1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待当前URL抓取完毕之后在进行下一个URL的抓取,抓取效率可以提高很多。
2. Scrapy-redis:虽然Scrapy框架是异步加多线程的,但是我们只能在一台主机上运行,爬取效率还是有限的,Scrapy-redis库为我们提供了Scrapy分布式的队列,调度器,去重等等功能,有了它,我们就可以将多台主机组合起来,共同完成一个爬取任务,抓取的效率又提高了。
3. Scrapyd:分布式爬虫完成之后,接下来就是代码部署,如果我们有很多主机,那就要逐个登录服务器进行部署,万一代码有所改动..........可以想象,这个过程是多么繁琐。Scrapyd是专门用来进行分布式部署的工具,它提供HTTP接口来帮助我们部署,启动,停止,删除爬虫程序,利用它我们可以很方便的完成Scrapy爬虫项目的部署。
4. Gerapy:是一个基于Scrapyd,Scrapyd API,Django,Vue.js搭建的分布式爬虫管理框架。简单点说,就是用上述的Scrapyd工具是在命令行进行操作,而Gerapy将命令行和图形界面进行了对接,我们只需要点击按钮就可完成部署,启动,停止,删除的操作。
Gerapy的操作
本次操作是基于,
1.开启Gerapy 服务,前提是已经安装好了,Gerapy ,安装方法见:
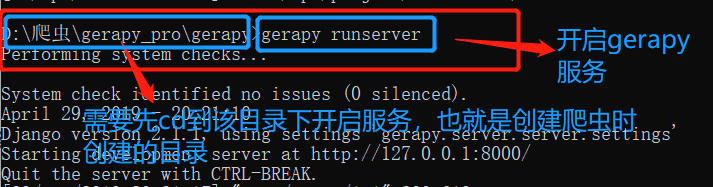
2. 远程的scrapyd 需要开启了服务
主机管理
添加我们需要管理的 Scrapyd 服务:
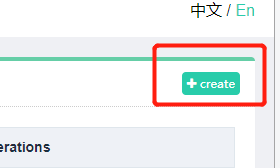
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表
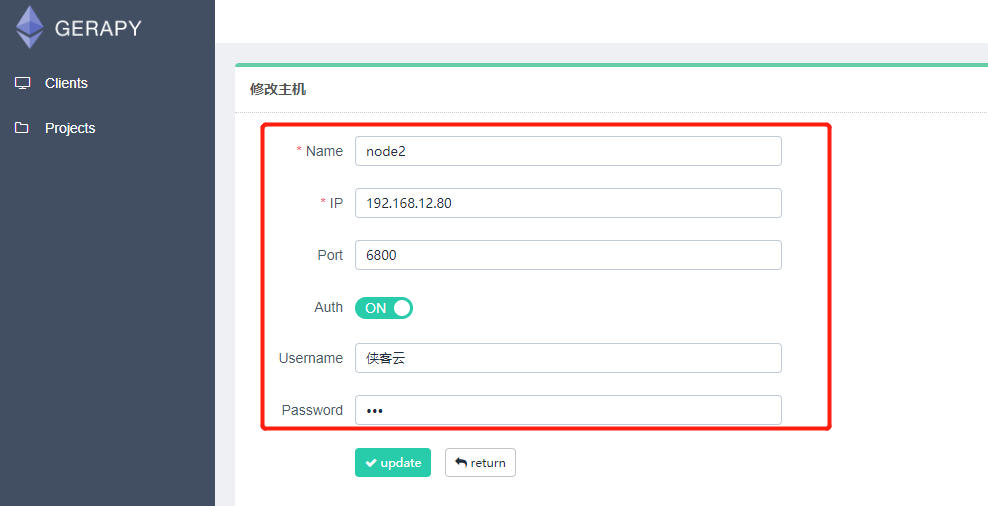
状态一栏看到各个 Scrapyd 服务是否可用,同时可以一目了然当前所有 Scrapyd 服务列表,另外我们还可以自由地进行编辑和删除。
如果显示不正常或者错误

要改一下scrapyd配置*Libsite-packagesscrapyd中的default_scrapyd.conf:
将bind_address = 127.0.0.1改为bind_address = 0.0.0.0
项目管理
Gerapy 的核心功能当然是项目管理,在这里我们可以自由地配置、编辑、部署我们的 Scrapy 项目,点击左侧的 Projects 。
假设现在我们有一个 Scrapy 项目,如果我们想要进行管理和部署,还记得初始化过程中提到的 projects 文件夹吗?
