hadoop 相关介绍
hadoop的首页有下面这样一段介绍。对hadoop是什么这个问题,做了简要的回答。
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets >across clusters of computers using simple programming models. It is designed to scale up from single servers to >thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver >high-availability, the library itself is designed to detect and handle failures at the application layer, so >delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
总结一下 hadoop 可以概括为如下几点:
- 是多个software 集合,而不是某一个software
- hadoop是可扩展,可靠的用于分布式计算的。其可靠性和可扩展性用软件实现而不依赖于昂贵的硬件
既然是多个software组成的集合,我们可以简单的理解为hadoop是一个生态系统,里面包含的组件如下:
Hadoop Common: 一些在hadoop生态系统中通用的 common utilities
Hadoop Distributed File System (HDFS™): 一个分布式的文件系统
Hadoop YARN: 分布式的资源管理器和作业调度系统
Hadoop MapReduce: 一个基于yarn的计算框架
hadoop生态系统中还包含很多其它独立project 如下:
Ambari™: 一个基于web的管理系统,可以管理几乎所有的hadoop组件如hdfs mapreduce等等
Avro™: A data serialization system
Cassandra™: 一个可扩展的,具有多个master 节点的数据库,多master特性使得其不存在单点失败。
Chukwa™: A data collection system for managing large distributed systems.
HBase™: 一个可扩展的支持big table的列式数据库。
Hive™: 一个数据仓库系统。
Mahout™: 一个可扩展的机器学习和数据挖掘的库
Pig™: A high-level data-flow language and execution framework for parallel computation.
Spark™: 一个快速通用的计算引擎。使用spark做计算可以很方便的编写代码并且spark支持多种计算模式如:ETL, machine learning, stream processing, and graph computation 等.
Tez™: A generalized data-flow programming framework.
ZooKeeper™: 在分布式系统中用来协调各个节点的一个高性能框架
hadoop中包含太多的组件,因此接下来我们只对其中的部分做简单介绍。 分别是
- mapreduce
- hdfs
- spark
- hbase
- zookeeper
mapreduce
map reduce 最早是google的两个科学家(Jeffrey Dean and Sanjay Ghemawat)发表的一篇论文。 论文链接在此,感兴趣可以阅读,对理解map reduce非常有帮助 。 文章介绍了google 在处理大数据计算方面使用的一种通用的解决方案。 既然是论文和方案,那么我们就要明白,具体的实现肯定是可以有多种的。而hadoop的mapreduce框架只是其中一种。
key value pair
在理解map reduce之前,要知道,map reduce中处理的大部分数据形式都是key-value pair的形式。 一般来说,map的输入是键值对,输出也是键值对,而reduce的输入是map的输出。
下面我们通过一个例子来理解 map reduce
word count
要理解mapreduce 最好的是通过实际例子。假设我们有一个需求,是计算一个文本文件中每一个单词出现的次数。比如文本文件someFile.txt如:
hello world
greate world
greate day
那么我们用map reduce计算完后应该能得到统计结果如:
hello 1
world 2
greate 2
day 1
具体实现如下,我们采用python来实现,首先定义一个map.py :
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s %s' % (word, 1)
该函数非常简单,把标准输入中读到的每一行都处理,然后对每一个单词都生成一个键值对(比如hello 输出 hello 1)
。我们运行该函数看一下。
[root@node3 test]# cat someFile.txt | ./map.py
hello 1
world 1
greate 1
world 1
greate 1
day 1
这里我们可以认为map的输入是键值对(行号和行)输出也是键值对(单词和1)。
map的输出将作为reduce的输入。我们 定义一个reduce python程序。
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split(' ', 1)
count = int(count)
if current_word == word:
current_count += count
else:
if current_word:
print '%s %s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s %s' % (current_word, current_count)
reduce 在这里做的事情也很简单。如果输入的key ,value pair是根据key 排好序的,那么key相同的键值对,比如 hello 1 和 hello 1,会合并成 key , sum (value)的形式。
ok, 我们的map 和 reduce 程序已经完成。简单的说,map 函数把 原始的文本文件分割成 word,1 这样的许多个小的key value 对。 而reduce 把word相同的键值对合并,把它们的value (也就是1)相加,得到这个word的个数。
实际运行一下,如下:
[root@node3 test]# cat someFile.txt |./map.py | sort | ./reduce.py
day 1
greate 2
hello 1
world 2
很容易的我们就算出了文件中各个单词的个数。这里我们就用map reduce 的计算架构实现了一个计算。 但是你一定注意到了我们在./map.py 和 ./reduce.py 的运行中间用了一个 sort。 这是非常非常重要的一个点。 因为我们的reduce 函数在合并 map的输出的时候 非常的弱智,以至于它只能处理排序好的结果,如果不排序,他算出的结果将非常的混乱。
