一、子查询
1.为什么要使用子查询:问题不能一步求解或者一个查询不能通过一步查询得到。
2.分类:单行子查询和多行子查询。
3.子查询的本质:一个查询中包含了另外一个或者多个查询。
4.使用子查询的规则:
(1)可以在主查询的where、select、from、having的后面放置子查询,但是不可以在在group by后面防止子查询。
(2)将子查询放到括号中去。
(3)强调from后面放置子查询。
(4)主查询和子查询使用的可以不是同一张表。
(5)一般不在主查询中使用order by,但是在Top-N问题中,必须使用order by
(6)一般先执行子查询后执行主查询,但是相关子查询除外。
(7)单行子查询只能使用单行操作符,多行子查询只能使用多行操作符。
(8)在子查询中涉及到NULL值的时候十分容易出错。
(9)SQL优化:如果子查询和多表查询都能达到相同的目的,那么最好使用多表查询,这样查询效率更高。
二、子查询的使用
1.可以在主查询的where、select、from、having的后面放置子查询,但是不可以在在group by后面防止子查询。
(1)select后面放置子查询
select empno,ename,(select job from emp where empno=7934) from emp
结果没有很大的意义,但是说明了可以在select后面防止子查询。
(2)强调from后面放置子查询。
select * from (select * from emp where deptno=30)
得到的结果是30号部门的全体员工。
2.主查询和子查询使用的可以不是同一张表只要子查询的返回结果主查询可以使用即可。
select * from emp where deptno=(select deptno from dept where dname='SALES')
得到的结果是所有emp表中部门号相对应的部门名称是'SALES'的员工信息。
使用多表查询同样能得到相同的结果。
select emp.* from emp,dept where dept.dname='SALES' and emp.deptno=dept.deptno
如上面所说的,在使用子查询和多表查询都能达到相同目的的时候尽量使用多表查询,这样执行效率会更高。
3.单行比较操作符:=,>,>=,<,<=,<>,其中2中的子查询使用的是但行比较操作符的=
4.多行操作符:in、any、all
in操作符举例:
select * from emp where deptno in (select deptno from dept where dname='SALES' or dname='ACCOUNTING')
查询所有所在部门为SALES或者ACCOUNTING的员工信息。
5.子查询中所有的多行操作符都能转化为组函数
例:查询工资比30号部门所有员工都要高的员工信息。
(1)使用多行子查询
select * from emp where sal > all(select sal from emp where deptno=30)
(2)使用组函数
select * from emp where sal > (select max(sal) from emp where deptno=30)
两者的查询结果完全相同(条目顺序有所改变),也就是说大于所有相当于大于最大;小于所有相当于小于最小,大于任意相当于大于最小,小于任意相当于小于最大。
6.查询不是老板的员工信息。
如果是照层次查询的观点来说,相当于查询叶子节点,也就是没有子节点的节点。
select * from emp where empno not in (select mgr from emp)
查询结果是未选定行。
出现问题的原因是什么?
这和in 与not in的工作原理有关系。
7.in与not in
(1)not in:
select * from emp where empno not in (select mgr from emp)
结果:

(2)in:
select * from emp where empno in (select mgr from emp)
这相当于查询除了是老板的员工信息。

(3)为什么in能查询出结果但是not in却不行?
原因分析:in 相当于 any,但是not in 相当于all。
in的逻辑关系实际上是or的关系,而not in 实际上是and的关系
expr or null,只要expr不为null结果就不为null,但是如果是expr and null,无论expr是什么值,结果一定都是null,where null 表达式的值是NULL。
观察一个SQL语句:
select mgr from emp
运行结果:
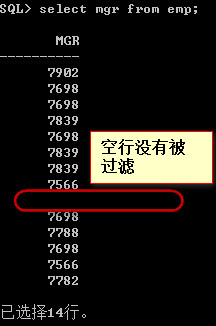
也就是说正因为没有过滤空行,才导致了not in 的子查询失败。
(4)解决NOT IN 子查询中的空值问题
select * from emp where empno not in(select mgr from emp where mgr is not null)
运行结果:

