#一.基础数据类型补充
#1.dict.fromkeys())
# ret=dict.fromkeys([1,2,3],"value")#创建一个新字典,而不是修改原字典,返回的是一个字典
# print(ret)
# dic=dict()
# dic.fromkeys([1,2,3],"value")
# print(dic)
#formkeys
#创建一个新字典,而不是修改原字典,返回的是一个字典
#value 值共用同一个内存地址
ret=dict.fromkeys(["a","b","c"],[1,2,3])
print(ret) #{'a': [1, 2, 3], 'b': [1, 2, 3], 'c': [1, 2, 3]}
ret["a"].append("f")
print(ret) #{'a': [1, 2, 3, 'f'], 'b': [1, 2, 3, 'f'], 'c': [1, 2, 3, 'f']}
#集合
#1.不重复,去重功能
#2.元素的数据类型必须可哈希,不能是可变数据类型
li=["周杰伦","周杰伦","周杰伦",1,2,3,4,6,3]
#去重用法
li1=list(set(li))
print(li1) #[1, 2, 3, 4, 6, '周杰伦']
# 集合的增删改查
se={1,2,3,"alex"}
#1.增
se.add("deng")
print(se) #{'alex', 1, 2, 3, 'deng'}
se.update(["a","b"])
print(se) #{1, 'deng', 2, 3, 'a', 'b', 'alex'}
#2.删
s = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}
# s.pop() #随机删除
# # print(s)
# s.remove("王祖贤")
# print(s) #{'关之琳', '张曼⽟', '刘嘉玲'}
# s.clear() #清空
# print(s)
#3.改 思路:先删除,后添加
# s.remove('关之琳')
# s.add("李德华")
# print(s) #{'李德华', '张曼⽟', '刘嘉玲', '王祖贤', '李若彤'}
#4.查 for 循环
for i in s:
print(i)
#frozenset
s = {"刘嘉玲", '关之琳', "王祖贤", "张曼⽟", "李若彤"}
s=frozenset({1,2,3}) #变成了可哈希
print(s)
print({s:"q"}) #可以做key了
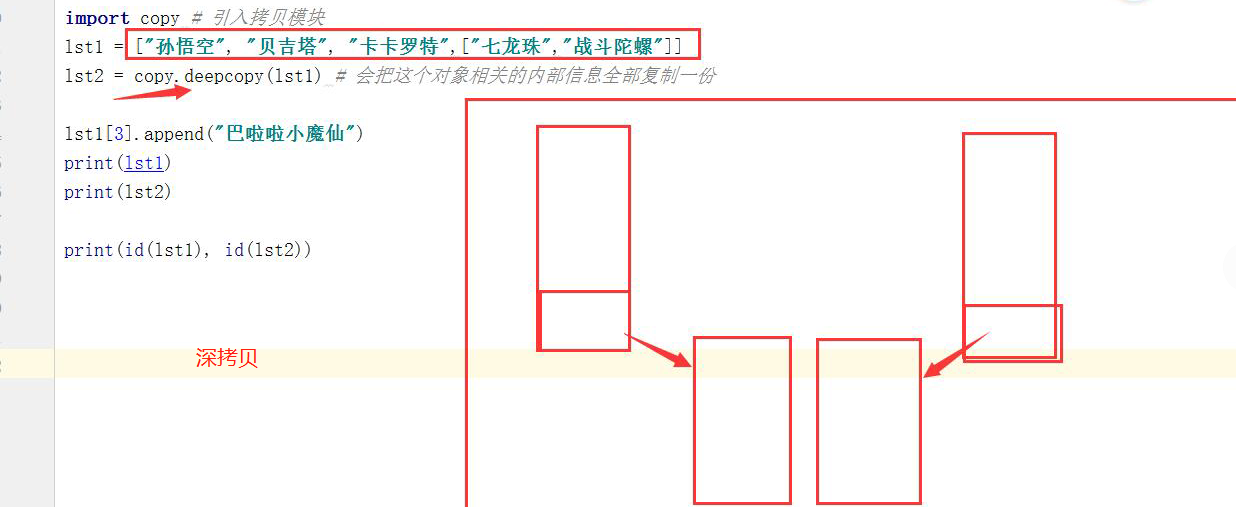
#深浅拷贝
#1.赋值 = list2=list1
#= 没有产生新对象。 都是内存地址的赋值
#list1的内存指向和list2是⼀样的
list1=[1,2,3]
list2=list1
list2.append(1)
