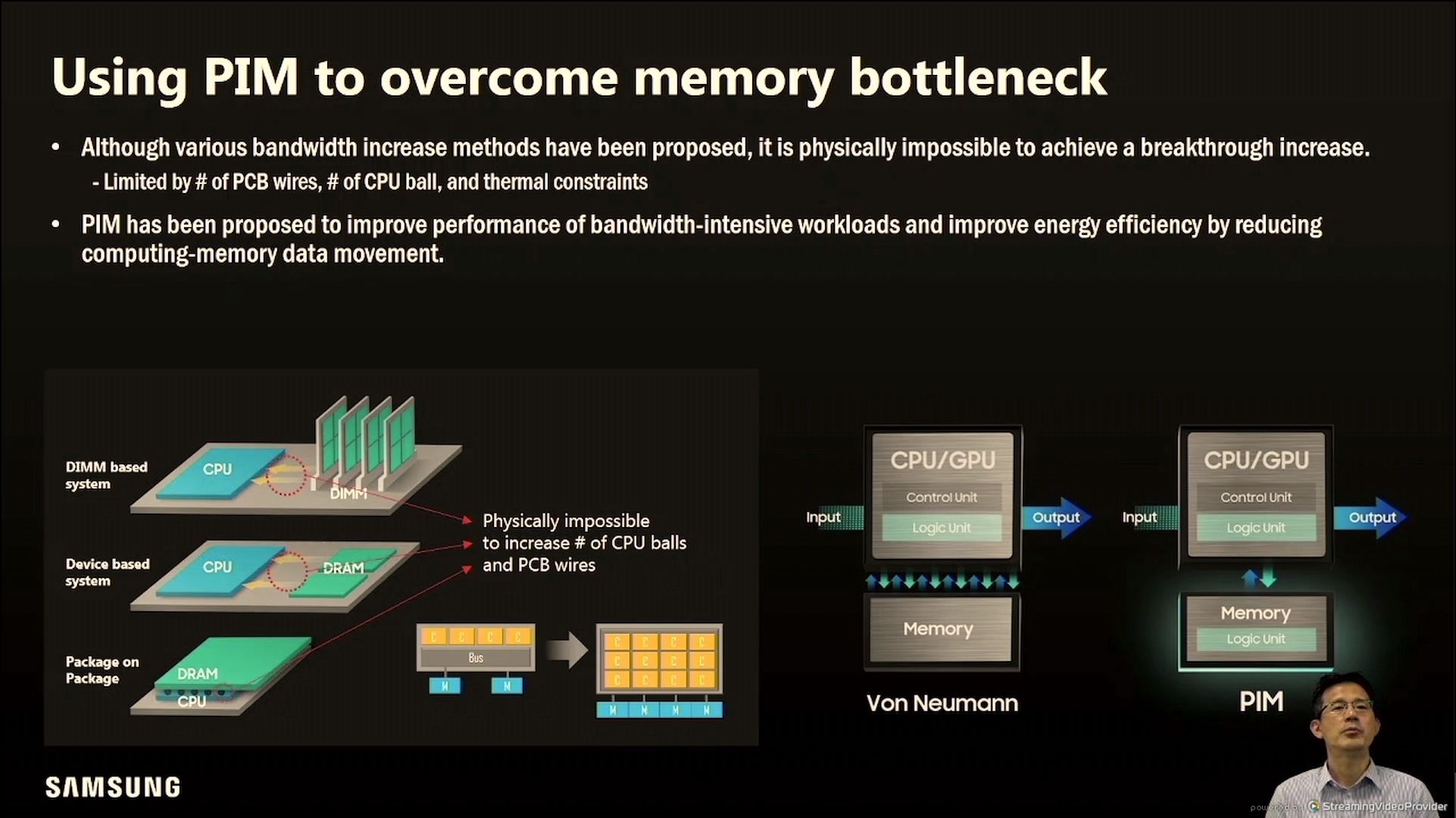
问题提出,也就是说内存和处理器之间的带宽永远都会存在,刚不过就躲一下,直接在内存进行计算。
Aquabolt已经是三星电子的HBM2的内存,Aquabolt-XL是基于HBM2构建了PIM的产品;是这种形式产品的第一代;

