apply(X,MARGIN,FUN,...) 对矩阵、数据库、数组按行或列进行迭代计算,返回向量或数组或值列表。
X: 输入的数组、矩阵,如果是数据框会自动转换成矩阵
MARGIN:按行计算或按列计算,1表示按行,2表示按列。
FUN:调用函数名称
...:为函数FUN提供额外参数。即如果一个函数有多个参数,那么...就是传入除第一个参数意外的其他参数。
例子:
df<-data.frame(x=c("A","B","C","A","C"),'2010'=c(1,3,4,4,3),'2011'=c(3,5,2,8,9),check.names=FALSE)
df_rowsum<-apply(df[,2:3],1,sum) #对2、3列,采用按行计算。
df_colsum<-apply(df[,2:3],2,sum) # 采用按列计算



更多的apply函数家族参考:http://showteeth.tech/posts/15576.html
对数据框分组计算,用aggregate函数,~左边表示待操作变量,~右边表示依据。注:依据可以是一个或多个。
例子:
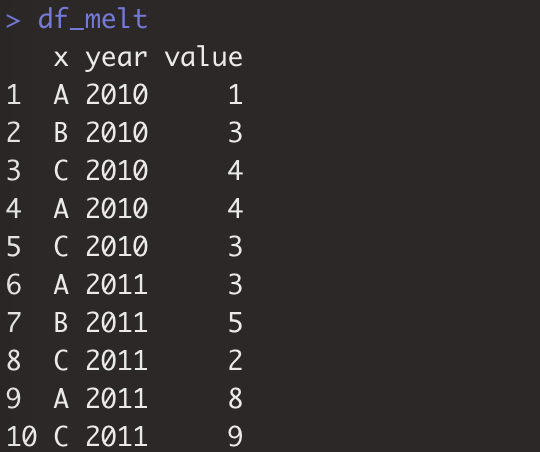
df_melt<-reshape2::melt(df,id.var="x",variable.name="year",value.name="value")
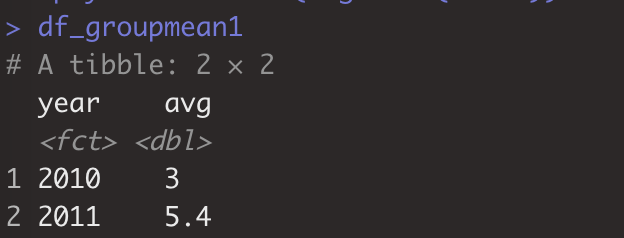
> da_group1<-aggregate(value~year,df_melt,mean) # 数据框df_melt,按year对变量value执行mean计算。

~右边是多个时,则是右边这些变量不同组合情况下的函数操作。
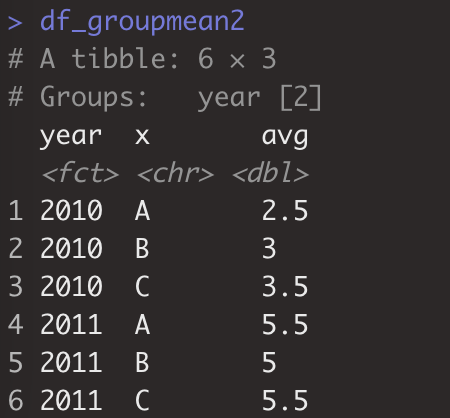
如:> df_group2<-aggregate(value~year+x,df_melt,mean)

~ 左边是多个变量,表示待操作的是多个变量,这些变量分别依据~右侧变量进行函数操作。
如> df_group3<-aggregate(cbind(value,year)~x,df_melt,mean)

对数据框分组计算与aggregate类似但更灵活的是通过dplyr包的groupby()分组,summarise()分组的汇总运算,arrange()分组的变量排序等组合实现与aggregate()类似功能。
常需要搭配%>%这个多步操作连接符。注:groupyby()常和summarise()搭配使用,后者需要前者分组功能。
例子:
> df_groupmean1<-df_melt%>%dplyr::group_by(year)%>% + dplyr::summarise(avg=mean(value)) #与aggregate(value~year,df_melt,mean)效果一致。
> df_groupmean2<-df_melt%>%dplyr::group_by(year,x)%>%dplyr::summarise(avg=mean(value))#与aggregate(value~year+x,df_melt,mean)效果一致。