三、集合查询
1.什么是集合查询
集合查询就是使用三种集合操作符将两个或者两个以上的查询语句连接起来成为一条查询语句的查询方法。
2.三种集合运算符
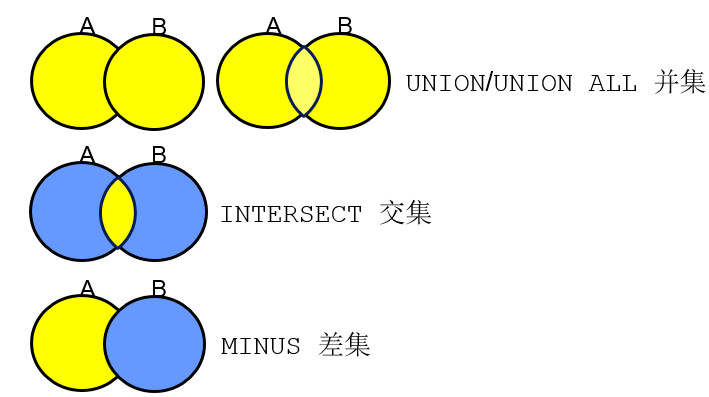
注意差集使用的关键字是MINUS,而不是EXCEPT。
3.集合查询的注意事项
(1)select语句中参数类型和个数要一致。
(2)可以使用括号改变集合执行的顺序
(3)如果有order by子句,必须放到每一句查询语句后
(4)集合运算采用第一个语句的表头作为表头
四、集合查询的使用
1.union的使用
(1)查询10号部门和20号部门的员工信息
不使用集合查询:
select * from emp where deptno=10 or deptno=20
select * from emp where deptno in(10,20)
使用集合查询:
select * from emp where deptno=10 union select * from emp where deptno=20
(2)通过union实现group by 增强。
曾经使用rollup函数进行过报表功能的测试实验:
select deptno,job,sum(sal) from emp group by rollup(deptno,job)
执行结果:

现在拟使用union连接几个查询语句并最终实现和该函数相同的查询结果。
分析:
最后的29025一定是根据
select sum(sal) from emp
得到的;
通过
select deptno,sum(sal) from emp group by deptno
可以得到每个部门的工资总和。
通过
select deptno,job,sum(sal) from emp group by deptno,job
则可以得到每种部门下每种职位的工资总和。
使用union将三个sql语句进行连接,得到的SQL语句为:
select deptno,job,sum(sal) from emp union select deptno,sum(sal) from emp union select sum(sal) from emp
查询结果是:
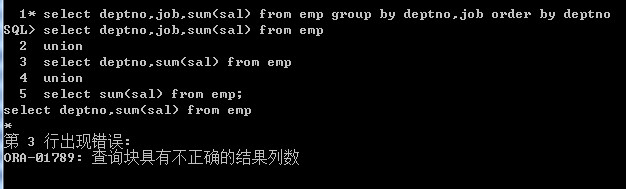
为什么会出现这个错误呢?
原因在与集合查询的注意事项的第一条:每个集合查询的select的参数的个数和类型要完全一致,这里不仅参数个数不相同,而且参数类型也不一致。
(3)使用union连接sql语句模拟rollup函数的最终解决方案。
select deptno,job,sum(sal) from emp group by deptno,job union select deptno,to_char(null),sum(sal) from emp group by deptno union select to_number(null),to_char(null),sum(sal) from emp
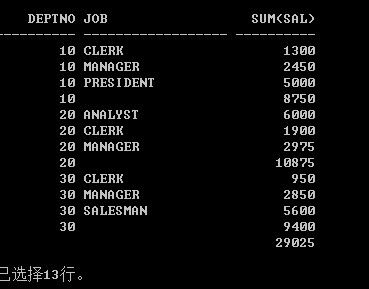
使用to_char函数和to_number函数的目的就是解决类型不匹配的问题,如果只是填充了null作为占位符,则还是会有类型不匹配的问题的,也就是说null也有不同类型。
使用break on deptno skip 2进行格式化一下更为直观好看。

2.分析使用union模拟rollup函数的sql效率
使用union连接介个sql语句可以达到和rollup函数相同的效果,那么使用前者效率更高呢还是使用后者效率更高?
第一步:使用set timing on 命令开启运行时间统计功能。
第二步:使用rollup函数,统计运行时间(运行10次求平均值)