上面图中的比较是HBM2和DRAM的比较,不是HBM2-PIM和HBM2的比较,第一次都看错了;下面这个才是:
下面介绍了HBM2产品的位宽和带宽的情况

大的架构上看就是实现最大程度的复用

微观的架构看的话,PIM分为三个部分,SIMD的运算器,寄存器和控制器;

PIM虽小,五脏俱全,有自己的ISA,可以实现,算术运算,数据传输运算,流程控制运算;

PIM的工作模式分为三种:单bank模式,全bank模式,全bank-PIM模式;

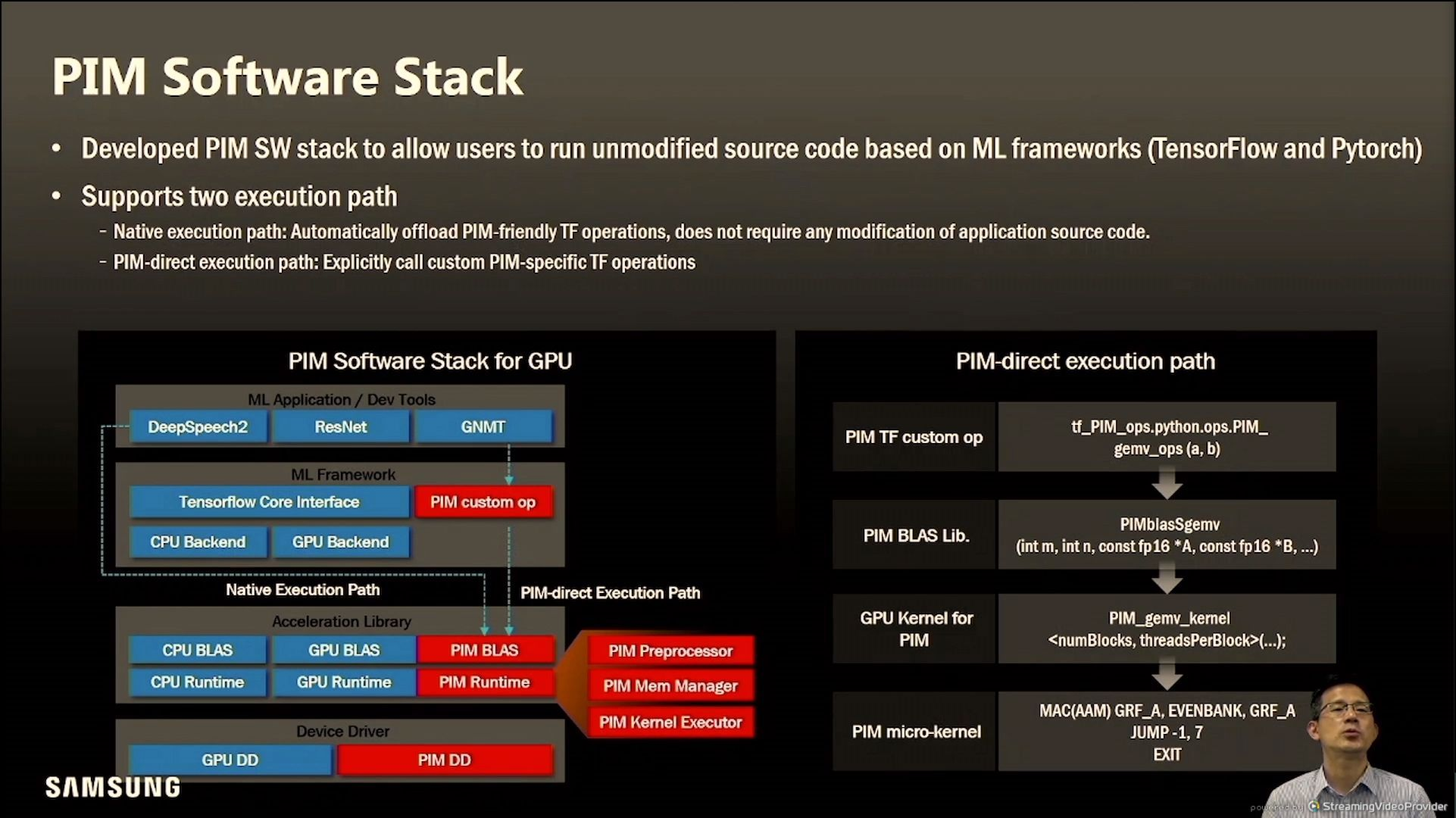
PIM上面是ISA,ISA上面就是Kernel,Kernel上面是应用,因此需要改变的是驱动文件,代数库,最终是框架函数;
下面是芯片的工程上是怎么做的系统集成,8Hi的Die,其中四个是DRAM Die,另外四个是PIM-DRAM Die;