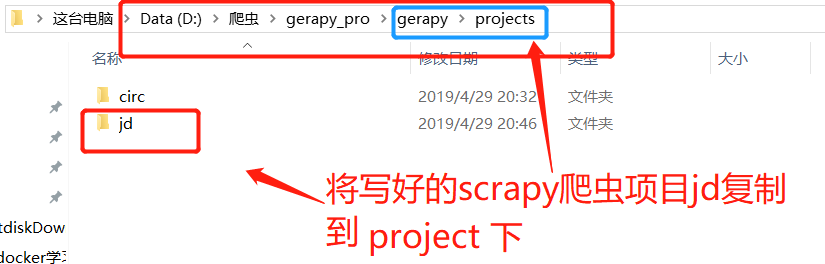
这时我们只需要将项目拖动到刚才 gerapy 运行目录的 projects 文件夹下,例如我这里写好了一个 Scrapy 项目,名字叫做 jd,这时把它拖动到 projects 文件夹下:
这时刷新页面,我们便可以看到 Gerapy 检测到了这个项目,同时它是不可配置、没有打包的:
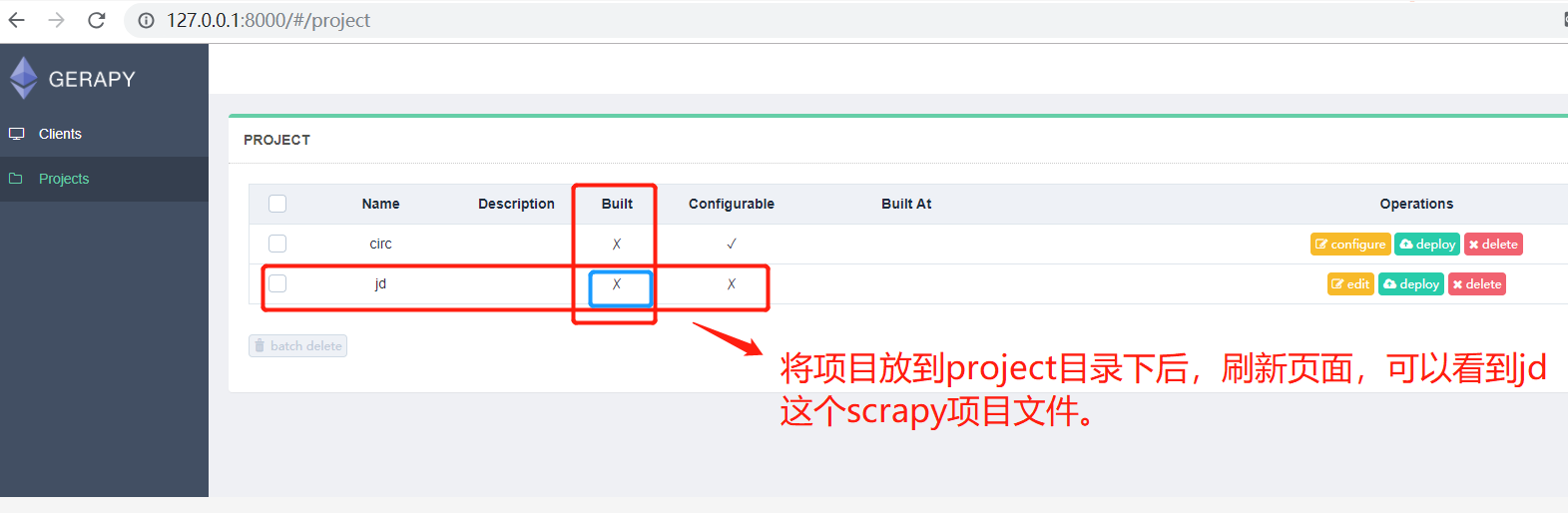
这时我们可以点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称:
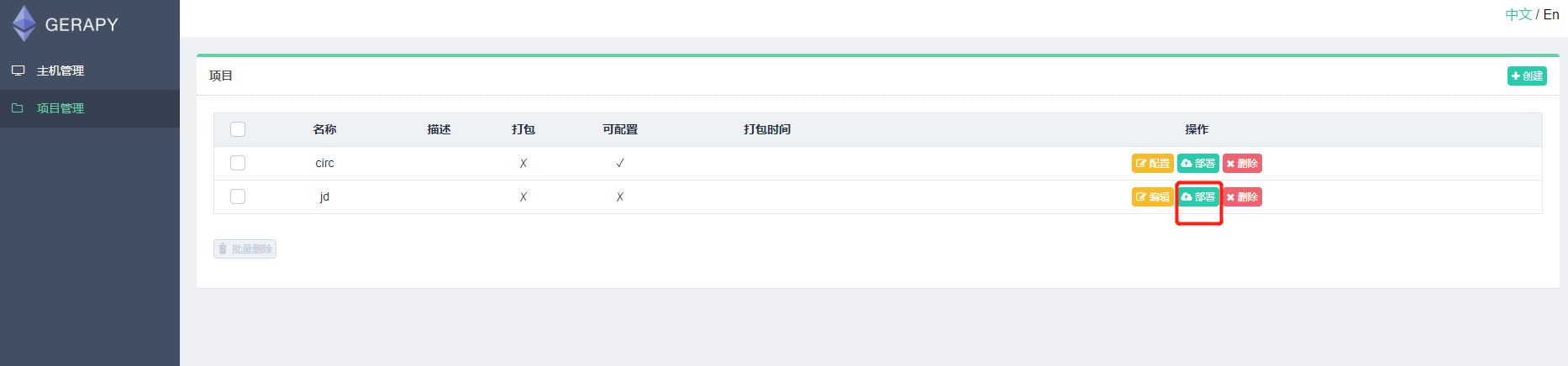
填写描述:
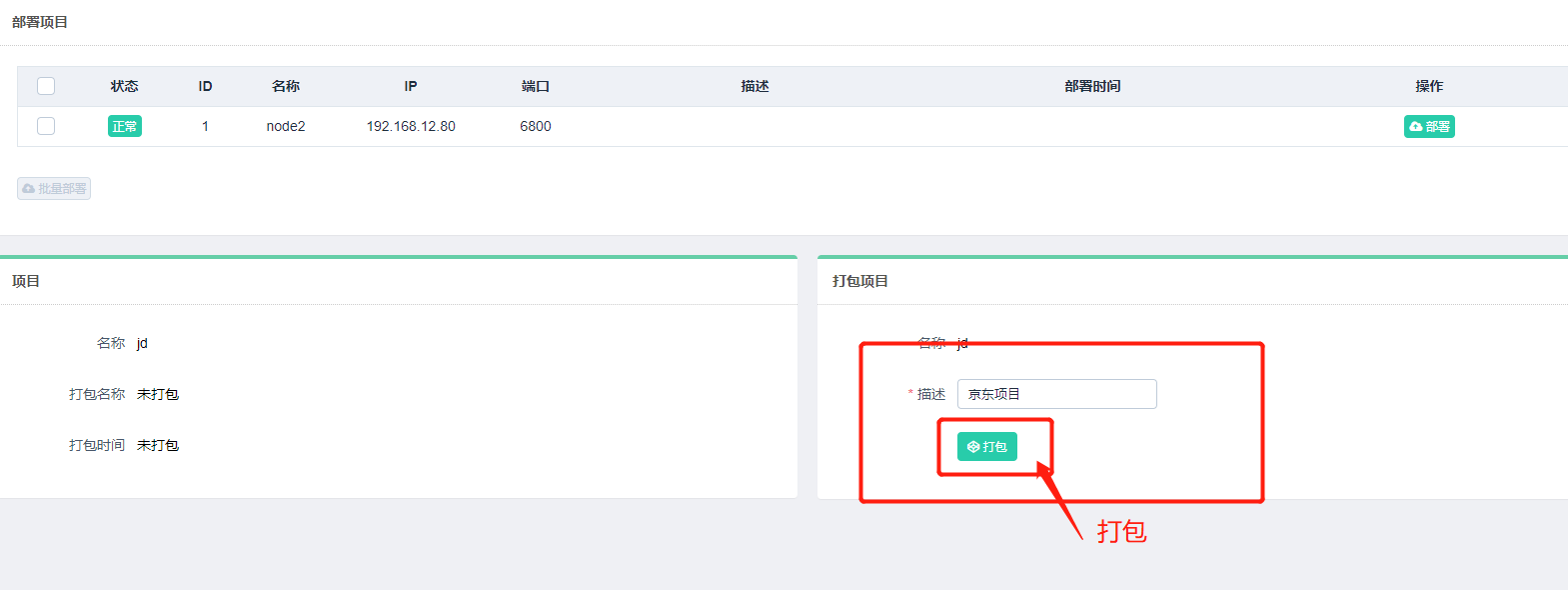
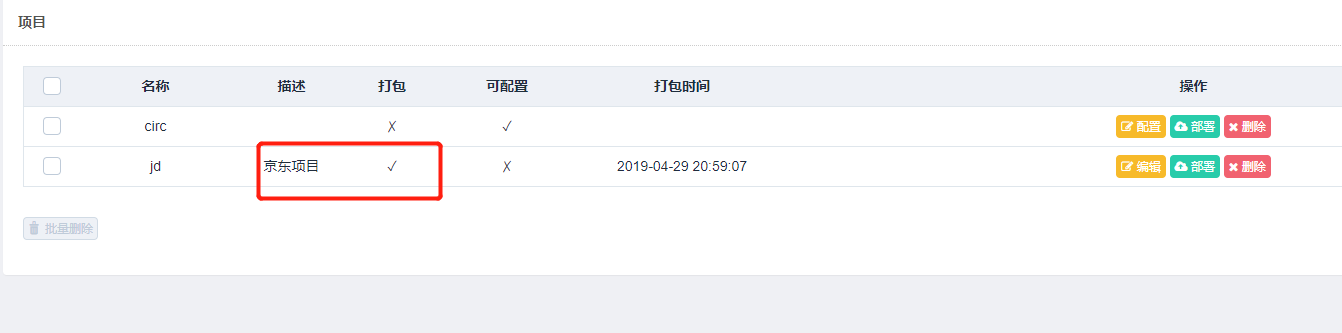
打包成功之后,我们便可以进行部署了,我们可以选择需要部署的主机,点击后方的部署按钮进行部署,同时也可以批量选择主机进行部署,示例如下:
