针对string类型的split()函数。它主要是切割字符串,结果返回由字符串元素组成的一个列表,所以在使用二次切割的时候一定要注意数据类型:
split()方法以及关于str.split()[0]等形式内容的详细讲解
str.split(str="", num=string.count(str)).参数:
- str – 分隔符,默认为所有的空字符,包括空格、换行( )、制表符( )等。
- num – 分割次数。默认为 -1, 即分隔所有。
返回值:
Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
- 返回分割后的字符串列表。
代码示例:
- 输入
str = "Line1-abcdef
Line2-abc
Line4-abcd";
print str.split( ); # 以空格为分隔符,包含
print str.split(' ', 1 ); # 以空格为分隔符,分隔成两个- 输出
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '
Line2-abc
Line4-abcd']关于str.split()[0]等形式内容的详细讲解
代码示例:
- 输入与输出
>>> str="hello boy<[www.doiido.com]>byebye"
>>> str.split("[")[1].split("]")[0]
'www.doiido.com'
>>> str.split("[")[1].split("]")[0].split(".")
['www', 'doiido', 'com']- 解析:
str.split("[")[1]. split("]")[0]输出的是 [ 后的内容以及 ] 前的内容。
str.split("[")[1]. split("]")[0]. split(".") 是先输出 [ 后的内容以及 ] 前的内容,然后通过 . 作为分隔符对字符串进行切片。
下面再对上面的例子进一步操作加深理解:
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[0]得到:‘hell’
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[1]得到:’ b’(这里b的前面有个空格!)
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[3]得到:‘iid’(这里得到的iid是第3个o后和第4个o前之间的内容)
str="hello boy<[www.doiido.com]>byebye"
str.split("[")[0]
- 得到:‘hello boy<’(这里得到的hello boy<是第一个[之前的内容)
- 解析:
str.split(“o”)[0]得到的是第一个o之前的内容
str.split(“o”)[1]得到的是第一个o和第二个o之间的内容
str.split(“o”)[3]得到的是第三个o后和第四个o前之间的内容
str.split("[")[0]得到的是第一个 [ 之前的内容
注意:[ ]内的数值必须小于等于split("")内分隔符的个数,否则会报错,报错内容如下:
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[6]IndexError Traceback (most recent call last)
<ipython-input-15-50d5956c7ce9> in <module>()
1 str="hello boy<[www.doiido.com]>byebye"
----> 2 str.split("o")[6]
IndexError: list index out of range如有错误内容请积极批评指正!感谢!
参考内容:
http://www.runoob.com/python/att-string-split.html
http://www.cnblogs.com/douzi2/p/5579651.html
如果在运行python脚本时需要传入一些参数,例如gpus与batch_size,可以使用如下三种方式。
python script.py 0,1,2 10 python script.py -gpus=0,1,2 --batch-size=10 python script.py -gpus=0,1,2 --batch_size=10
这三种格式对应不同的参数解析方式,分别为sys.argv、argparse、 tf.app.run, 前两者是python自带的功能,后者是tensorflow提供的便捷方式。
1.sys.argv
sys模块是很常用的模块, 它封装了与python解释器相关的数据,例如sys.modules里面有已经加载了的所有模块信息,sys.path里面是PYTHONPATH的内容,而sys.argv则封装了传入的参数数据。使用
sys.argv接收上面第一个命令中包含的参数方式如下:import sys
gpus = sys.argv[1]
#gpus = [int(gpus.split(','))]
batch_size = sys.argv[2]
print(gpus)
print(batch_size)

2.argparse

import argparse
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument("--gpus", type=str, default="0")
parser.add_argument("--batch-size", type=int, default=32)
args = parser.parse_args()
print(args.gpus)
print(args.batch_size)
python script.py -gpus=0,1,2 --batch-size=10中的--batch-size会被自动解析成batch_size.parser.add_argument 方法的type参数理论上可以是任何合法的类型, 但有些参数传入格式比较麻烦,例如list,所以一般使用bool, int, str, float这些基本类型就行了,更复杂的需求可以通过str传入,然后手动解析。bool类型的解析比较特殊,传入任何值都会被解析成True,传入空值时才为False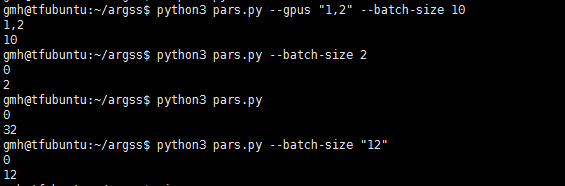
3.tf.app.run
import tensorflow as tf
tf.app.flags.DEFINE_string('gpus', None, 'gpus to use')
tf.app.flags.DEFINE_integer('batch_size', 5, 'batch size')
FLAGS = tf.app.flags.FLAGS
def main(_):
print(FLAGS.gpus)
print(FLAGS.batch_size)
if __name__=="__main__":
tf.app.run()
有几点需要注意:
tensorflow只提供以下几种方法:
tf.app.flags.DEFINE_string,tf.app.flags.DEFINE_integer,tf.app.flags.DEFINE_boolean,tf.app.flags.DEFINE_float 四种方法,分别对应str, int,bool,float类型的参数。这里对bool的解析比较严格,传入1会被解析成True,其余任何值都会被解析成False。
脚本中需要定义一个接收一个参数的main方法:def main(_):,这个传入的参数是脚本名,一般用不到, 所以用下划线接收。
以batch_size参数为例,传入这个参数时使用的名称为--batch_size,也就是说,中划线不会像在argparse 中一样被解析成下划线。
tf.app.run()会寻找并执行入口脚本的main方法。也只有在执行了tf.app.run()之后才能从FLAGS中取出参数。
从它的签名来看,它也是可以自己指定需要执行的方法的,不一定非得叫main:
