优化点:合理的使用索引,可以大幅度提升sql查询效率,特别查询的表的数据量大的时候,效果明显。一.引言
公司的产品XX出行上线正式运营,随着数据量的变大,司机2000+,日订单1万+,注册乘客26W+,MySql的一些语句查询效率低下,严重的达到10秒级别以上,严重的影响系统服务。故公司安排我负责数据库方面的工作。(吐槽,公司不是很大,但是DBA都没,java是全能的,啥都要搞一搞)
二.分析
从网上寻找到的资源,可以分成1)业务层面逻辑优化;2)业务层面数据结构优化;3)Sql语句优化。下面实例均来自该项目实际运营中出现的。
1)业务层面逻辑优化
案例:司机发送消息接口,接口实现逻辑:后台创建一条司机信息-》推送给司机端-》司机端主动拉取获取消息接口-》内部实现(需优化)-》返回接口信息给司机端。内部实现代码如下:
/*
遍历表yy_common_driver_message,根据条件取的全部的msgId(1)
遍历表yy_common_message_status,根据条件取得已发送的msgId;(2)
将未发送的msg(1-2),新增到表yy_common_message_status
*/
Map<String,Object> map = new HashMap<String,Object>();
map.put("targetUuid", params.get("targetUuid"));
List<String> existsList = getMsgUuids(map);
AjaxList ajaxList = commonDriverMessageService.getUuids(params);
if(ajaxList.isSuccess()){
List<String> allList = (List<String>) ajaxList.getData();
List<CommonMessageStatusDto> list = new ArrayList<CommonMessageStatusDto>();
for(String uuid : allList){
if(!existsList.contains(uuid)){
//如果id不包含在已发送,表yy_common_message_status插入新数据
CommonMessageStatusDto dto = new CommonMessageStatusDto();
dto.setUuid(StringUtil.buildUUID());
dto.setMessageUuid(uuid);//msgId
dto.setTargetUuid(params.get("targetUuid").toString());
dto.setStatus(CommonMessageStatusDto.STATUS_UNREAD);//未读
dto.setType(CommonMessageStatusDto.TYPE_SYSTEM);//系统消息
dto.setBusinessType(new Integer(params.get("businessType").toString()));
dto.setTargetType(CommonMessageStatusDto.TARGET_TYPE_DRIVER);//司机
dto.setAppid(params.get("appid").toString());
list.add(dto);
}
}
if(list.size()>0){//如果有。则新增
commonMessageStatusMapper.addBatch(list);
}
}
初心的设计是为了司机端调用接口的时候,才生产中间表yy_common_message_status的数据,但是由于需求变更,需要主动批量推送给司机,变相是主动触发司机调用接口。这时候,这个设计就不合适了。客户在使用的时候,用车高峰期的时候,主动发送司机消息给所有的司机,司机端收到推送的时候,会主动调用该接口,导致系统查询缓慢。根据讨论结果,内部实现修改为在新增司机消息的时候,新建一个线程,批量插入中间表记录,司机端调用接口的时候,只需要直接执行中间表-消息表的sql语句。优化点:减少数据库交互次数。
