PANDAS 的使用
一.什么是pandas?
1.python Data Analysis Library 或pandas 是基于numpy的一种工具,该工具是为了解决数据分析人物而创建的。
2.pandas纳入了大量库和一些标准的数据模型,提供了高效的操作大型数据集的工具
3.pandaas提供了大量能使我们快速便捷的处理数据的函数和方法。
4.pandas使python成为了强大高效的数据分析环境的重要因素之一。
5.SPSS数据分析工具IBM 1g excel
6.panda数据预处理
二pandas的数据结构
1.数据分析三剑客:numpy,matplotlib ,pandas
①.pandas中series类
series是一种类似于一维数组的类对象,由下面两部分组成
1.velues:一组数据(ndarray类似)
2.index:相关的数据索引
Series属性
Series(['data=None', 'index=None', 'dtype=None', 'name=None', 'copy=False', 'fastpath=False'],)
series的创建有两种创建方式
(1)由列表或numpy数组创建(默认索引为0到整数型索引,还可以通过设置index参数指定索引)
格式:Series(data,index)
(2)由字典创建
格式:Series({key:value})
注意:由ndarray创建的是引用,而不是副本,对series元素的改变也会改变原来的ndarray对象中的元素。
如:s2 = Series({"A":148,"B":130,"C":118,"D":117,"E":99},dtype=np.float32,name="python")
s2
输出结果:
A 148.0
B 130.0
C 118.0
D 117.0
E 99.0
Name: python, dtype: float32
Series的索引和切片
可以使用括号取单个索引(此时返回的是元素的类型),或者中括号中一个
列表取多个索引(此时返回的任然是一个series类型)。分为显示索引和影视索引:
1显示索引:
--使用index中的值作为索引值
--使用.loc[](推荐)
注意:此时是闭区间
2.隐式索引:
--使用整数作为索引值
--使用.iloc[](推荐)
注意:此时是半闭区间
Series的基本概念
可以把series看成是一个定长的有序字典
可以通过shape,size,index,values得到series的属性
Series的方法
可以通过head(),tail()快速查看series的样式
head(num)返回一个前num列数据
tail(num)返回后num列的数据
当索引没有对应的值时,返回NaN(NOT A NUMBER)值
可以使用pd.isnumm(),pd.notnull()的方式来检测数据的缺失
如 cond = s5.isnull()
S6 = index(cond)
Series的运算
(1)使用于numpy的数组运算也适用于series
(2)series之间的运算
在运算中自动对齐相同的索引的数据
如果索引不对应,则补NaN
注意:要想保留所有的index,则需要使用.add()函数
二.DataFrame数据结构
- DataFrame是一个【表格型】数据结构,可以看做是由series组成的字典,将series的使用场景从一维拓展到多维。dataframe既有行索引也有索引
Init signature: DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
行索引:index
列索引:columns
值:values
2.dataframe的创建
同series一样,两种创建方式
dataframe以字典的键作为每一列的名称,以字典的值作为每一列的值。dataframe会自动为每一行添加行索引(和series一样)。
如:
df = DataFrame(data = np.random.randint(0,150,size=(10,4)),index = list("abcdefghij"),columns = ["python","math","english","chiness"])
df2=DataFrame(data={"python":np.random.randint(0,150,size=10),"math":np.random.randint(0,150,size=10),"chinese":np.random.randint(0,150,size=10),"english":np.random.randint(0,150,size=10)})
DataFrame的索引和切片
注意:索引表示的列索引,切片表示的行切片
1.索引
(1)对列进行索引,列索引是属性,行索引是样本
使用类似字典的方式
使用属性的方式
df[“python”],df2[["python","math"]]
df.python
(2)对行进行索引
.ix[]进行行索引
使用.loc[]加index来进行行索引
使用.iloc[]加整数数类进行行索引
返回一个series,index为原来的columns
如:df2.loc[1]
df.iloc[“a”]
df2.loc[[1,2,3]]
(3)对元素索引的方法
先获取行在获取列,如:df.loc["a"]["python"]
先获取列在获取行,如:df["python"]["a"]
二维形式进行获取单个值,如:df.loc["a","python"];df2.iloc[0,0]
- 切片
(1)列切片:如df.iloc[:,2:];df[["python","math"]]
(2)行切片:直接切片或使用loc(),iloc()如:df[1:2];df.iloc[2:5];df.loc["a":"b"]
3.dataframe的运算
下边python操作符合pandas操作函数的对应表
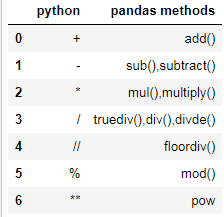
(1)同series一样
在运算中自动对齐相同的索引
如果索引不对应,则用nan补全
(2)series与dataframe之间的运算(重要)
使用python操作符:以行为单位操作(参数必须是行),对所有行都有效。(类似与numpy中二维数组与一维数组的运算,但是可能出现nan值)
注明axis,运算时指明对齐索引
使用pandas操作函数:
axis=0:以列为操作单位(参数必须是列),对所有列都有效。
axis=1:以行为操作单位(参数必须是行),对所有行都有效
如:df5.add(ss,axis=0)