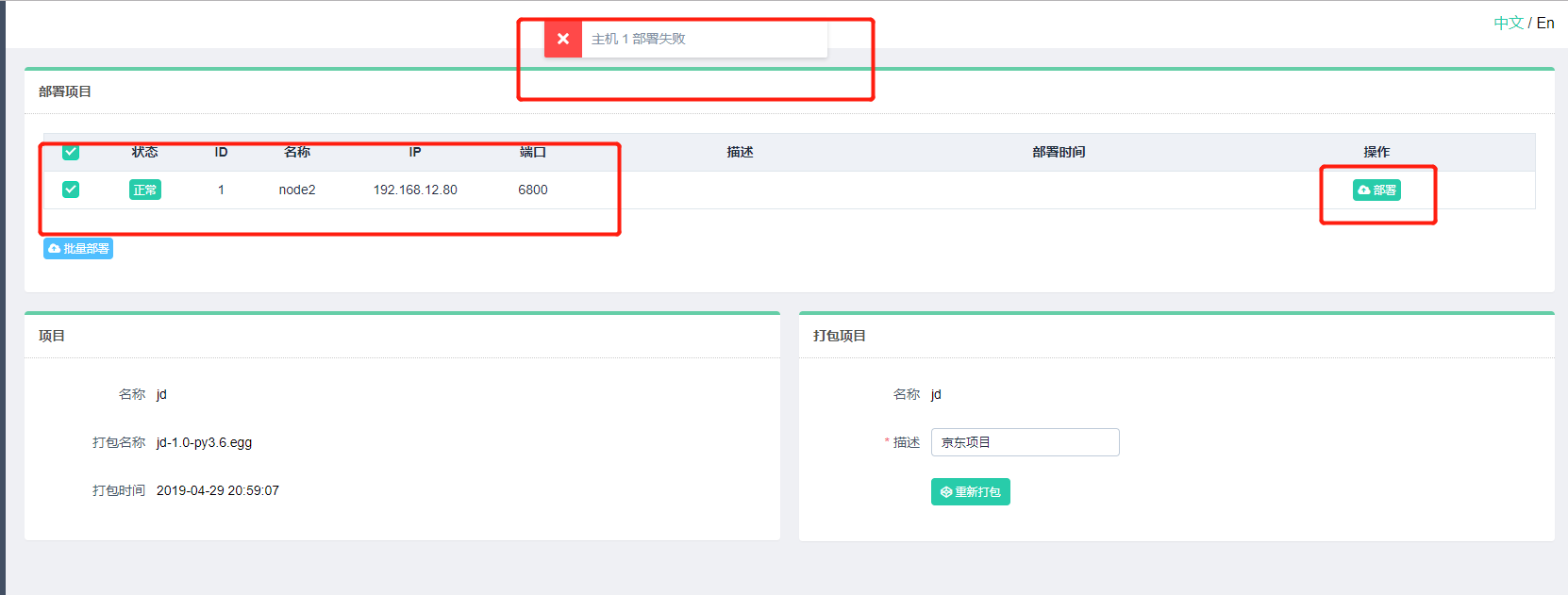
上面部署失败的原因,可能是 scrapy 京东项目文件夹中的配置文件没有,绑定该远程服务器,
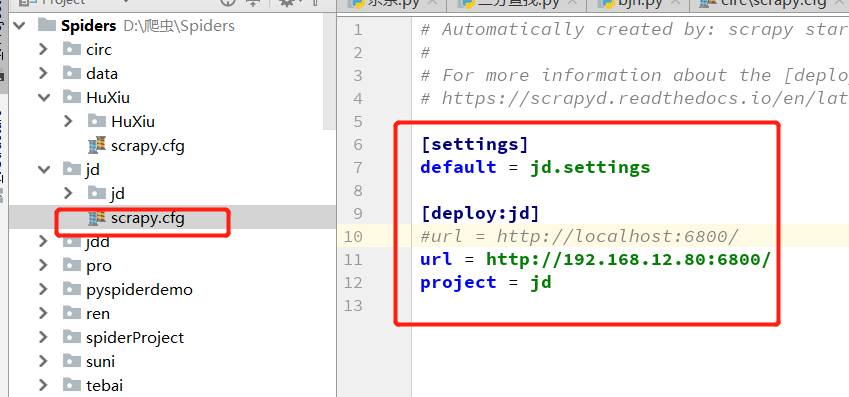
下面是网上的部署成功的案例:
打包成功之后,我们便可以进行部署了,我们可以选择需要部署的主机,点击后方的部署按钮进行部署,同时也可以批量选择主机进行部署,示例如下:

可以发现此方法相比 Scrapyd-Client 的命令行式部署,简直不能方便更多。
监控任务
部署完毕之后就可以回到主机管理页面进行任务调度了,任选一台主机,点击调度按钮即可进入任务管理页面,此页面可以查看当前 Scrapyd 服务的所有项目、所有爬虫及运行状态:

我们可以通过点击新任务、停止等按钮来实现任务的启动和停止等操作,同时也可以通过展开任务条目查看日志详情:

另外我们还可以随时点击停止按钮来取消 Scrapy 任务的运行。
