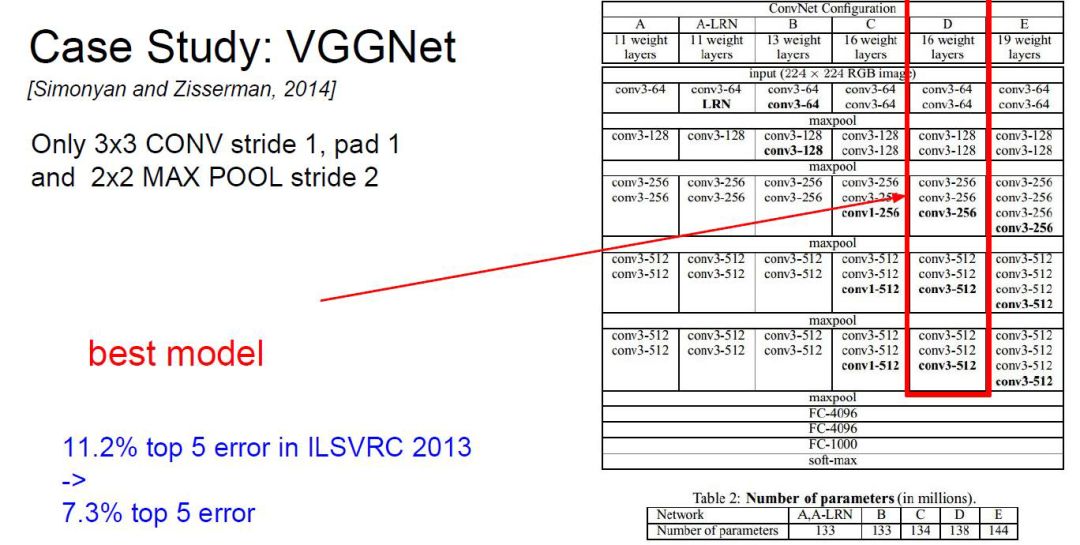
VGGNet深度更多,有很多卷积层和池化层。一个版本有16层,另一个版本有19层(较常用)。
VGGNet的特点:
filter只有3*3的,意味着计算的特征较多,粒度更细。同时pooling的参数也有固定。
注意:传统的卷积神经网络层数越多并以意味着效果更好。而在2016年推出了深度残差网络达到了152层。后续讲介绍。
那么训练一个VGGNet有多少内存开销呢?

从图可得知,训练过程中一张224*224*3的图像会有138M个参数会占93MB的内存。因此每个batch中图像的数目应该受内存的约束,即 93*图像数目<内存总容量。