ok,总结一下上面的内容。我们可以发现,map reduce的大致过程可以概括如下:
- map 把input split成多个可以并发处理的小块键值对(行号,行)并转化成新形势的键值对(word,1)
- sort 对 map的结果做一些处理
- reduce 对map&&sort的输入 做处理,把相同的(word,1)的键值对合并成 (word,sum(1,1,1,1...))这样的形式
抽象概括map reduce的过程就是
input :split 成适合并行处理的 (k1,v1),(k2,v2)
map :把 (k1,v1)(k2,v2) 转化成 (x1,y1),(x2,y2),(x1,y3)
sort :对 map输入做排序等处理
reduce :把 相同key的输入做合并 (x1, aggregate[y1,y3])
正因为map的输入是split成适合并行处理的小块,所以map reduce 可以并发的计算大量的数据。我们的例子比较简单,在map 和 reduce中间只用了一个sort。 但实际的计算中,中间仅仅是sort是远远不够的。 在真正的map reduce实现中,map 和 reduce中间的步骤叫做shuffle。是极其复杂和重要的一步。
map - shuffle - reduce
其实真正的map reduce 应该叫做map - shuffle - reduce 。我们结合word count的例子,更详细的浏览一遍 map - reduce的过程,来理解shuffle。
不过在这里先暂停一下,了解一下worker的概念。在hadoop mapreduce架构中,有worker这样一个角色。你可以理解它为进程。 hadoop master在进行计算的时候会考虑自己有多少个worker。假设我们的环境中有6个worker,那么hadoop 可能会分配3个worker去做map 任务,而3个去做reduce任务。 ok,知道了这些,我们就可以继续探索word count的case。
现实中,如果要对一个非常大的文件做word count计算,那么第一步自然是读取这个文件。
第一步,input and split
文件一般是在HDFS 分布式系统上,因此读取是并发读取,然后split。 通常split的结果是hdfs的 block,为了便于理解,我们认为这里split 后是 文件的行
第二步, map
根据之前的例子,我们知道map worker的输出将会是(hello,1),(world,1) 这样的键值对。而且我们还知道,reduce要做的事情是对相同key的键值对做合并。那么很容易就明白,我们必须把相同key的键值对发给同一个 reduce worker处理。 那么就涉及到下面的步骤 partition
第三步,partition
任意一个map worker生成的数据都是(hello,1),(world,1) 这样的键值对,这些键值对会先缓存在当前计算机的内存中,当内存不够的时候会写入local disk(记得开头的那段英文说map reduce架构中 "each offering local computation and storage"? 就体现在这里)。 在写入本地磁盘的过程中,会通过一个函数来把当前计算机产生的map 结果用一个partition函数处理。这个partition函数可以自己定义,在hadoop架构中也有预定义的partition函数。无论是哪种,只要满足同样的key 分到同一个 partition,进而发给同一个reduce worker即可。
比如可以定义函数是 lambada key:len(key)%R, (R是reduce worker的个数) 也就是用key的长度对 reduce worker的个数取模运算,这样能保证相同的key运算得到的值是一定的。 比如 len(hello)%3 = 2。 这样hello 这个key对应的结果都会发给reduce worker 2。
ps : 关于键值对缓存在内存,swap到硬盘,以及partition发生的时机等其实是跟具体的map reduce实现相关的,这里说的是hadoop mapreduce的实现。
第四步,combine
一个map worker生成的结果会有很多,而且都是如 (hello,1) (world,1)这样的形式。这些结果都缓存在当前的computer。将会通过网络发送给reduce worker来进行reduce 计算。但是这里有个问题就是 map 产生的结果量应该是相当巨大的,假设有当前节点就有100万个(hello,1)这样的键值对,这样的数据通过网络发送给reduce worker会非常的占用带宽。 所以这里我们最好先简单的计算一下,把100万个(hello,1) 变成(hello,1000000)。这里你一定发现了,combine 和 reduce做的事情其实是一样的。
第五步,merge
reduce worker在map完全结束之前一般不会启动,这时候它要做的就是不断的从各个map worker的本地磁盘那里去 拉取 (注意这里是拉取而不是主动的推送,这和具体的实现有关)数据。 但是一个reduce worker应该从多个map worker那里拉取数据。那么在我们的例子中, map worker 1可能产生 (hello,1000000) , map worker 2 可能产生的键值对是(hello,100) 而 map worker 3 产生的键值对也许是 (hello,888)。 reduce worker这时应该调用一个merge函数把它们合并成(hello,[10000000,100,888]) 这样的结果。
第六步,reduce
这一步reduce worker会把 hello 对应的value list(10000000,100,888)调用aggregation函数来计算,产生(hello,10000988)这样的结果。 这时mapreduce计算过程完毕。
这上面的partition combin merge等步骤统称为shuffle。
mapreduce总结
mapreduce是google的一篇论文中提出的一种计算架构。核心思想就是把大数据split成适合并行计算的 k,v 键值对,通过map函数转换成中间形式的k1,v1键值对,然后通过reduce函数计算出 k2,v2这样的结果。
要注意的点
input split
mapreduce在map之前要把input split成小块。通常来说这些小块的size等于一个HDFS的block最好。这种情况下,map worker可以从本地存储中读取split。 而如果split 的size大于一个block, 那么有可能另一个block 不在本地。
hadoop stream
hadoop是java写的,但是使用hadoop你却不一定非得用java。hadoop提供了一个stream的机制让你可以使用别的语言来编写hadoop的map 和 reduce程序。 Hadoop stream使用unix的标准输入输出stream来实现,所以只要你所使用的语言能够读取 standard input 并且写入 standard output,那么你就可以用该程序来编写map reduce程序。前面我们使用python写的map 和reduce程序就可以使用hadoop 的stream特性。
hdfs