这样我们就可以在此页面方便地管理每个 Scrapyd 服务上的 每个 Scrapy 项目的运行了。
项目编辑
同时 Gerapy 还支持项目编辑功能,有了它我们不再需要 IDE 即可完成项目的编写,我们点击项目的编辑按钮即可进入到编辑页面,如图所示:

这样即使 Gerapy 部署在远程的服务器上,我们不方便用 IDE 打开,也不喜欢用 Vim 等编辑软件,我们可以借助于本功能方便地完成代码的编写。
代码生成
上述的项目主要针对的是我们已经写好的 Scrapy 项目,我们可以借助于 Gerapy 方便地完成编辑、部署、控制、监测等功能,而且这些项目的一些逻辑、配置都是已经写死在代码里面的,如果要修改的话,需要直接修改代码,即这些项目都是不可配置的。
在 Scrapy 中,其实提供了一个可配置化的爬虫 CrawlSpider,它可以利用一些规则来完成爬取规则和解析规则的配置,这样可配置化程度就非常高,这样我们只需要维护爬取规则、提取逻辑就可以了。如果要新增一个爬虫,我们只需要写好对应的规则即可,这类爬虫就叫做可配置化爬虫。
Gerapy 可以做到:我们写好爬虫规则,它帮我们自动生成 Scrapy 项目代码。
我们可以点击项目页面的右上角的创建按钮,增加一个可配置化爬虫,接着我们便可以在此处添加提取实体、爬取规则、抽取规则了,例如这里的解析器,我们可以配置解析成为哪个实体,每个字段使用怎样的解析方式,如 XPath 或 CSS 解析器、直接获取属性、直接添加值等多重方式,另外还可以指定处理器进行数据清洗,或直接指定正则表达式进行解析等等,通过这些流程我们可以做到任何字段的解析。
再比如爬取规则,我们可以指定从哪个链接开始爬取,允许爬取的域名是什么,该链接提取哪些跟进的链接,用什么解析方法来处理等等配置。通过这些配置,我们可以完成爬取规则的设置。
最后点击生成按钮即可完成代码的生成。
生成的代码示例结果其结构和 Scrapy 代码是完全一致的。

生成代码之后,我们只需要像上述流程一样,把项目进行部署、启动就好了,不需要我们写任何一行代码,即可完成爬虫的编写、部署、控制、监测。