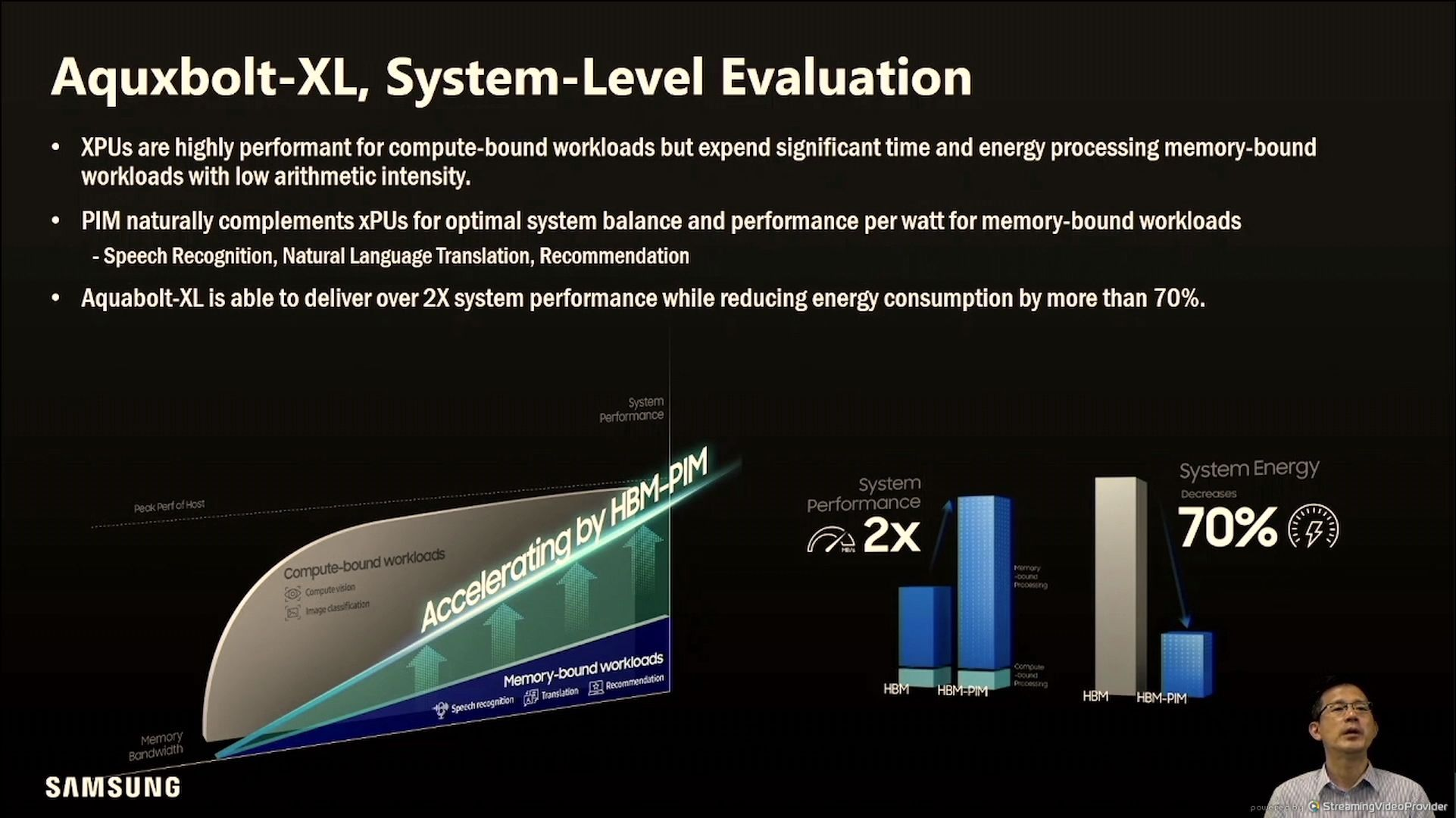