了解了hadoop mapreduce后,我们看一下hdfs。我们知道了mapreduce是一个分布式的计算系统,在最开始的输入端要把输入源split成多个易于并行处理的键值对。 如果输入源是一个local 文件系统,那无疑效率会低很多。所以需要hdfs
hdfs是hadoop的分布式文件系统。文件被打散成一个个的data block 存储在不同的节点上。hdfs的架构为master/slave架构。cluster中有一个唯一的NameNode(master节点),剩下的节点为DataNodes(slave 节点),通常有多个。 hdfs把文件分成多个block,这些block存储在不同的DataNode上。NameNode负责执行对文件进行open,close,rename file&&directory 操作,也负责维护block和DataNode之间的map关系。DataNode则负责block级别 create delete read replication 等操作。 整个架构如下图所示: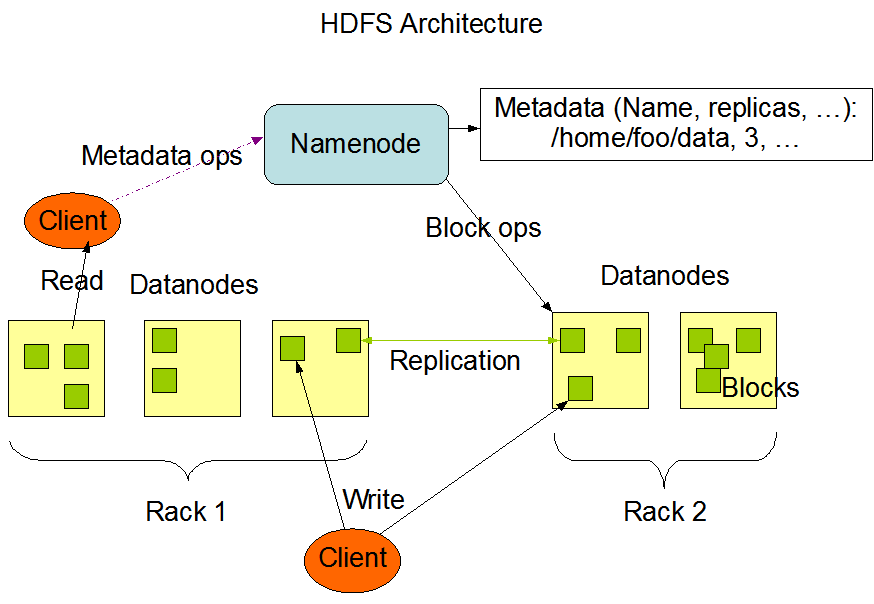
desgin and unfitness
HDFS被设计成 storing very large files with streaming data access patterns, running on clusters of commodity hardware。
我们仔细的理解这句话,
very large files
意味着文件会非常的大,现在运行的hdfs中可以存储petbytes级别的文件
streaming data access
streaming data access是相对于 random read来说的。hdfs的设计理念是它适合于文件写一次,读多次的场景。也就是说,文件被写入一次,然后被多次的读取被多种的analysis任务来使用。所以hdfs注重的是吞吐量,注重的是快速的把大批量的数据返回给使用者,相对而言,快速的找到这个文件就不那么重要了。
Commodity hardware
hdfs集群需要能运行在多个相对廉价甚至结构不同的计算机上,因而要面对其中某台计算机发生故障的情况,hdfs要保证使用者不会体会到这种单点故障影响。
理解了上面的内容后,就应该知道有一些情况hdfs是不适用的。比如下面:
low-latency data access
hdfs的设计理念就是提高大批量读取的吞吐速度,所以快速的访问某个文件中的某个位置不适合hdfs。
lots of small files
HDFS的name node用于管理文件的原信息,一般来说一个file, directory 占用 150 bytes。那么显然HDFS不适合管理过多的小文件。
Multiple writers, arbitrary file modifications
hdfs中的文件只能被一个writer去写,因为文件只能在末尾追加内容。所以如果想修改文件中任意位置或者多个人并发写而不糊干扰,那么hdfs不适用。
Datablock
Data block是一个在文件系统和磁盘中普遍存在的概念。因为CPU的速度远高于磁盘的读写速度,如果没有block的概念,那么一次一个bit 一个bit的读取无疑会非常缓慢。和普通的文件系统一样,hdfs也有data block的概念。默认的大小是128M。这个数字远大于普通文件系统的data block大小。 这是因为hdfs的在data block的查找方面开销是比较大的。所以在大批量I/O的时候, 单个的data block越大,data block查找所带来的开销就越小。
在HDFS中有一个replication的概念,也就是一个data block保存几分,并且hdfs会保证同一个data block 和它的replication不会存在于同一台机器,甚至是同一个机柜中。因此,如果某一个文件需要经常被读取,可以对该文件的data block设置较高的replication,这样它的data block会散步在整个cluster中。读取的时候也能获得更高的并发性。
Name node Data node
hdfs中有两种节点。name node 和 data node。namenode管理整个系统的名称空间。它管理filesystem 的树状结构和 其中所有文件,目录的metadata。这些信息以两种形式(namespace image 和 edit log)存储在namenode的本地存储中。 namenode还知道某一个文件的所有data block存储在哪一些 datanode上,但具体的data block 的位置它却不知道,因为那是data node管理的事情。 并且每次data node重启,data node都有可能漂移到其它的节点。
用户在访问hdfs的时候通过hdfs client,hdfs client隐藏了name node和 data node,所以在最终用户看来,hdfs就像本地文件系统一样使用。
datanode 根据client或者namenode的指令存取data block。并且 datanode还会定期的把自己管理的data block的列表报告给name node。
为了保证name node数据不丢失,hadoop使用三种种机制。
- 在写入本地namespace image 和 edit log的时候同时写入远程的文件系统。
- setup 一个secondary name node。
- setup 一个standby name node
在理解这3种机制前要了解 namespace image 和 edit log。 namespace image是hdfs中文件目录等的meta data。name node启动后会把该信息load进内存,当新的对namespace的个更改请求发过来的时候,namespace 会做两件事:
- 把更改写入edit log
- 把更改写入内存中的namespace image
这2步完成后才会发送成功给client。
在之后的运行中,hadoop会在合适的时间把edit log中的内容写入namespace image。 这么做是处于安全和性能两方面考虑。机制和关系型数据库中的log是一样的。
回到hadoop 对name node高可用采用的3种机制
第一种,
主要是保证数据不丢失。 一旦name node失效则新建一个name node,导入之前的数据。但这个操作会很耗时。
第二种,
secondary name node的主要作用是把master name node发过来的 namespace 和 edit log 做合并,避免edit log过大。但这种情况如果master失败,还是会有一定的数据丢失。所以最好结合第一种方案来保证数据完整
第三种,
其实第一种和第二种方案结合可以保证name node的数据的恢复,但是耗时会比较多。hadoop引入了一种新的机制,叫active - standby架构。 这种架构中有两种name node,active 和 standby。正常情况下active 节点对外提供服务,一旦遇到问题,standby 节点将替代active来服务。 这种架构中:
name node间共用一个共享存储来存储 edit log。standby node启动后会读取edit log 一直读到最新的位置,然后active 在写entry到edit log的时候,standby 也会接收到最新的edit log 信息。
data node在发送 block report的时候,要发送给所有的active和standby node。因为block map存在内存而不是硬盘中
data flow
本段展示数据在写入hdfs和从hdfs中读取的时候经过怎样的流程。为了便于展示将会提供两副图。但由于是外部图片,不能保证图片永远存在。不过没关系,请相信流程非常简单,通过文字你也可以很清晰的理解。
读取

- 客户端会调用 DistributedFileSystem object的一个open函数去打开一个文件。
- DistributedFileSystem 使用RPC 去和namenode通信获得开始部分data block所在的data node信息
- DistributedFileSystem 会返回一个 FSDataInputStream对象。 client用该object 的read方法可以读取数据。对于每一个data block,namenode会返回持有这个 data block的所有data node ,并且这些data node会按照client访问他们所需的开销排序。(这里的开销指client到目标节点的网络开销。)
- read会找到开销最小的 datanode 读取数据,读取完毕后关闭到datanode的连接
- 读完一个data block会继续为下一个data block寻找最优data node然后读取
- 在全部读取完毕后 FSDataInputStream对象关闭。
在读取的过程中,如果读取某一个data block的时候发现data node无法访问,DistributedFileSystem对象会寻找针对该data block的次优节点,然后继续读取,并且会记录下来失败的data node, 在之后的访问中不再在这个节点上浪费时间。 这整个架构的好处在于client 直接和data node通信获取数据,所以I/O散布于集群中所有的data node上。对于name node而言,只是从内存中找到data block的位置然后返回给客户端。
写入
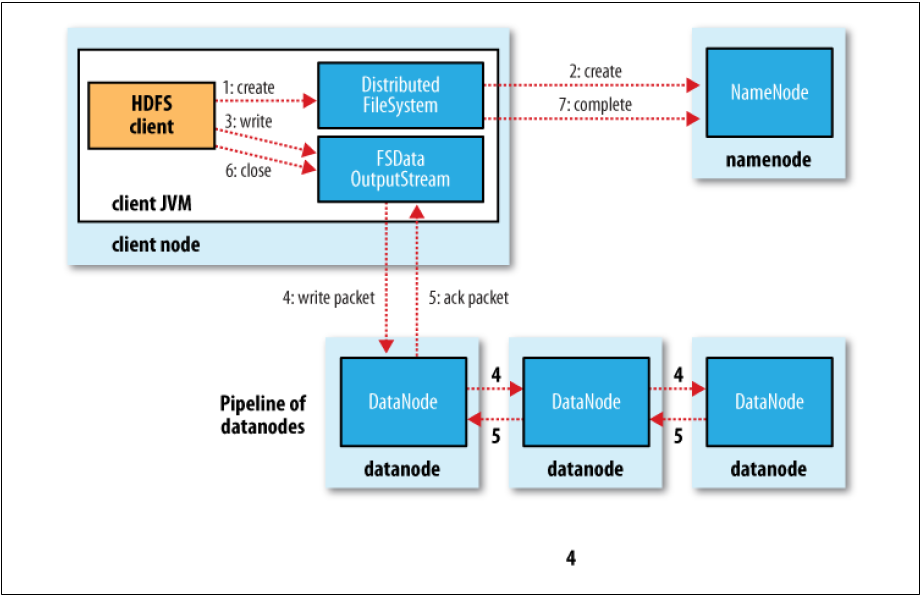
- 客户端调用DistributedFileSystem object 的create方法
- DistributedFileSystem 对象通过RPC 访问 namenode 创建一个没有data block的文件名。在这个过程中namenode会做很多check比如permission,文件是否已经存在等等。如果faile则抛出IOException 否则返回FSDataOutputStream 对象。通过该对象client可以与namenode和datanode交互。
- 当client写数据时,FSDataOutputStream 对象把datablock切割成小的packets并放入data queue。
- 这时有一个新的object叫DataStream,该对象负责向namenode申请 data block。 name node会对每个申请返回一个datanode的list。假设我们的系统中设置的replica为3,那么list中包含3个datanode,该list叫Pipeline。DataStream会把data queue中的packet发给Pipeline中的第一个node,第一个node成功后传递给第二个以此类推。
- DFSOutputStream还维护着一个Queue叫ack queue。该queue中存放着 已结发送给Pipeline等待成功 acknowledge 的packets。 只有当Pipeline中的每一个node 都返回了成功 acknowledge 后,对应的packet才能从 acknowledge queue中删除。一旦Pipeline中的某一个 datanode 失败,系统会作如下事情:
关闭Pipeline
ACK queue 中的所有packet都拷贝到data queue中,这是为了确保Pipeline中出问题的data node后面的data node不会接收不到这些数据。
现在运行良好的 datanode中已经写入的data block被赋予一个新的id,这样 出问题的 datanode中已经写入了一半的datablock在该datanode启动后会被删掉
Pipeline中剩下的data node组成一个新的Pipeline( 数目小于replica)
继续写剩下的packet
namenode 把这个data block标记为under-replica 会在何时的时间补全它需要的replica数目。
当然,很有可能Pipeline中的data node坏掉了不止一个。 但只要dfs.namenode.replication.min replicas (默认值是1) 这个值的写入满足了,那么这次写入就认为是成功的,namenode会在后面默默的补全replica。
NETWORK TOPOLOGY AND HADOOP
hadoop也能够计算出不同 node 之间传输数据的网络开销。实际的开销当然是基于带宽的,但是实时的测量带宽几乎不可能。hadoop使用的是另外一种方式。hadoop 为开销设定了以下几个级别,越往下级别越高
- 同一台node
- 同一个机柜上的不同node
- 同一个机房中的不同机柜上的不同node
- 不同机房中的node
所以如果假设我们有一个node n1,在rack r1上,而该rack位于data center d1,那么我们可以很容易的量化不同情况下的网络开销,如下:
- distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node)
- distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack)
- distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center)
- distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data centers)
Hadoop就是利用这些开销标准来做出一些performance 和 reliablility 上面的决定的,比如数据块的replica该放在哪里,在读取数据的时候如何找到最优的data node 。 另外很重要的一点是要知道hadoop 无法自己识别网络拓扑结构,这需要你提前通过配置告诉它。
REPLICA PLACEMENT
hadoop 中有replica这么一个机制。简单的说就是数据要存放多少份。这是处于安全和性能考虑的。在一个数据有多份的情况下,安全性无疑是大大提高的,而且读取速度也会提高,因为我们可以并发的读取同一部分数据。 但是同样的,在传输上也会存在开销。hadoop在选择存放策略的时候会考虑如下因素:
- 带宽开销
- 数据安全
- 目标节点是否太过繁忙
balancer
HDFS数据的balance 是指数据平均分布在集群中的所有节点上。但这只是理想状态。很多原因会导致数据分布不均匀。参照上面的replica placement中提到的一条,节点是否繁忙,我们就知道有一种情况肯定会导致数据分布不均匀。比如你有10台hdfs 节点,这时你新增了一台节点到集群中,那么针对另外十台节点来说,该节点肯定是最不繁忙,资源最多的,这时候HDFS会优先利用该节点存储数据,这就会导致数据的不平衡。
不过hdfs 提供了一个自动化的服务来解决这一问题, balancer。
balancer是一个守护进程形式存在的服务,启动balancer后,该服务会以最小的开销去尽力维护集群中数据的平衡。尤其是在新增节点到cluster时,一定要启动balancer。
数据一致性
HDFS 的数据一致性与传统的文件系统略有不同。主要关注以下两方面
- 文件创建后可以立即被所有人看见
- 正在被写的data block无法被看见。
YARN
Apache YARN (Yet Another Resource Negotiator) 是hadoop集群的资源调度系统。在单机节点上资源调度由操作系统完成,但是集群中,比如hadoop 集群则需要一个架构在操作系统之上的资源管理器。这里就采用YARN。假设没有资源调度
下图显示了 YARN在 hadoop生态系统中的位置

YARN 提供了对最底层资源的调度,并提供了一些API来实现这些调度,单用户一般不需要调用这些API,因为有现成的计算框架如Mapreduce,Spark会调用这些API,用户只需写能够用在这些计算框架中的程序即可。 注意这里的资源说的是CPU,内存等,不是底层的hdfs和hbase。 hdfs 和 hbase是一般来说整个系统中数据段输入源。
YARN中提供了两种类型的服务,Resource Manager 和 Node Manager。ResourceManager 在整个集群中只有一个,负责集中调度分配资源,而Node Manager运行在系统中的每个节点上,用来启动和监视container。
Container , cgroups
上面说的了container,这里稍作介绍。 YARN 主要负责对CPU 和 内存等资源实现调度,而使用的底层技术就是Linux Cgroup。Linux Cgroup是linux 内核所支持的一种机制,全称叫controller group。 可以让用户把进程根据一定的需求分组,对每一组进程分配指定的cpu,memory等资源。 而这里的Container 指的就是cgroups。 可见YARN的Node Manager 通过启动container 和监视container 可以对一组进程(也就是我们的计算任务)进行资源管理。
YARN 运行 application
YARN运行application可以概括为以下几步:
- client 像YARN集群提交运行任务的申请
- Resource 接到申请后,通过一定的策略通知一个Node Manager启动一个container 来执行用户的程序
- 如果用户的程序需要更多的资源,Node Manager会像 Resource Manager申请更多的container
- 以此类推 , 每一个container启动获得资源后执行任务并根据需要申请更多的资源
Locality 和资源分配
hadoop 构建在hdfs之上,所以YARN上运行的应用输入源一般都是hdfs的data block。 假设 hadoop 的replica 设为3, 那么YARN 在分配container的时候,会优先在持有该data block的节点上分配container。 假设分配条件达不到,比如说该节点资源不够,那么会退而求其次分配从机柜上的其它节点分配container,如果还不行则从节点中任意node上分配container。 这就叫做YARN资源调配的本地化。这种模式节省了网络带宽,尽量让工作在本地完成。
ZooKeeper
在了解ZooKeeper之前先考虑几个问题,hadoop 相关的几乎所有产品都是分布式的,写一个分布式的程序要面临很多的难题,比如:
- 如何快速的知道系统中某一个节点挂掉
- 如何在集群间快速的统一配置信息
仅仅上面两个问题 实现起来就很难了,而且这种问题是集群application都需要解决的问题。所以hadoop 提供了一个统一的解决方案,ZooKeeper, 有了ZooKeeper, cluster application 所需要解决的一些问题,比如上面2个,都不需要你自己去写代码实现,可以直接使用 ZooKeeper 。
简单的概括一下,ZooKeeper 帮助 distributed application 各节点之间相互协作。 详细点说或者更晦涩一点说 ZooKeeper是一个集群式的,高可用的,树状文件系统,帮助分布式应用程序直接相互协调。 我们把这句话分割开来逐个理解,
“树状文件系统” , “帮助分布式应用程序” , “高可用” , “集群式”
File System
ZooKeeper 可以理解为一个树状文件系统 , 如这样:
/Zoo
/Zoo/Duck
/Zoo/Monkey
/Zoo/Bird/Aquila
根节点是Zoo , 子节点是 Duck,Monkey,Bird。 子节点可以存储数据,比如Duck 的名字 , ip 也可以存储下一级子节点 Aquila 。
Client
这里我们要先明确一个概念 client 。 ZooKeeper的目的是帮助distributed application相互协调,那么自然 其对应的 client 就是distributed application中的各个节点。
Znode
首先,ZooKeeper树状结构中的节点叫znode。Znode 有一些特性如操作原子性,有ACL属性等。 而 znode 有两种类型 ephemeral [ ɪˈfɛmərəl ] 和 persistent 。 从字面理解就知道 epehmeral 的特性就是不会永远保存。 这种节点在创建它的client 退出后就会消失。 但是在该节点存在期间,只要client 有ACL 权限,就可以看到该节点。
sequence number
Znode 有一个flag 叫sequence flag。如果 client 在创建 znode 的时候指定该 falg。 那么该znode 会被其parent node 赋予一个递增的唯一的 number。 比如一个client 创建了一个节点叫 /hbase/leader 并且设置了 sequence flag,那么第一次创建时该节点叫/hbase/leader-1 , 第二个client 也来创建/hbase/leader 并且也设置了 sequence flag,那么第二个创建的叫 /hbase/leader-2 。
Watch
ZooKeeper提供了一种叫watches的机制。你可以把它理解成关系型数据库中的trigger,这种watch 设置在znode上,基于某一些event 被trigger。 比如 你设置了exist watch 在一个znode /zoo/duck上面,那么一旦有节点创建了该znode,你就会被通知。
帮助 distributed application不同节点间协调工作
看完了 ZooKeeper 文件系统的本质,以及它两种Znode, Sequence number, Watches等特性,我们可以简单的举几个例子来理解ZooKeeper 如何帮助 distributed application 不同节点之间互相协调。
节点故障
在一个有多个节点的distributed application cluster中,如果某一个节点down 掉了,可以通过Zoo Keeper的 epehmeral 特性让集群能快速的知道。做法就是让每一个 node 都在ZooKeeper中创建 epehemeral znode,并且每个client 对其它client创建的 znode设置watch。 这样一旦某一个client down掉,也就是退出,那么对应的epehemeral znode消失 。 watch 触发,集群就可以了解到这一信息。
Leader elecation
在说这一内容之前,要知道 ZooKeeper自己也是集群程序,也存在选取leader的需求,但zookeeper自己对这一需求的实现和这一小段我们要讲的不同。 OK。 所谓Leader elecation是指集群程序中常常需要一个Master 节点,而为了避免单点故障,我们可能希望在Master节点出问题的时候余下的节点自动的顶上变为Master节点。但剩下的节点可能很多,选取哪一个就变成了我们这里需要解决的问题。
ZooKeeper 利用 Sequence Number的特性来实现。 以 Hbase 为例,假设要在多个Hbase 节点中找出一个设为Master节点,ZooKeeper的做法是让Hbase 中的节点在ZooKeeper中创建 /Hbase/Leader-n这样的节点,n是设置了sequence flag之后得到的值,哪一个节点获取的 n 最小则为master。
配置下发
在集群程序中,多个节点一般都要共享一些配置,如果实时的修改了这些配置,我们希望所有节点都能快速的得到通知。 ZooKeeper 用Watch 实现这个功能。 比如 Hbase 集群中Master 设置了一个配置项/Hbase/Conf/Mem 为8G 。 其它的节点在该znode上设置了watch,一旦客户修改了这个配置项,watch机制通知所有的client也就是hbase 集群中的其它节点。
高可用和集群
ZooKeeper的这两个特性可以放在一起说,因为他们是密切相关的。 ZooKeeper本身是一个集群应用程序,所以它自己要具有高可用的特性才能保证其它的distributed application 能够使用 。
ZooKeeper中有几个概念对高可用做出了支持。
majority
假设ZooKeeper中 有9个节点,那么5对于该集群就是majority。这个majority在zookeeper 中很多地方都会用到。所以zookeeper集群通常是奇数个的。
leader elecation
ZooKeeper中也有leader的角色。算法和zookeeper提供的对外支持的 leader elecation不同,我们只要了解 zookeeper在leader elecation的时候 只要majority的节点和leader 节点的信息同步了,就对外宣传 leader elecation选举完成。 未同步的zookeeper节点会在后面自动完成。
原子广播
ZooKeeper集群在更新一个Znode的时候是遵循以下流程的, client 提交更新申请给自己当前连接的zookeeper节点,如果改节点是Master 节点,则Master 节点像其它的zookeeper节点广播更新。 只要majority的节点更新完毕,就返回更新成功。这个过程是原子性的,因此对客户端来说只有两种可能1. 更新成功 2.更新失败 。 对于集群中其它没有更新的zookeeper节点,会在后面自动完成。
reject
如果client 连接到一个zookeeper去获取服务,而该zookeeper发现自己与master zookeeper的信息还没有同步,它会拒绝服务,这种情况client 就会再去连接其他的zookeeper。
Big Table
Hbase是基于Google 的Big Table 论文而得到的一个非关系型数据库分布式数据库,所以我们先了解一下BigTable论文中的主要内容。
DataModel
Big Table 所存储的数据叫做多维map。你可以理解为是关系型数据库中的表。跟表的类似,多维map也有row column的概念,但是除此还多了一个timestamp的概念。 由 rowKey,column,timestamp 能够唯一定位到一个 value。 可以这样理解, 像关系型数据库一样,rowkey 和 column 唯一定位到一个表格,该表格存着一个value。但是该表格可能存着很多个时间点的value,所以你还需要一个timestamp 去唯一定位一个value。
根据下图再理解一下这个模型。 为了简便这里称BigTable的多维map为表。
| --- | content | anchor:cnnsi.com | anchor:cisco.com |
|---|---|---|---|
| com.cnn.www | time1:value1,time2:value2 | time3:value3 | time8:value8 |
com.cnn.www 是Big Table中的rowkey。 conntent 和 anchor:cnnsi.com, anchor:cisco.com是 列。 这个表是用来存储网页的。
我们用url的倒叙作为rowkey,content列下面是该页面的内容。内容根据时间戳存储了多份儿,存储了不同时间点的内容。anchor:cnnsi.com 和 anchor:cisco.com 记录了外部链接连接到该URL的链接点。 比如 anchor:cnnsi.com 记录了 cnnsi.com这个URL上指向 cnn的链接点。同样的,根据不同的时间点,这里的值有多个版本。
你可能注意到anchor:cnnsi.com 和 anchor:cisco.com这两个列的名字都有一个冒号。BigTable中冒号前的这个anchor叫做column family。column family是在定义表的时候就创建好的并且在表存在期间不可变。content也是column family。 Big Table中在标识某一个列的时候要用 column_faimily:column_child的形式来指定。一个column family下有多个column_child. 虽然 column family 不可变且要提前创建,但是column_child是非常灵活的,不必提前创建,可以随时增加,甚至不同的row 可以具有不同的column_child。 比如上面的例子中,可能紧接着这行数据还存有一行数据如下
| --- | content:xml | content:html | anchor:cisco.com |
|---|---|---|---|
| com.cnn.news | time1:value1,time2:value2 | time3:value3 | time8:value8 |
这行数据的 rowkey 是com.cnn.news。 它的content column family下有两个子column 为xml 和html,而 anchor column family下只有一个 cisco.com。 这行的意思是 com.cnn.news这个URL 的content 有两种格式 XML 和 HTML。 我们都进行了存储,而只有一个 cisco.com 的外部链接指向该 url。
我们这两行数据, column family相同但具体的column却可以不同。
JSON形式理解多维map
我们可以借助JSON的形式再理解一下 BigTable的Data Model或者说Hbase的表结构。上面的例子可以逐步的用JSON来描述如下:
{
com.cnn.news:{
content:{}
anchor:{}
}
}
在第一维,我们的rowkey映射到两个 column family。column family 下面有多个column,我们继续补充
{
com.cnn.news:{
content:{
XML:
html:
}
anchor:{
cisco.com:
}
}
}
对content family我们在这行补充了 xml 和 html两个子列, 对anchor,我们在这一行增加了cisco.com 这个列。所以第二维是column family 映射到 column 。 我们由 rowKey , column family, column child映射到了具体的表格,或者说cell。cell 中存储的应该是value。
{
com.cnn.news:{
content:{
XML: value
html: value
}
anchor:{
cisco.com: value
}
}
}
value 是根据时间戳可以存储有多个版本的,所以再补充一个维度如下:
{
com.cnn.news:{
content:{
XML: {
time1:value1,
time2:value2
}
html: {
time3:value3
}
}
anchor:{
cisco.com: {
time8:value8
}
}
}
}
如上,就是一个BigTable/Hbase 数据模型的JSON展示。 com.cnn.news是row Key,唯一标识每一行记录。content 和 anchor是两个column family ,提前创建并且不可变。 XML, HTML , CISCO.COM这些是具体的column 。 不同的记录行可以有不同的column。 最后由 rowKey,column family,column定位到的value由根据时间戳存有多个版本。
BigTable 模型中所有的数据都以byte串的形式存储,有几个限制是column family必须是可打印的字符串。当有多个版本的value的时候,value基于时间戳排序,最新的value排在最上面,默认返回给客户的是最新的value。 同时每一行数据根据rowKey排序。这是非常重要的一点。因为BigTable中没有索引,所以利用好rowkey顺序存储这个概念对设计表非常有帮助。
比如上面例子中是用来存储网页的表。这个表中我们把url 倒叙作为rowkey。 如:
com.cnn.news
com.cnn.mail
com.cnn.www
这样设计的目的是相关联的URL 会被存放到一起,这样在使用数据的时候,相关联的数据可以很容易的取到。比如你想查询到CNN所有相关的网页。那么只要把com.cnn.这个前缀的ROW全部scan就可以了,他们都存放在一起 不需要在磁盘上随机寻址查找。
Rows
Big Table中存储的所有内容都是字节流。 Row 由 Row Key唯一标识。对一个Row的操作是原子性的,无论操作中包含多少个column family。 Row 在BigTable中的存储是基于RowKey排序好的。BigTable存储的数据通常很大,这些数据会按照RowKey 分成很多个partition。每一个Partation 在BigTable中叫做Tablet,在hbase中叫做region。 Tablet是负载均衡和数据分布的单位。通常一台机器上分布着多个tablet,而当某一台机器down掉,它所持有的tablet会被其他机器管理。基于rowkey排序以及tablet的特性,在设计BigTable的表时,可以利用这些特性获得较好的性能。 比如rowkey用URL倒序的形式,如 com.cnn.mail , com.cnn.www 那么同一个domain的网页就会存放到一起,这样在访问某一个domain的网页时也许只要访问集群中一小部分机器即可。
column family
Hbase或BigTable中在column 这一概念上多了一个column family的概念。通常在使用中,会把同一类的并且size差不多的column组合到同一个column family中。 BigTable是列式存储的,但其实更准确的说是 基于column family存储的。Column Family是BigTable中实施ACL控制的最小单元。
Cell
Cell 这个概念可以理解成表格。如果我们联系关系型数据库考虑。 BigTable中的rowKey 和 Column_family:column_id 就相当于 关系型数据库中的行列。根据行列可以唯一的定位到一个表格。不同的地方就是关系型数据库中的column对每一行来说都是固定的,而我们这里不是,并且,关系型数据库定位到表格就已经结束了,而我们的表格也就是cell下还有一个级别 version。
timestamp
上面的CELL中存储了BigTable中的value,准确的说是不同时间点的value。 BigTable中的timestamp可以精确到microseconds。value 是根据timestamp倒叙排序的。所以默认返回的是最新的value。 BigTable还支持针对timestamp的自动housekeep。比如你可以对某一个column family设置只保存最近的10个时间点的value或者只保存大于某个时间点的数据。
Building blocks
BigTable 运行在一系列的Google 基础设施上。比如底层的文件系统是GFS,类似于Hbase 运行于HDFS上。BigTable是一个集群程序,所以需要一个统一的资源管理器,这在Hadoop中叫YARN。 BigTable 的各个集群协调工作需要一个叫Chubby的程序,而在Hadoop中是zookeeper。
BigTable存储数据用到文件格式叫SSTable。我们知道BigTable是列式存储的,所以其实SSTable中存的是Column Family的数据。存的是键值对,而且是排好序的。SSTable还有一个特性是不可更改,即写入的数据只能读不能改。SSTable 对外提供了接口,可以根据key查询value,也可以在给定的key 范围里遍历所有的键值对。
在最底层SSTable 也是由多个block组成。而且在SSTable的底部还存着一个Block 索引可以快速的定位该SSTable文件内部的block 。 当打开一个SSTable的时候,把该索引load进内存,这样可以迅速的查找一下对应的数据块,然后就只进行一次磁盘读写。当然也可以把整个SSTable 读入内存。
Implementation
BigTable 主要由三部分组成。Master 节点 , Salave节点和 client或者说client的library。Master节点只有一个,salve节点或者说tablet服务器可以有多个而且可以动态的增删。Master节点主要负责如下事情:
分配tablet给tablet server
管理 tablet 服务器的增删 和 负载均衡
对底层文件系统GFS中的文件进行垃圾回收
管理 schema 的更改如 表 column family的增删改
tablet 服务器则负责以下事情:
对分配给自己的tablet的I/O 进行处理
当tablet 过大的时候进行split
因为tablet 服务器负责相应客户端的I/O请求,所以即使一个很大的集群,Master也不会有太多的压力。