2)业务层面数据结构优化
软件使用的乘客数不断上升,26W+,一些查询乘客表的sql语句,查询缓慢。Sql语句:SELECT * from yy_passenger where mobile = '15822230119',耗费时间0.66s,查看Mysql执行计划:
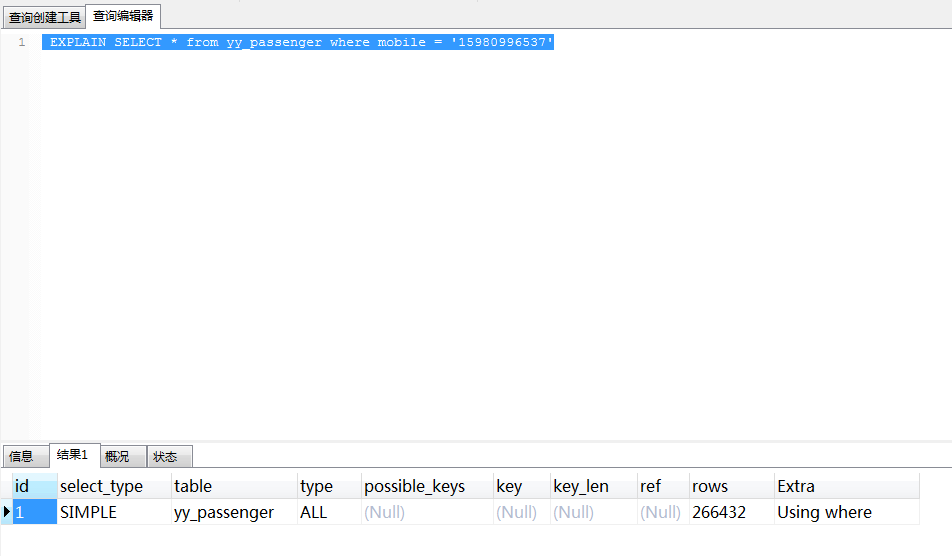
根据查询条件,创建索引,使用索引后,执行SQL查询,耗时0.047s,查看执行计划:
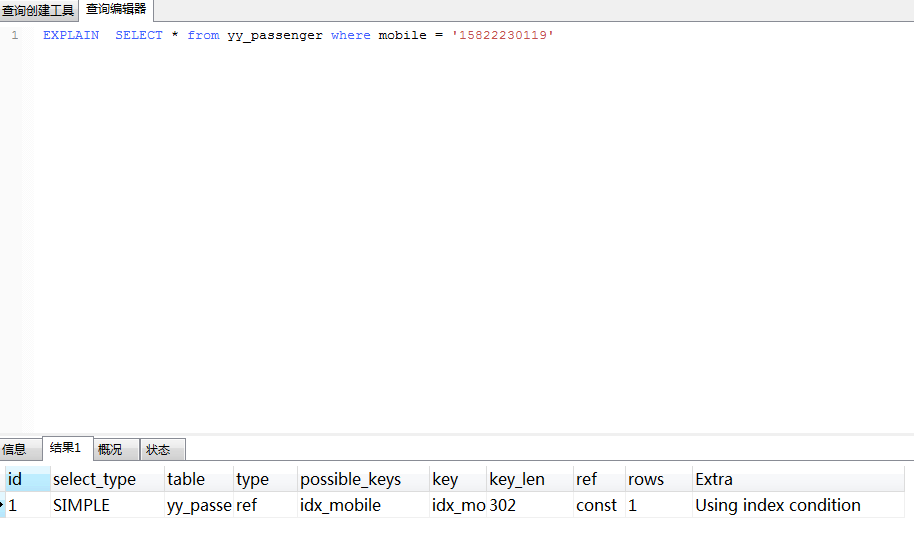
优化点:合理的使用索引,可以大幅度提升sql查询效率,特别查询的表的数据量大的时候,效果明显。
3)Sql语句优化
可以参考链接:http://blog.csdn.net/jie_liang/article/details/77340905,写sql的时候需要注意的,目前就举一例子,营运上遇到的。如下一段mybatis代码
<select id="getTodayDriverMonitorList" resultType="driverMonitorListBean">
select d1.uuid driverUuid,
d1.type,
d1.mobile,
d1.name,
d1.plate_num plateNum,
d1.isWork,
d1.minTime,
d1.maxTime,
d1.timeSum,
count(o.uuid) orderCount,
sum(f.order_fare) fareSum,
sum(f.trip_distance) distanceSum
from (
select d.uuid,d.type,d.mobile,d.name,d.is_work isWork,c.plate_num,min(l.onWork_time) minTime,max(l.onWork_time) maxTime,sum((TIME_TO_SEC(IFNULL(offWork_time,now())) - TIME_TO_SEC(onWork_time))) timeSum
from yy_driver d
inner join yy_driver_sign_log l on d.uuid = l.driver_uuid and l.workday = date_format(now(),'%Y-%m-%d')
inner join yy_car c on c.uuid = d.car_uuid
where 1=1
<if test="business != 99 and business !=null">AND d.type = #{business}</if>
group by d.uuid,d.mobile,d.name,c.plate_num,d.type,d.is_work
) d1
<strong> left join (SELECT uuid,actual_driver_uuid FROM yy_order where create_time >= curdate() and create_time lt; date_add(curdate(), interval 1 day))o ON o.actual_driver_uuid = d1.uuid
</strong> left join yy_order_fare f on o.uuid = f.order_uuid
group by d1.uuid,d1.type,d1.mobile,d1.name,d1.plate_num,d1.minTime,d1.maxTime,d1.timeSum
</select>
修改后,执行时间0.52s。
优化点:SQL语句根据实际情况进行优化。
三.结尾
经过这次的SQL管理工作,对SQL优化有一个比较浅的涉及,个人的认为业务逻辑的实现和表结构的设计是顶层设计,而sql语句的优化是在此的基础上。常用的优化方法:索引的创建和分表方式(未涉及,只听说),而索引的创建在合理性,数据库中以空间换时间来实现,SQL语句的查询要避免一些语法导致无法引用索引,而且要根据实际的情况使用好子查询,避免使用全字段查询。