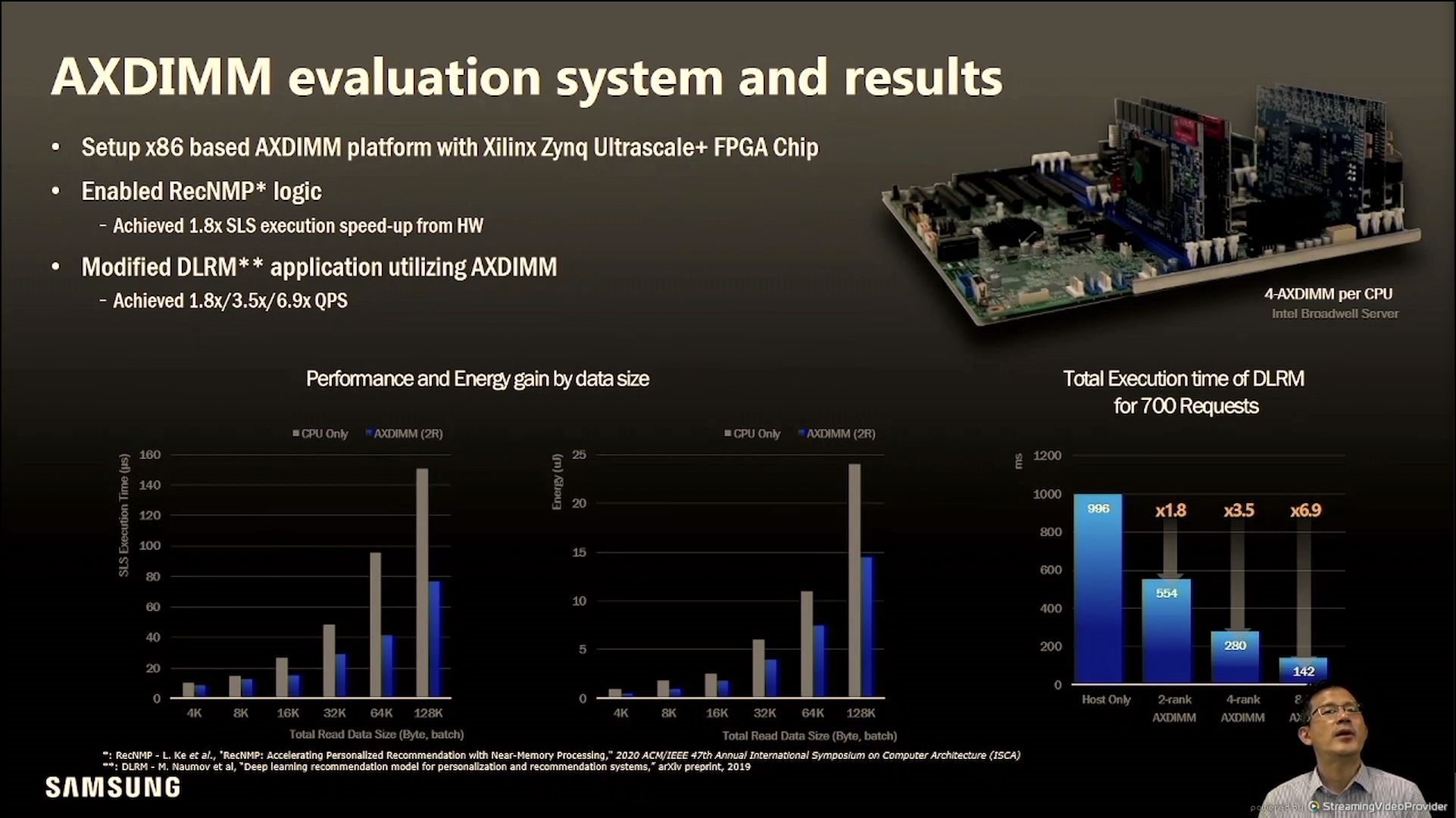
实测的性能的提升还是比较明显的