print(list1) #[1, 2, 3, 1]
print(list2) #[1, 2, 3, 1]
#截取会创建新的对象
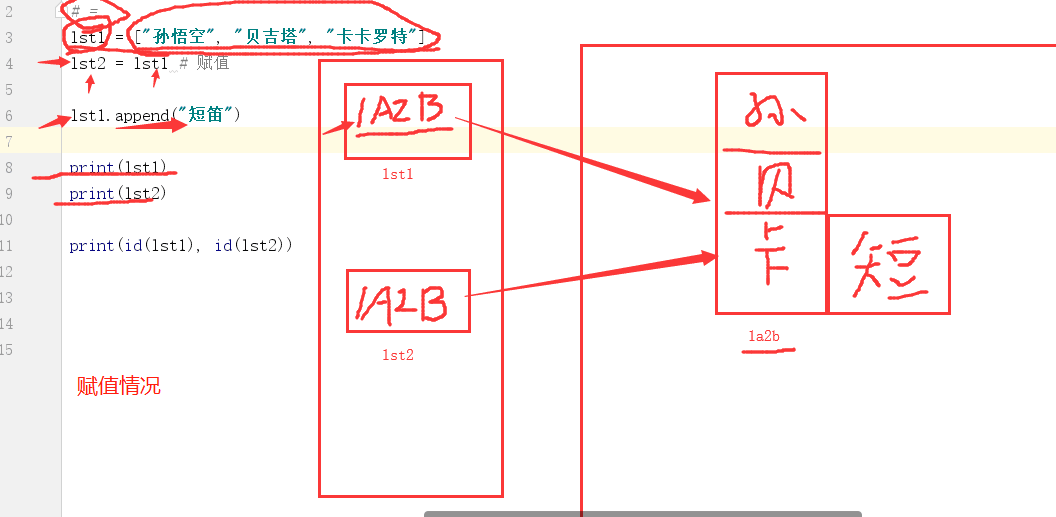
lst1 = ["孙悟空", "贝吉塔", "卡卡罗特"]
lst2 = lst1[:] # [:] 在原来的数据中获取到所有的数据组成新的列表
lst1.append("短笛")
print(lst1) #['孙悟空', '贝吉塔', '卡卡罗特', '短笛']
print(lst2)#['孙悟空', '贝吉塔', '卡卡罗特']
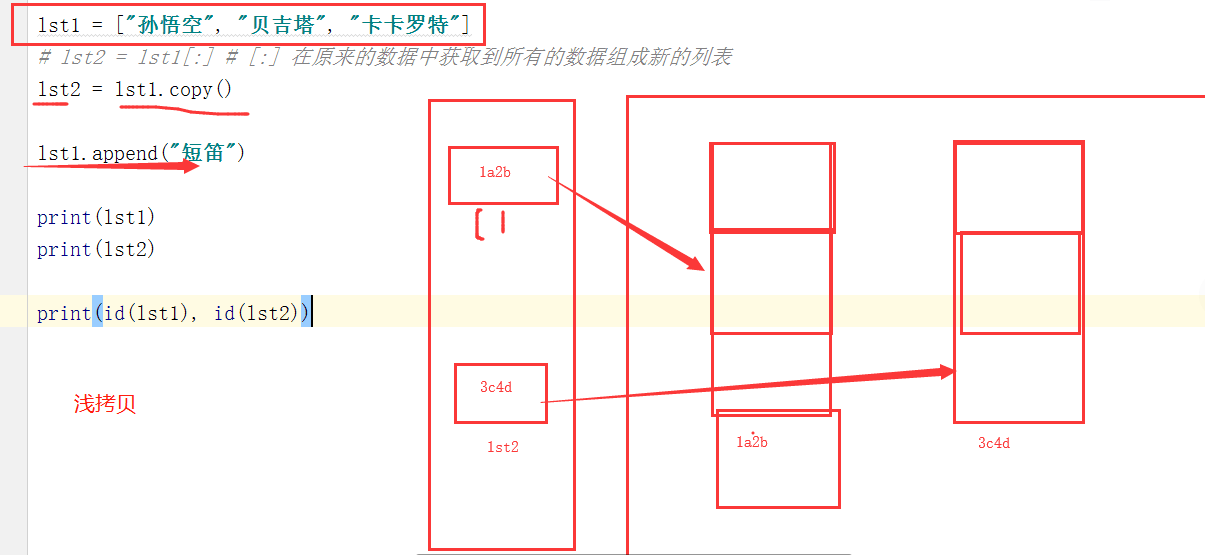
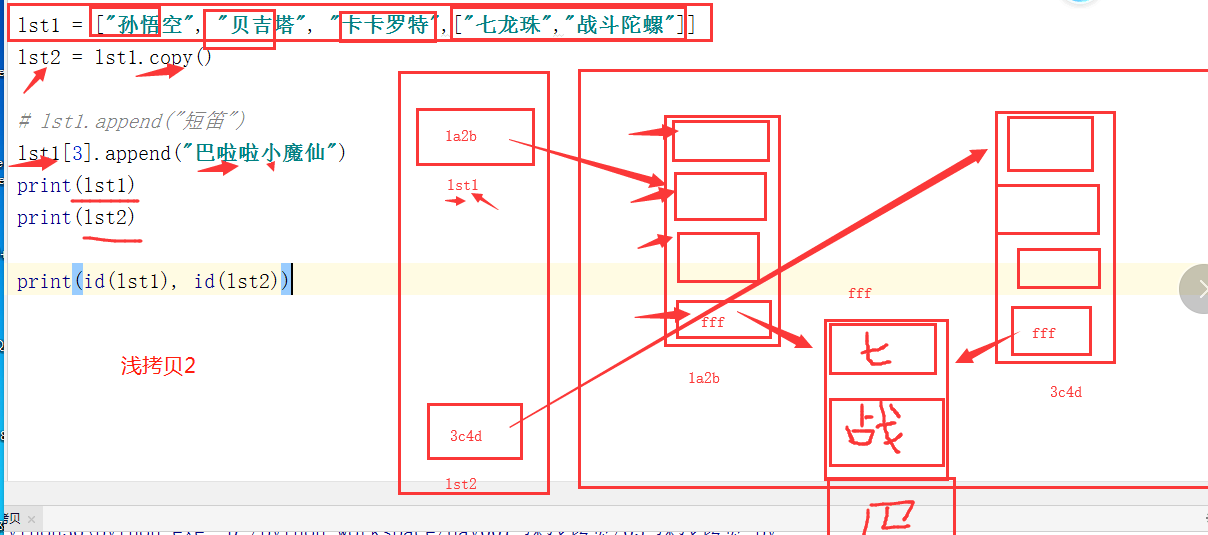
#2.浅拷贝 lst1.copy()
#浅拷贝 第一层内存地址不一样
# 两个lst完全不⼀样. 内存地址和内容也不⼀样. 发现实现了内存的拷⻉
# 只会拷⻉第⼀层.第⼆层的内容不会拷⻉.所以被称为浅拷⻉
# 优点: 省内存.
# 缺点: 容易出现同一个对象被多个变量所引用
lst1 = ["何炅", "杜海涛","周渝⺠"]
lst2=lst1.copy()
lst2.append("a")
print(lst1) #['何炅', '杜海涛', '周渝⺠']
print(lst2) #['何炅', '杜海涛', '周渝⺠', 'a']