运行十次,平均值为:(0+30+30+30+30+30+30+40+40+40+40)/10=34ms
第三步:使用union连接sql语句模拟rollup函数

(40*8+30*2)/10=38ms
最后一步:总结
好吧,其实这里差距不算大,但是在oracle 10g的时候差距还是很明显的,oracle 10g中使用union要比使用rollup函数效率要高很多。
五、处理数据
1.数据库中的语言分类
(1)DML:Database Manipulation Language 数据操纵语言
INSERT、UPDATE、DELETE、SELECT
(2)DDL:Database Definition Language 数据定义语言
CREATE/ALTER/DROP/TRUNCATE TABLE
CREATE/DROP VIEW
CREATE/DROP INDEX(SEQUENCE,SYNONYM)
(3)DCL:Database Control Language 数据控制语言
2.地址符&
(1)首先拷贝emp表中的数据结构和数据到一个新表emp1中。
CRATE TABLE EMP1 AS SELECT * FROM EMP;
(2)向emp1表中插入一条数据
insert into emp1(empno,ename) values(&empno,'&ename');
运行效果:
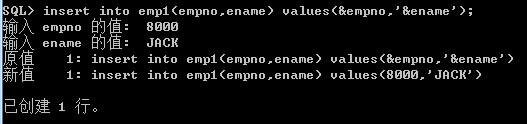
如果还想继续插入新的值,只需要在命令行中输入/继续执行上一条语句就可以了,这样就极大简化了书写。
(3)&符号还能在select语句中使用。
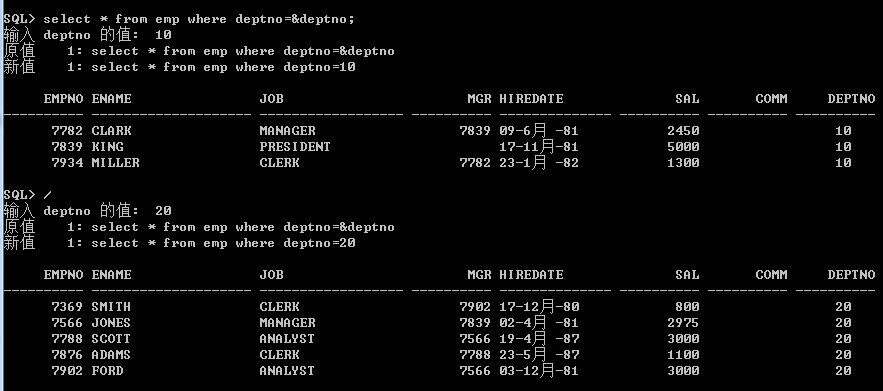
select * from emp where deptno=&deptno;
运行效果:
3.批量拷贝表数据创建新表。
CREATE TABLE EMP1 AS SELECT * FROM EMP;
该命令的作用就是拷贝emp表的表结构和表数据到emp1中。
4.truncate与delete命令
TRUNCATE TABLE EMP1;
和
DELETE FROM EMP1;
两条命令的作用都是将EMP1表清空,但是两者又有几处不同:
(1)delete是DML,truncate是DDL (DML可以rollback,DDL不可以)
(2)delete逐条删除;truncate先摧毁,再重建
(3)delet会产生碎片;truncate不会
(4)delete不会释放空间;truncate会
5.truncate 和delete命令效率比较。
逻辑上来说truncate命令效率要比delete命令高,但是事实上在oracle中truncate命令效率并不如delete命令,因为delete命令更常用,所以oracle命令做了优化。
可以送大数据量的表进行测试。测试之前最好关闭oracle的反馈机制。
set feedback off命令:关闭oracle的反馈日志信息显示。
六、Oracle中的事务
1.事务的起始标识:DML语句
2.事务的结束标识
(1)提交
[1]显示提交:commit
[2]隐式提交:DDL语句
[3]正常退出:exit
(2)回滚
[1]显示:rollback
[2]隐式:非正常退出、掉电、宕机
3.SQL语句
(1)提交:commit
(2)普通回滚:rollback
(3)建立保存点:savepoint xxxx
(4)回滚到指定的保存点:rollback to savepoint xxxx
七、修改表
1.添加列
alter table emp1 add address varchar2(20);
2.修改列
alter table emp1 modify address number;
3.删除列
alter table emp1 drop column address;
4.重命名列
alter table emp1 rename column address to photo
八、删除表
1.使用drop table xxxx命令删除表的时候并没有真的将表彻底删除,而只是将表放到了回收站中,类似于windows中的delete快捷键。
2.使用drop table xxxx purge命令将表彻底删除,类似于windows中的shift+delete快捷键。
3.查看回收站命令:show recyclebin
4.清空回收站命令:purge recyclebin

九、约束
1.check约束
create table people ( ...... sex varchar2(10) check(sex in('男','女')) ...... )
2.其余约束
create table people ( pid varchar2(10), pname varchar2(30) not null, psex varchar2(4), email varchar(30), deptno number, constraint people_pid primary key (pid),/*表级主键约束*/ constraint people_psex check (psex in('男','女')),/*表级check约束*/ constraint people_email unique(email),/*表级唯一性约束*/ constraint people_deptno foreign key (deptno) references dept(deptno) on delete set null/*表级外键约束*/ )
十、视图
1.创建视图
CREATE VIEW VIEW1 AS SELECT * FROM EMP;
2.使用视图的好处
(1)限制数据访问
(2)简化复杂查询
(3)提供数据的相互独立
(4)同样的数据可以有不同的显示方式
3.注意事项:强烈不建议通过视图实现DML操作。
4.创建视图的时候带有with check option选项:
举例说明:
create view view2 as select * from emp where deptno=40
创建了一个这样的视图,如果加上
with check option
的话,如果想要对该视图进行DML操作的话,如insert,则只能插入deptno=40的sql语句了。

5.创建视图的时候带有with read only选项:屏蔽掉对视图的DML操作,任何DML操作都会返回一个Oracle server的错误。
6.使用create or replace SQL语句修改视图。
十一、序列
1.什么是序列:可供多个用户用来产生唯一数值的数据库对象
2.序列的特点:
(1)自动提供唯一的数值
(2)共享对象
(3)主要用于提供主键值
(4)将序列值装入内存可以提高访问效率。
3.定义格式:
CREATE SEQUENCE sequence
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}]
[{CACHE n | NOCACHE}];
举例创建一个序列:
create sequence se start with 1 increment by 1 nocycle nocache
4.查询创建的序列
select sequence_name from ALL_SEQUENCES; select sequence_name from USER_SEQUENCES; select sequence_name from DBA_SEQUENCES;
5.使用创建的序列
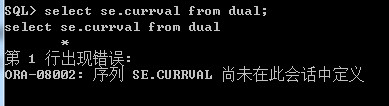
(1)sequence_name.currval:当前的序列值,如果刚创建完序列,则第一次必须先使用nextval才行,否则会报如下错误:
(2)sequence_name.nextval:下一个序列值,每使用该sql语句一次se序列值就会自动增加(按步长)。
(3)在向表中插入数据的时候使用该值作为主键。
表结构:
create table people ( pid number, pname varchar2(15), constraint pk_people primary key(pid) )
插入数据:
insert into people(pid,pname) values(se.nextval,'小强');
(4)使用序列有可能会出现“缝隙”:回滚、系统异常、多个表同时使用同一个序列
(5)可以使用alter语句修改序列对象,但是不能修改序列的初始值,想要修改序列的初始值只能通过删除序列之后重新创建来实现。
十二、同义词
1.同义词:使用同义词访问相同的对象
2.使用同义词的好处
(1)方便访问其他用户的对象
(2)缩短对象名字的长度
(3)更加安全
3.创建同义词
CREATE [PUBLIC] SYNONYM synonym FOR object;
举例:
create synonym emp_hr for hr.employees;
由于scott权限级别很低,所以需要管理员赋予创建同义词的权限:grant create synonym to scott;
以及hr赋予scott以查询employees的权限:grant select employees to scott;
4.使用同义词。
select * from emp_hr;
5.查看创建的同义词:
SELECT * FROM USER_SYNONYM;
6.删除同义词:使用drop语句即可。