/***
* Scala 版本中的泛型方法
* Scala中的泛型方法定义,在参数列表之前,方法名称之后,通过[]来进行定义
* Scala来完成Java中的泛型限定
* Java Scala
* 上限限定 <T extends 类型> [T <:类型]
* 下线限定 <T super 类型> [T >:类型]
* 视图限定view bounds 无视图限定 T <%类型
*
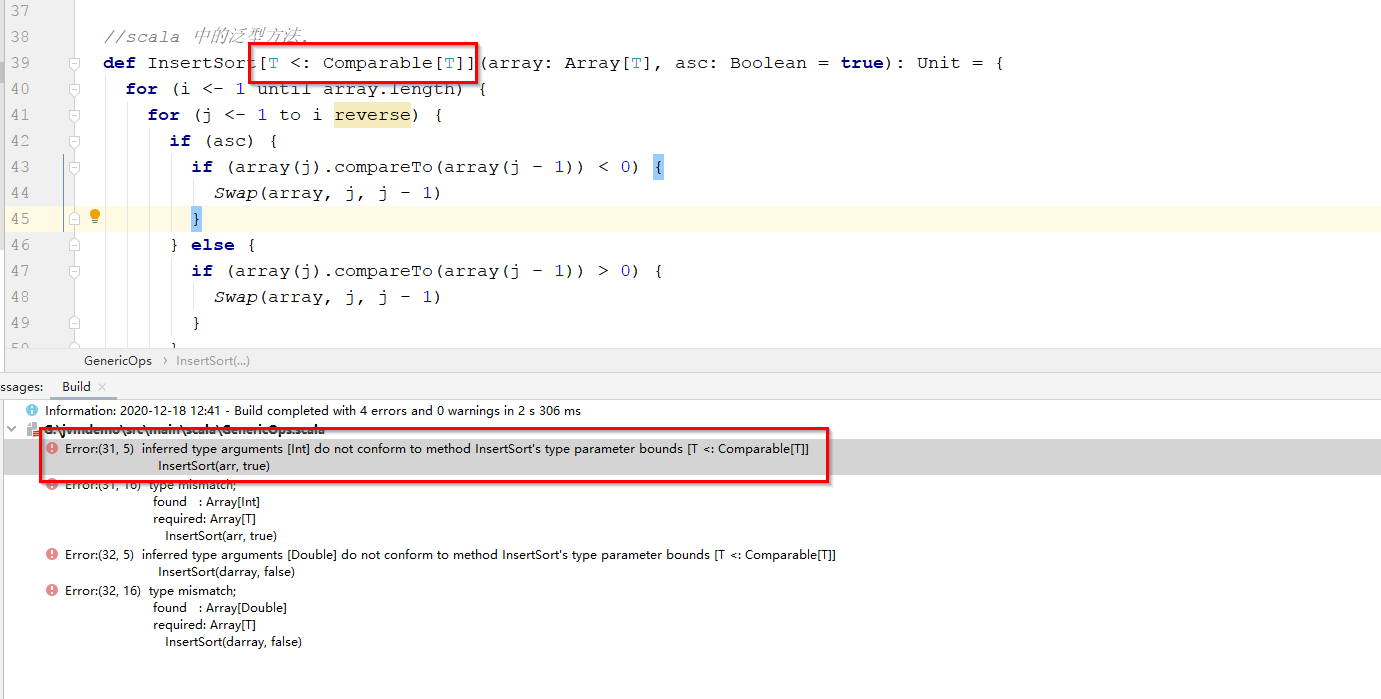
* 分析: 开始 使用Scala中的上限限定 T <:Comparable[T] 来进行处理, idea 没有报语法错误。通过了编译。但是运行时候报:
* Error:(23, 5) inferred type arguments [Int] do not conform to method InsertSort's type parameter bounds [T <: Comparable[T]]
* InsertSort(arr, true) 错误
* 把上限限定 T <:Comparable[T] 改成视图限定 T <%Comparable[T]。通过编译,也完成运行
*
* 主要原因:在Scala中的Int,Double并没有真正的扩张Comparable这个类,自然无法运行
* 但是把上限限定改为视图限定,就可以完成 Int 和 Double的内部增强。(通过隐式转换 把Int,Double分别转换成RichInt,RichDouble,而这两个
* 类都实现了Comparable 或者 Ordered ).这个过程,都是Scala自己实现的
*
*/
object GenericOps {
def main(args: Array[String]): Unit = {
val arr: Array[Int] = Array[Int](3, 5, 6, 1, 2, 4, 3, 10)
val darray: Array[Double] = Array[Double](3.0, 5, 6, 1, 2, 4, 3, 10)
println("排序前的数组[Int] :" + arr.mkString("[", ", ", "]"))
println("排序前的数组[Double] :" + darray.mkString("[", ", ", "]"))
//排序
println("====================插入排序===========================")
InsertSort(arr, true)
InsertSort(darray, false)
println("排序后的数组[Int] :" + arr.mkString("[", ", ", "]"))
println("排序后的数组[Double] :" + darray.mkString("[", ", ", "]"))
}
//scala 中的泛型方法.
def InsertSort[T <% Comparable[T]](array: Array[T], asc: Boolean = true): Unit = {
for (i <- 1 until array.length) {
for (j <- 1 to i reverse) {
if (asc) {
if (array(j).compareTo(array(j - 1)) < 0) {
Swap(array, j, j - 1)
}
} else {
if (array(j).compareTo(array(j - 1)) > 0) {
Swap(array, j, j - 1)
}
}
}
}
}
def Swap[T](array: Array[T], i: Int, j: Int) = {
var tmp: T = array(i)
array(i) = array(j)
array(j) = tmp
}
}
运行结果:

如果是用上限绑定:
/**
* 1,scala的类和方法、函数都可以是泛型。
*
* 2,关于对类型边界的限定分为上边界和下边界(对类进行限制)
* 上边界:表达了泛型的类型必须是"某种类型"或某种类型的"子类",语法为“<:”,
* 下边界:表达了泛型的类型必须是"某种类型"或某种类型的"父类",语法为“>:”,
*
* 3, "<%" :view bounds可以进行某种神秘的转换,把你的类型在没有知觉的情况下转换成目标类型,
* 其实你可以认为view bounds是上下边界的加强和补充,语法为:"<%",要用到implicit进行隐式转换(见下面例子)
*
* 4,"T:classTag":相当于动态类型,你使用时传入什么类型就是什么类型,(spark的程序的编译和运行是区分了Driver和Executor的,只有在运行的时候才知道完整的类型信息)
* 语法为:"[T:ClassTag]"下面有列子
*
* 5,逆变和协变:-T和+T(下面有具体例子)+T可以传入其子类和本身(与继承关系一至)-T可以传入其父类和本身(与继承的关系相反),
*
* 6,"T:Ordering" :表示将T变成Ordering[T],可以直接用其方法进行比大小,可完成排序等工作
*/
class Person(val name:String){
def talk(person:Person){
println(this.name+" speak to "+person.name)
}
}
class Worker(name:String)extends Person(name)
class Dog(val name:String)
//注意泛型用的是[]
class Club[T<:Person](p1:T,p2:T){//"<:"必须是person或person的子类
def comminicate = p1.talk(p2)
}
class Club2[T<%Person](p1:T,p2:T){
def comminicate = p1.talk(p2)
}
class Engineer
class Expert extends Engineer
//如果是+T,指定类型为某类时,传入其子类或其本身
//如果是-T,指定类型为某类时,传入其父类或其本身
class Meeting[+T]//可以传入T或T的子类
class Maximum[T:Ordering](val x:T,val y:T){
def bigger(implicit ord:Ordering[T])={
if(ord.compare(x, y)>0)x else y
}
}
object HelloScalaTypeSystem {
def main(args: Array[String]): Unit = {
val p= new Person("Spark")
val w= new Worker("Scala")
new Club(p,w).comminicate
//"<%"的列子
//只是提供了一个转换的方法,在遇到<%时会调用看dog是否被转换了。
implicit def dog2Person(dog:Dog)=new Person(dog.name)
val d = new Dog("dahuang")
//注意必须强制类型转换,implicit中虽然是将dog隐式转换成person,
//但是其实是对象擦除,变成了object,所以还要强制类型转换成person后才能使用
//用[person]强制转换
new Club2[Person](p,d).comminicate
//-T +T例子,下面的participateMeeting方法指定具体是什么泛型
val p1=new Meeting[Engineer]
val p2=new Meeting[Expert]
participateMeeting(p1)
participateMeeting(p2)
// T:Ordering 的例子
println(new Maximum(3,5).bigger)
println(new Maximum("Scala","Java").bigger)
}
//这里指定传入的泛型具体是什么
def participateMeeting(meeting:Meeting[Engineer])= println("welcome")
}
T:ClassTag的例子(根据输入动态定义)
命令行代码:
scala> import scala.reflect.ClassTag
import scala.reflect.ClassTag
scala> def mkArray[T: ClassTag](elems: T*) = Array[T](elems: _*)
mkArray: [T](elems: T*)(implicit evidence$1: scala.reflect.ClassTag[T])Array[T]
scala> mkArray(1,2,3)
res1: Array[Int] = Array(1, 2, 3)
scala> mkArray("ss","dd")
res2: Array[String] = Array(ss, dd)
scala> mkArray(1,"dd")
res2: Array[Any] = Array(1, dd)