前言
现在又有了新的需求:果厂里新进了一批进口水果:进口香蕉,进口苹果,进口梨,同样的是需要采集水果,之前的程序只是对工厂进行了抽象,使得不同的产品对应各自的工厂,而产品仅是国内水果,现在涉及到了进口水果,现在有了两大类的产品,每个产品又分为不同的等级,我们叫它产品族。
产品族概念
所谓产品族,是指位于不同产品等级结构中,功能相关联的产品组成的家族。
1、每一个产品族中含有产品的数目与产品等级结构的数目是相等的
2、产品的等级结构与产品族将产品按照不同方向划分,形成一个二维的坐标系。
横轴表示产品的等级结构,纵轴表示产品族。
3、只要指明一个产品所处的产品族以及它所属的等级结构,就可以唯一的确定这个产品。
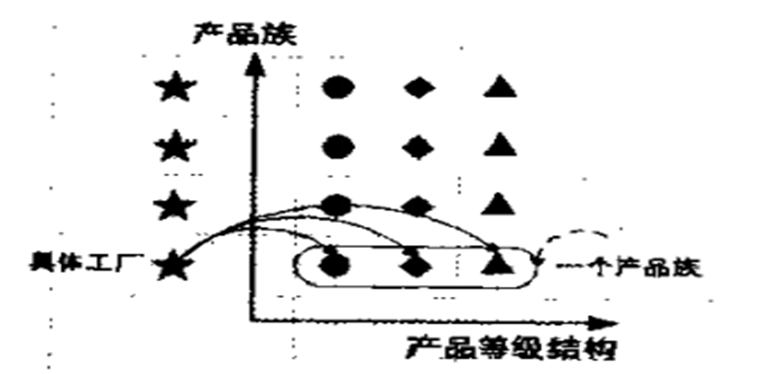
1、国产水果和进口水果就是产品族(纵坐标)
2、苹果,香蕉,鸭梨等,就是产品的等级结构,具体每个产品族的等级
这个业务就相对复杂了,所以之前的模式就变得不好用。如果硬要使用,那就是在具体的苹果工厂类里再增加一个新的方法——返回进口苹果类的实例,同时也为进口苹果增加对应的进口苹果类,同理对于香蕉,鸭梨也是一样的,好像也没什么问题。
引入抽象工厂模式
现在需求又变了,果园厂增加了温室种植技术,有了一种新的产品——温室种植水果。如何写代码?
按照工厂方法模式的写法,自然就要在具体的苹果工厂类里再增加一个新的方法——返回温室苹果类的实例,同时也要增加温室苹果这个新的产品……其他水果工厂类是一样的做法。这明显违背了 OCP 原则,而且苹果工厂类既能生成进口苹果也能生产国产苹果,违背了单一职责原则。此时抽象工厂模式就派上了用场。
1、抽象工厂模式是所有形态的工厂模式中最为抽象和一般性的。
2、抽象工厂模式可以向客户端提供一个接口,使得客户端在不必指定产品的具体类型的情况下,能够创建多个产品族的产品对象。
抽象工厂模式实现
水果厂有进口水果,国产水果两个产品族,而具体获得哪个产品族是客户端调用决定的。比如,进口苹果,进口橘子,国产苹果,国产橘子等……苹果,橘子是产品族(y轴)拥有的产品等级(x轴),客户端可以调用某个产品族的某个产品,之前的工厂方法模式,就对应一个产品族的设计模式,只有一个水果工厂去维持各水果实体类(产品等级),只有x轴,没有y轴,客户端采集进口苹果,调用的是原先国产苹果工厂里新增加的进口苹果生产方法……很别扭
采用抽象工厂模式,就需要维持一个 y 轴,解耦各个产品族,提供一个接口给客户端,让客户端能在不指定具体类型的前提下,创建多个产品族……
代码如下:
一个水果的接口,维持一个获得水果的规则,所有产品等级对象的父类(接口),它负责描述所有实例所共有的公共接口
public interface Fruit { void get(); }
对应产品等级的结构:苹果和香蕉组成一个产品族的产品等级,这里升华为水果的抽象类,是具体产品的父类
public abstract class AppleA implements Fruit { // 因为横向x轴的产品等级,有苹果,香蕉,但是多了纵向的其他产品族的苹果,香蕉,那么产品的抽象要进一步体现出来,苹果类变为 // 抽象基类,分别去维持多个和苹果相关的产品族对应的产品等级 public abstract void get(); } public abstract class BananaA implements Fruit { public abstract void get(); }
具体的产品
public class ForeignApple extends AppleA { @Override public void get() { System.out.println("进口苹果"); } } public class ForeignBanana extends BananaA { @Override public void get() { System.out.println("进口香蕉"); } } public class HomeApple extends AppleA { @Override public void get() { System.out.println("国产苹果"); } } public class HomeBanana extends BananaA { @Override public void get() { System.out.println("国产香蕉"); } }
抽象工厂类——抽象工厂模式的核心,包含对多个产品等级结构的声明,任何具体工厂类都必须实现这个接口
// 一个抽象的工厂类(这里是接口)去维持产品族——y轴 public interface FruitFactory { // 每一个工厂子类(产品族)都有对应的获得产品等级的方法——x轴 Fruit getApple(); Fruit getBanana(); }
具体工厂类是抽象工厂的一个实现,负责实例化某个产品族中的产品等级的对象
public class ForeignFruitFactory implements FruitFactory { @Override public Fruit getApple() { return new ForeignApple(); } @Override public Fruit getBanana() { return new ForeignBanana(); } } public class HomeFruitFactory implements FruitFactory { @Override public Fruit getApple() { return new HomeApple(); } @Override public Fruit getBanana() { return new HomeBanana(); } }
客户端调用
public class Main { public static void main(String[] args) { // 获得某一个产品族 FruitFactory fruitFactory = new ForeignFruitFactory(); // 获得该产品族下的产品等级 Fruit apple = fruitFactory.getApple(); apple.get(); Fruit banana = fruitFactory.getBanana(); banana.get(); // 获得国产水果产品族 FruitFactory homeFruitFactory = new HomeFruitFactory(); // 获得该产品族下的产品等级 Fruit apple1 = homeFruitFactory.getApple(); apple1.get(); Fruit banana1 = homeFruitFactory.getBanana(); banana1.get(); } }
当以后引入温室水果的时候,除了必须要建立温室苹果类,温室香蕉类去继承对应的水果抽象类之外,只需要再建立一个温室水果工厂类去实现抽象工厂接口即可,已经存在的代码不需要修改。
类图如下
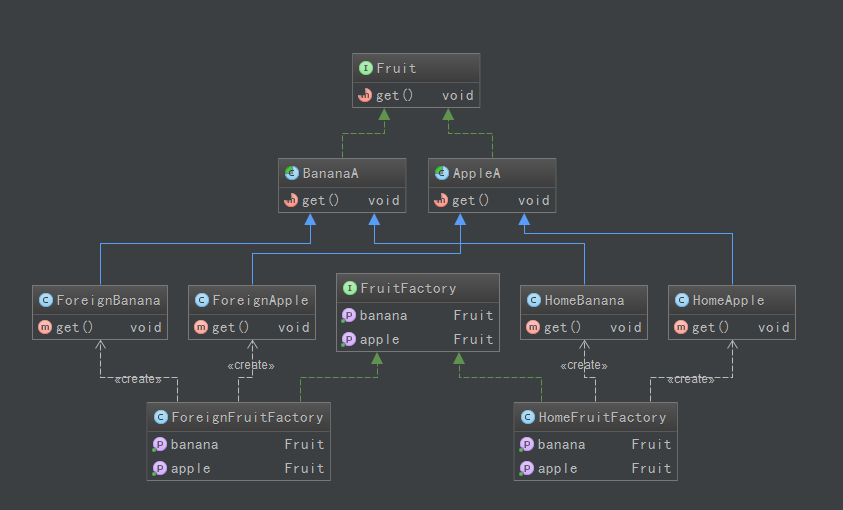
1、抽象工厂模式中的方法对应产品等级结构,具体子工厂对应不同的产品族。
2、产品族,简单理解就是不同的产品类型
3、产品等级结构,简单理解就是一个产品类型里的具体的产品
抽象工厂模式的优缺点
优点
1、分离接口和实现
客户端使用抽象工厂来创建需要的对象,而客户端根本就不知道具体的实现是谁,客户端只是面向产品的接口编程而已。也就是说,客户端从具体的产品实现中解耦
2、使切换产品族变得容易
因一个具体的工厂实现代表的是一个产品族,切换产品族只需要切换一下具体工厂
缺点
不太容易扩展新的产品,如需要给整个产品族添加一个新的产品,那么就需要修改抽象工厂(增加新的接口方法),这样就会导致修改所有的工厂实现类。比如增加橘子这个产品等级……
也就是说,纵向不怕扩展,横向不方便扩展
抽象工厂模式和工厂方法模式对比
抽象工厂模式与工厂方法模式的最大区别就在于,工厂方法模式针对的是一个产品等级结构(苹果,鸭梨,橘子……)
而抽象工厂模式则需要面对多个产品等级结构(进口、国产、温室栽培……的苹果,鸭梨,橘子……)
什么情况下使用抽象工厂模式?
系统的产品有多于一个的产品族,而系统只消费其中某一族的产品
JDK中使用抽象工厂模式的例子
常见有:DocumentBuilderFactory 使用了抽象工厂模式:使程序能够从 XML 文档获取生成 DOM 对象树的解析器
DOM:Document Object Model 的缩写,即文档对象模型。XML将数据组织为一颗树,所以 DOM 就是对这颗树的一个对象描叙。
通俗的说是通过解析 XML 文档,为 XML 文档在逻辑上建立一个树模型,树的节点是一个个对象。通过存取这些对象就能够存取 XML 文档的内容。
我们来看一个简单的例子,看看 DocumentBuilderFactory 是如何使用的抽象工厂模式来操作一个 XML 文档的。这是一个XML文档:
<?xml version="1.0" encoding="UTF-8"?> <messages> <message>Good-bye serialization, hello Java!</message> </messages>
把这个文档的内容解析到 Java 对象,供程序使用。
首先需要 DocumentBuilderFactory 建立一个解析器工厂,利用这个工厂来获得一个具体的解析器对象,获取 DocumentBuilderFactory 的新实例。用下面这个 static 方法创建一个新的工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
newInstance 方法源码如下
public static DocumentBuilderFactory newInstance() { return FactoryFinder.find( /* The default property name according to the JAXP spec */ DocumentBuilderFactory.class, // "javax.xml.parsers.DocumentBuilderFactory" /* The fallback implementation class name */ "com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl"); }
在这里使用 DocumentBuilderFacotry 抽象类的目的是为了创建与具体解析器无关的程序,当 DocumentBuilderFactory 类的静态方法 newInstance() 被调用时,它根据一个系统变量来决定具体使用哪一个解析器。
当获得一个 DocumentBuilderFactory 工厂对象后,使用它的静态方法 newDocumentBuilder() ,可以获得一个 DocumentBuilder 对象。
DocumentBuilder db = dbf.newDocumentBuilder();
DocumentBuilder,也就是 db 这个对象,代表了具体的 DOM 解析器(具体的某个产品族),但具体是哪一种解析器,比如微软的或者IBM的,对于程序而言并不重要。
获取此类实例之后,将可以利用这个解析器来对XML文档进行解析:
Document doc = db.parse("xxx.xml");
这个解析器可以从各种输入源解析 XML,这些输入源有 InputStreams、Files、URL 和 SAX InputSources,这些输入源就是产品等级(具体的产品),不同的解析器(实现)就是产品族,又因为所有的解析器都服从于 JAXP 所定义的接口,所以无论具体使用哪一个解析器,调用者的(客户端)代码都是一样的。
当在不同的解析器之间进行切换时(各个解析器就是不同的产品族,比如有微软的解析器,有IBM的解析器……),只需要更改系统变量的值,而不用更改任何代码。这就是抽象工厂所带来的好处,非常巧妙。
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!