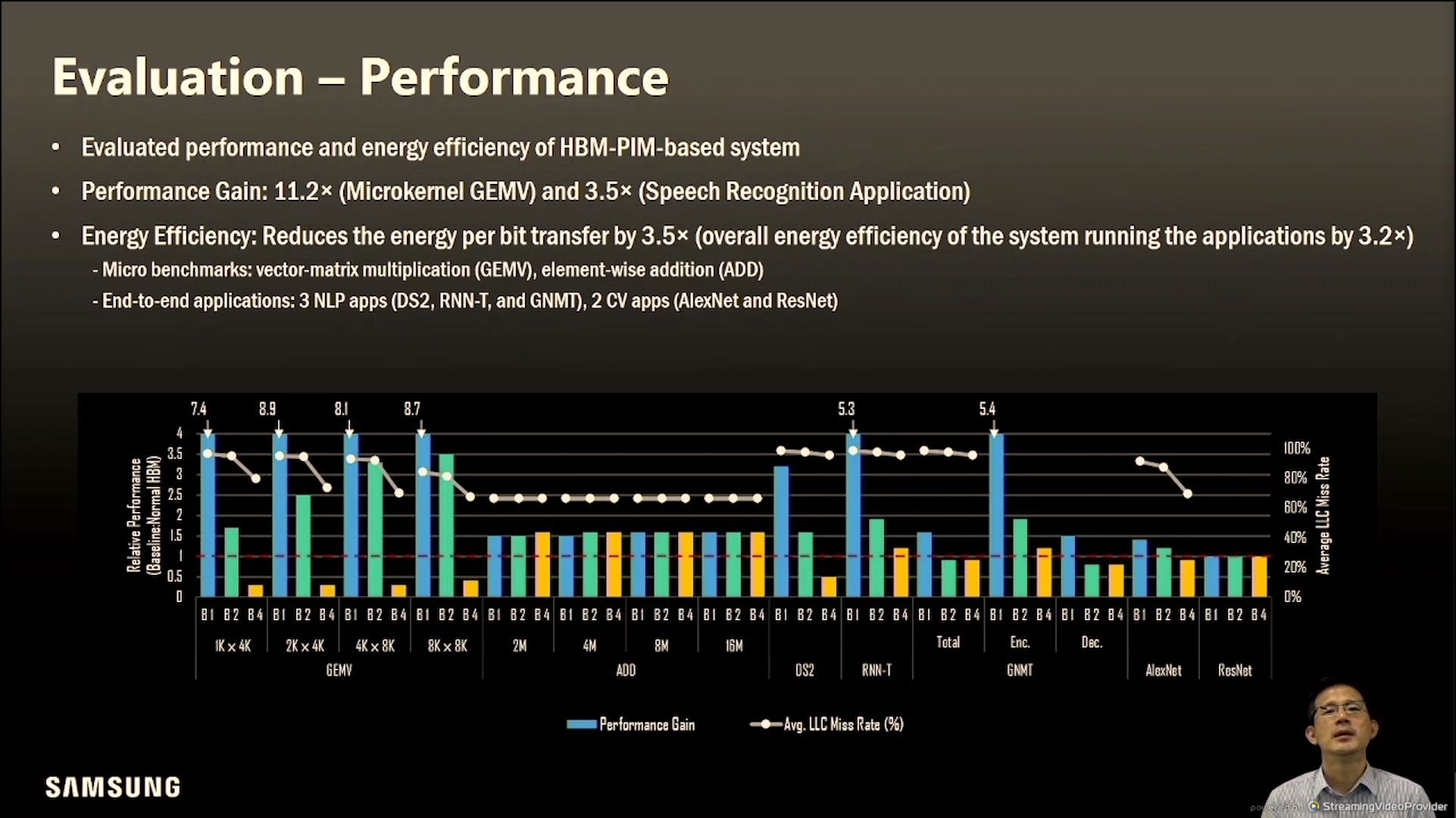
虽然功耗分解上看是略微有些上升