Tablet location
我们用一个类似于Btree的三层结构来存储 tablet的位置信息。
Chubby File(ZooKeeper)/Root Tablet/(Meta Table) / User Table
第一层存储在Chubby File中,这里存着Root Tablet的位置信息,Root Tablet 存储着 MetaTable 其它所有tablet的信息,而 Meta Table 又记录着其它所有Tablet 的位置信息。 可能你会发现这好像是4层结构。但实际上 root tablet 是meta table的第一个tablet。 这个tablet有一个特性就是它永远不会split。
client library 会缓存 tablet的位置。如果没有缓存,也只需要3次查询就能找到tablet。
Tablet Assignment
Master 节点负责tablet 的分配。 Big Table 集群用Chubby 文件记录各个 tablet 服务器的状态。一旦某一个tablet serverdown掉。Master能迅速的知道并且把相应的Tablet 重新非配。
对于Tablet split的情况。是Tablet 服务器自己负责的,tablet split 后 , tablet 服务器会通知master节点相应的信息。
Tablet Serving
Tablet 的数据存在GFS的 SSTable中。如果有数据更改,这些更改先会写入redo log,然后写入内存中一个叫memtable的结构中。memtable 和 SSTable 其实是一种东西不过前者在内存中后者存在硬盘上。
恢复 Tablet:
BigTable 先从 metadata 表中找到这个tablet对应的SSTable 和 redo 信息,然后把 SSTable读入内存然后应用redo,这样就完成了对Tablet的恢复。
write 操作
BigTable先进行权限校验然后把write写入redo log ,再然后把内容写入memtable。
read操作
同样也是进行权限校验。然后把该tablet 的memtable 和对应的 SSTable进行merge后读入内存。
update操作
我们知道 SSTable 是不可更改的。所以update操作跟传统的RDBMS 不同。BigTable的更新是在对应的cell中插入一个时间戳更新的值。如果你想更新某一个时间戳的值。
Compaction
memtable 存在内存中,所以其大小是有限制的。当memtable内容越来越多,增长到threshold,memtable 就会存到硬盘上以SSTable的形式存在。这个操作叫做minor compaction。 这个操作有两个目的:
控制内存增长
一旦该tablet server down掉,在恢复对应Tablet的时候可以少做一些工作。因为大部分的MemTable数据已经写入硬盘。
我们知道read 操作是把一个tablet 对应的memtable 和 SSTable merge后读入内存。那么如果一直进行minor compaction,一个Tablet就会有很多个SSTable。 这样会造成很多问题,read 的开销就是其中之一。实际上,在BigTable的后台也会进行merge。会把一系列的MemTable和SSTablemerge成一个大的SSTable。然后丢弃之前的SSTable。
如果一个compaction会合并一个tablet下所有的SSTable 和Memtable,那么这个compaction叫 major compaction。 普通的compaction 不会删掉你用delete操作删除的数据 。 在BigTable中 delete操作只是对相应的数据做了一个标记,标记为删除,但数据还是会存在于系统中。major compaction才会真正的把这些数据删除。
Refinement
BigTable 在设计上为了得到高性能和稳定性有一些独特的地方,这里讲详细介绍。
Locality Groups
BigTable中有locality groups的概念,即client可以指定几个column family组成locality,这样这几个column family在存储的时候将会存在一起,比如存在一个SSTable中。这样在读取的时候会获得比较好的I/O特性,比如在存储页面的webpage 表中。我们将页面的原信息 metadata 存在一个 locality group中,将页面的内容page存在一个locality gropu中。内容通常非常大,这样我们在想读取原信息的时候就不必访问page column。 这和传统的关系型数据库不一样。传统数据库如 oracle 是行是存储,一个row中的所有数据都存在一起,即使你只需要访问该row中的某一列,你也需要读取整个row 。
另外可以基于locality group做一些设置,比如设置某一个locality group常驻内存,这样对于经常使用的一些小的元数据, 查找起来就会非常方便。 实际上 metadata 表就是常驻内存的。
hbase
要注意的是hbase在实现的时候没有采用locality group的概念,而是天然的每一个 column family就是一个locality group。
Cache
BigTable采用了两级cache 机制。
第一级 scan cache
这一级别的cache 缓存了SSTable 接口中返回的key value对的信息。
第二级 block cache
这一级别的cache 缓存了GFS 文件系统中返回的datablock块的信息。
第一级的cache对那些反复读取相同数据的操作很有帮助,而第二级的cache 对那些 "读取刚刚读取过的数据周边数据"的操作有帮助。
Bloom filter
在前面的read 操作中我们介绍过。read操作要先校验权限,然后找到该tablet对应的所有SSTable和 memtable然后把这些数据merge读入内存。这是一个开销很大的操作,比如很多SSTable如果不在内存则需要从硬盘读取然后进行merge 。
BigTable 引入了bloom filter的机制,允许对某一个或某一些locality group 设置布隆过滤器。Bloom 过滤器的特性是支持快速的查询某一个数据是否在一个集合中。对于在集合的情况,查询结果是100%正确的,但对于不在集合的情况则有一定的概率查询错误。
比如 有集合A,和元素a,b,c。 a在集合中而b,c不在集合。 那么调用布隆过滤器查询abc是否在集合的情况可能如下:
bloom(a,A) = True (查询100%准确)
bloom(b,A) = True (查询错误,其实不在但是返回了在)
bloom(c,A) = False (查询正确 准确率不是100%准确)
因为bloom 过滤器可以快速断定一个元素是否在对应的SSTable中,所以在read操作的时候可以快速的识别某一些SSTable 是否需要读入内存。 虽然有的时候会发生错误即元素不在SSTable中,但还是读取了相应的SSTable。但这样总比读入所有的SSTable要好。
Immutable
SSTable 是不可改变的。这带来了一些好处如。
read不需要sync
传统的数据库文件是可以随时读写的,而在写的时候数据不是实时存入文件而是缓存在磁盘中,那么在读该文件的时候需要先同步一次,把内存中的数据写入磁盘。