实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html
在下面这种类型文件中的请求头的url打开后会得到一个页面
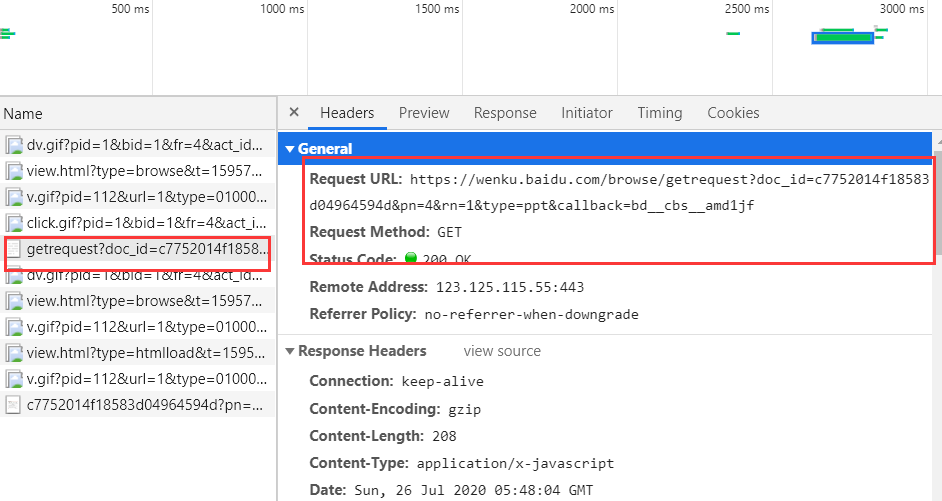
你会得到如下图一样的页面

你将页面上zoom对应的值在一个新的网页打开之后会发现,这个就是ppt中的图片
你可以多打开几个“getrequest?doc_id”类型的请求头看一下它们的Request URL,你会发现我们只需要改变pn对应的数字就能得到文库中对应的PPT图片

知道了这个我们就可以先把图片url弄出来,然后再依次访问这些url,并下载至本地
要注意的是,如下面的url地址
https://wkretype.bdimg.com/retype/zoom/c7752014f18583d04964594d?pn=4&raww=1080&rawh=810&o=jpg_6&md5sum=046b21875cb4e60170f5521eea9253dc&sign=22044930c7&png=102985-135328&jpg=219095-369954
你如果复制之后粘贴在浏览器的地址框里面,浏览器会把这个地址转化成下面这个类型之后再去访问
https://wkretype.bdimg.com//retype//zoom//c7752014f18583d04964594d?pn=4&raww=1080&rawh=810&o=jpg_6&md5sum=046b21875cb4e60170f5521eea9253dc&sign=22044930c7&png=102985-135328&jpg=219095-369954
所以在我们得到地址之后用一些函数处理一下就可以了
因为代码不太复杂,所以就不再详细叙述了
import requests class Spider: def __init__(self): #定义url前缀 self.url_pre = "https://wenku.baidu.com/browse/getrequest?doc_id=c7752014f18583d04964594d&pn=" #定义url后缀 self.url_suf = "&rn=1&type=ppt&callback=bd__cbs__sv0n59" #请求头 self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36' } def Create_url(self): num = input('输入爬取ppt总页数:') for i in range(1,int(num)+1): #构建对应页数PPT的url地址 self.url = self.url_pre+str(i)+self.url_suf #请求后得到页面源码 response = requests.get(self.url,headers=self.headers) html = response.text #因为我们需要从页面源码中拿到PPT中图片对应地址,所以可以通过字符串匹配等方式得到,这里我就用数组查找就行 #找出图片地址在源码中起始和终止位置 start = html.find(':"http') + 2 end = html.find('","') #切割字符串 url_pic = html[start:end] #将图片url字符串,转化为可访问的url地址 url_pic=url_pic.replace('\','') #print(url_pic) self.request_pic(url_pic,i) def request_pic(self,url_pic,num): #print(url_pic) response = requests.get(url_pic, headers=self.headers) num = str(num)+'.png' with open(num,'wb') as f: f.write(response.content) if __name__ == '__main__': spider = Spider() spider.Create_url()