又是一个实测的案例,证明在业务上来看,时间更短,功耗更低

实测时候的配置

实测的结果确实有不小的提升

答疑,应用程序修改较小,正在推动标准,暂时不兼容ECC但是后面争取兼容;

下面的加速DIMM,AXDIMM就是概念产品了,就是在DIMM上添加一个Buffer,提高带宽,减少数据传输降低功耗;

POC的系统也已经测过了
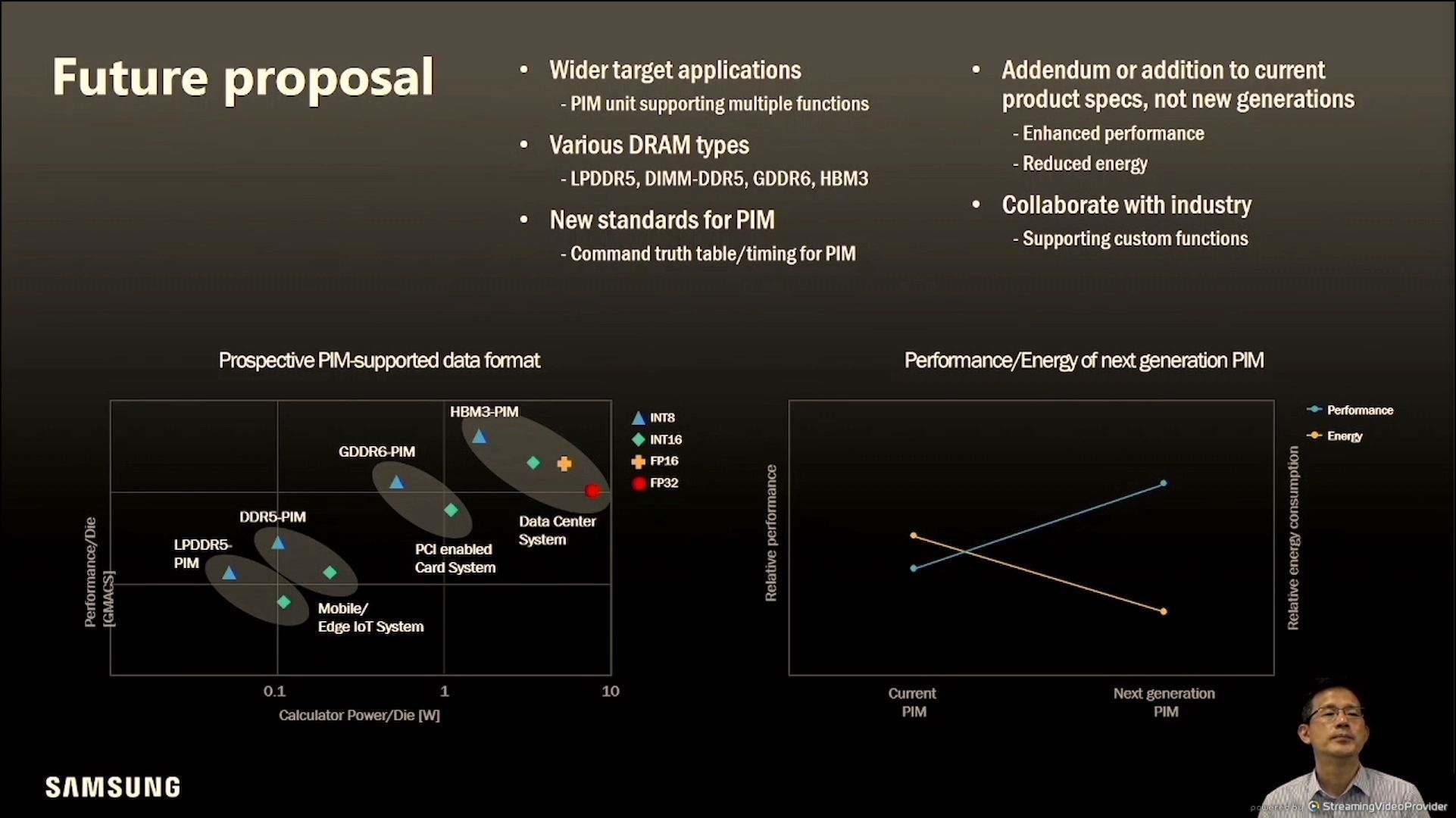
放眼未来,支持更多的DRAM类型,提高性能,降低功耗,推进标准等等;
一个问题就是如何保持一致性,答案是不行;
Q: How does PIM manage coherence with host?
A: memory vision will be offload will not be cached, but those applications have low data reusability
参考文献: