无意中发现网上的一个数据分析R应用教程,看了几集感觉还不错,本文做一个学习笔记(知识点来源:视频内容+R实战+自己的理解),视频详细的信息请参考http://www.itao521.com/course/34,非常不错的网站,站长的Q群是323370861(这个群的童鞋们都很给力,学习也很上进,各种团购买hadoop,nosql,spark的视频学习),我网站会员ID是515,也欢迎各方朋友交流,OK,开始
统计的一些基础概念,如下图所示,

























数据分析常用到的一些算法(下图貌似是Spss modeler里面的缩略图),常用的聚类,分类,维度归约,回归预测,时间序列算法都有
一、基本操作
创建向量和矩阵(我以前的博客里面写过R相关的基本入门,感兴趣的请移步http://www.cnblogs.com/kobedeshow/p/3339760.html)
计算平均,和,最小值,最大值,方差,标准差,练乘
帮助函数
例如 min 这个函数 我不知道什么意思,那么可以help(min)或者?min
产生向量
1:10*2+1等价于(1:10)*2+1,R编程的一个最基本的特点是向量化编程,不能套用C或JAVA语言里面的迭代思想,否则写出来的程序性能很差
a[-5] 相当于就第五个元素不显示,其他都显示
a[-(1:3)]相当于就第1,2,3个元素不显示,其他都显示
a[a<20] 首先a<20 会判断每个元素是否<20,是就是true,否就是flase,返回这样的向量index,,最后显示a[index]
seq函数 seq(5,20)从5开始到20,默认步长是1,by=2步长为2
which函数 ,返回元素下标
matrix()函数,默认是按列存储,参数byrow=T设置按行存储
矩阵转置函数t()、加减操作
矩阵相乘,注意是a%*%b,如果a*b这表示两个矩阵的对应元素相乘
矩阵求逆--solve() rnorm(16) 是返回16个符合正态分布的随机数(默认均值=0,方差=1)
线性方程组求解--solve(a,b) 形如 a*X=b
特征值跟特征向量 eigen() A*特征向量矩阵=特征值矩阵*特征向量矩阵
向量,矩阵,数组,向量一维,矩阵二维,数组多维,这三种结构必须要同一类型的元素(字符,数字,逻辑),如果要包含多种类型元素请使用数据框(很强大的东东,python里面的数据分析报pandas就是使用了这种数据结构)
数据框
文件读取,head=T表示读取头文件,数据读取可以安装ODBC包等
循环语句
for循环
while循环
概率分布函数,具体的参数可以help(*)
二、图形操作
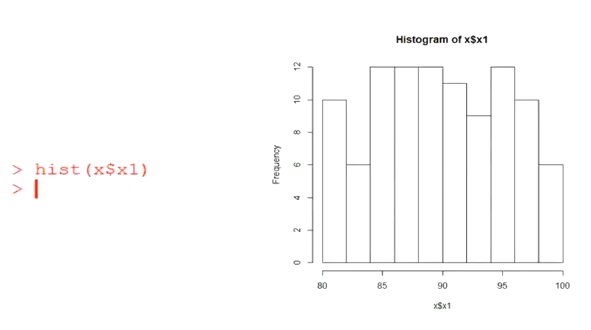
直方图
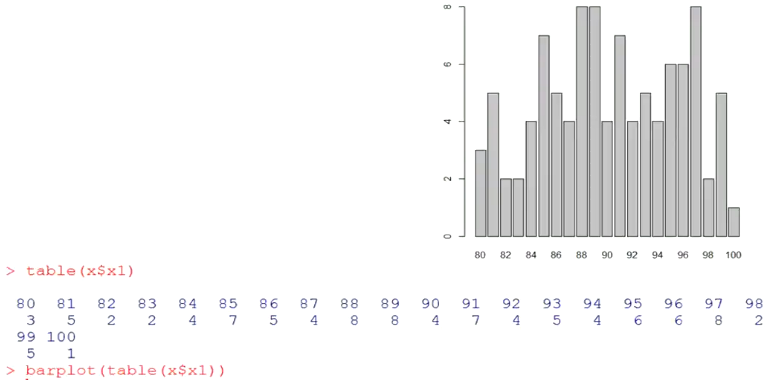
列联表分析(列联函数table())
散点图(变量间的相关性,类似线性回归里面,画残差散点图)
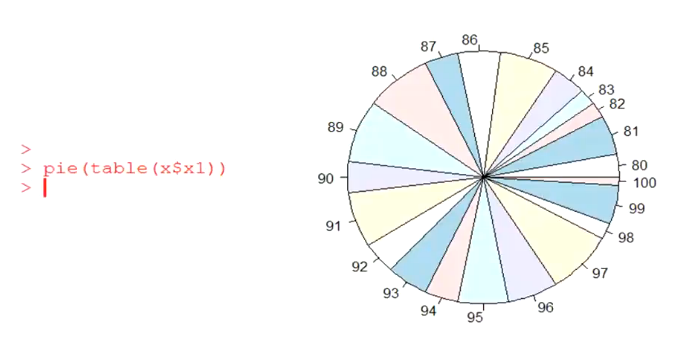
饼图
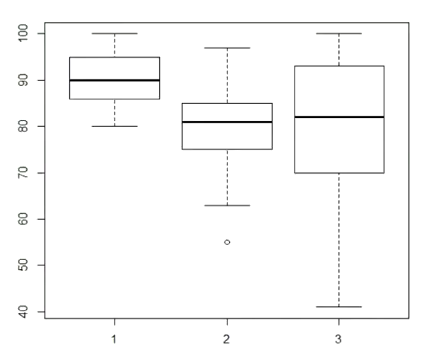
箱线图(经常会用到,可以看出数据的散度,是否稳定),箱子的上线跟下线表示第一,三个四分位数,最两端的直线等于(第一个四分位+最小值)/2和(第三个四分位+最大值)/2(不知道有没有记错),外面的小圆圈表示异常值
boxplot(x1,x2,x3)
星相图(对每个样本画一个星状,几条线代表样本有几个属性,线的长短代表值的大小)
stars(x1,x2,x3)
脸谱图(用处不是很大,适合小样本,看都看累了,呵呵)
茎叶图(下面表示,有61,64,65,66,。。。)
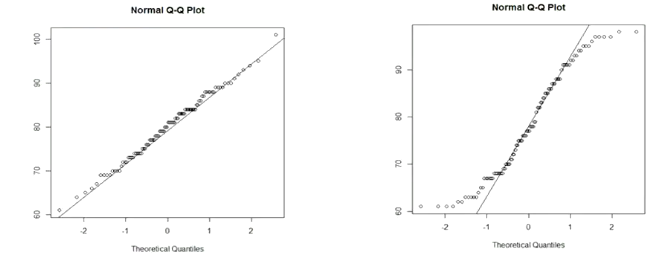
QQ图(检验是否是正态分布,直线斜率是标准差,截距是均值,点的分布越接近直线,就越接近正态分布)
热力图(横坐标表示样本特征,纵坐标是样本,颜色深浅表示值的不同)
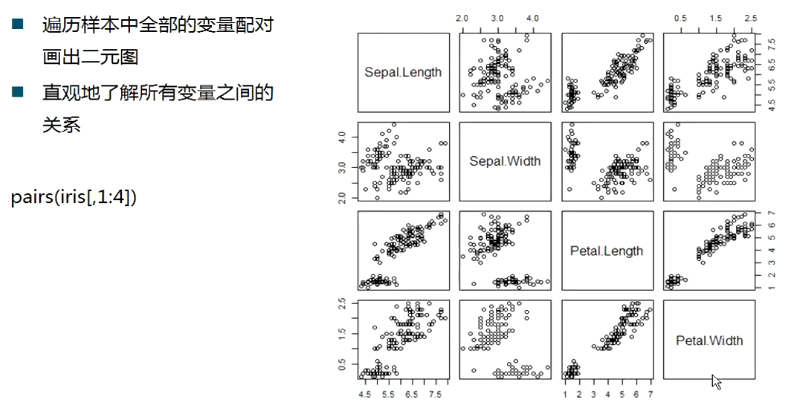
散点图集(plot(iris[,1:4]也能产生这样的效果))
叠加图(画子图)
三、相关分析跟回归分析
相关分析
分析两个变量的相关性,R中可以计算多种相关系数,包括pearson,spearman,kendall相关系数,可以用cor(x,method=pearson/spearman/kendall)
可以画出特征散点矩阵,观察两两特征变量的相关性
回归分析
关于回归的解释,在这里就不详细说了,R中可以用lm()函数,例如fit <- lm(weight~height,data=women)
会得出数据集women中,height跟weight间的回归方程
summary(fit),分别有call、residuals的5个统计量(每个样本的回归拟合残差的统计)、coefficients(每个自变量的回归系数)
普通的线性回归,要满足数据的正态性、自变量之间独立性、自变量跟因变量之间线性和同方差性。
如果违反上面的假设,可以考虑别的回归模型,逐步回归、决策树回归,kernel 岭回归等,这里就不细说了
下部预告:
常见分类算法(logistic回归,线性判别式LDA,贝叶斯NB,决策树DT,神经网络,最近邻)
关联规则分析(apriori,序列模式prefixspan,包括简要说下mapreduce版的fp-growth)
聚类算法(层次聚类,谱聚类,K均值/中心)
维度归约(PCA,SVD,ICA)