基数排序思想
完全不同于以前的排序算法,可以说,基数排序也叫做多关键字排序,基数排序是一种借助“多关键字排序”的思想来实现“单关键字排序”的内部排序算法。
两种方式:
1、最高位优先,先按照最高位排成若干子序列,再对子序列按照次高位排序
2、最低位优先:不必分子序列,每次排序全体元素都参与,不比较,而是通过分配+收集的方式。
多关键字排序
例:将下表所示的学生成绩单按数学成绩的等级由高到低排序,数学成绩相同的学生再按英语成绩的高低等级排序。
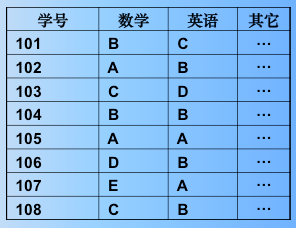
第一个关键字是数学成绩,第二个关键字是英语成绩,每个记录最终的位置由两个关键字决定。我们将它称之为复合关键字,即多关键字排序是按照复合关键字的大小排序。
多关键字排序的方法:
n 个记录的序列 {R1, R2, …, Rn} 对关键字 (Ki0, Ki1, …, Kid-1) 有序是指:对于序列中任意两个记录 Ri 和 Rj (1≤i < j≤n) 都满足下列(词典)有序关系:(Ki0, Ki1, …, Kid-1) < (Kj0, Kj1, …, Kjd-1) ,其中:K 0 被称为 最主位关键字, Kd-1 被称为最次位关键字。多关键字排序按照从最主位关键字到最次位关键字或从最次位关键字到最主位关键字的顺序逐次排序,分两种方法:
最高位优先法,简称 MSD 法:先按 k 0 排序分组,同一组中记录,关键字 k 0 相等,再对各组按 k 1 排序分成子组,之后,对后面的关键字继续这样的排序分组,直到按最次位关键字 k d 对各子组排序后,再将各组连接起来,便得到一个有序序列。
最低位优先法,简称 LSD 法:先从 k d-1 开始排序,再对 k d-2 进行排序,依次重复,直到对 k 0 排序后便得到一个有序序列。
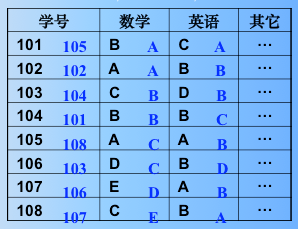
例:学生记录含三个关键字:系别、班号和班内的序列号, 其中以系别为最主位关键字。
LSD的排序过程如下:
对 Ki (0≤i≤d -2)进行排序时,只能用稳定的排序方法。用 LSD 法进行的排序,在一定的条件下(即对 Ki 的不同值Ki+1 均取相同值),可通过若干次“分配”和“收集”来实现。
例:先将学生记录按英语等级由高到低分成 A、B、C、D、E 五个组:
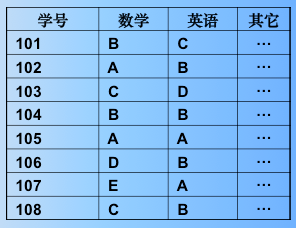
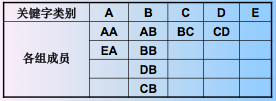
然后按从左向右,从上向下的顺序将它们收集起来得到关键字序列:AA,EA,AB,BB,DB,CB,BC,CD
再按数学成绩由高到低分成 A、B、C、D、E 五个组:
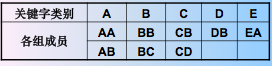
按从上向下,从左向右的顺序将其收集起来得到关键字序列:AA,AB,BB,BC,CB,CD,DB,EA
可以看出,这个关键字序列已经是有序的了, 对每个关键字都是将整个序列按关键字分组,然后按顺序收集,显然LSD法,操作比较简单。
MSD 与 LSD 的不同特点
MSD:必须将序列逐层分割成若干子序列,然后对各子序列分别排序。
LSD:不必分成子序列,对每个关键字都是整个序列参加排序;通过若干次分配与收集实现排序。
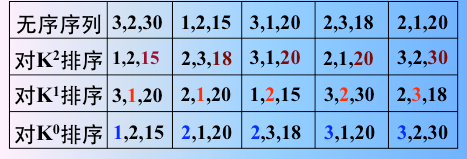
例:对于关键字序列 (101, 203, 567, 231, 478, 352)进行基数排序
可以将每个关键字 K 看成由三个单关键字组成,即 K= k1k2k3, 每个关键字的取值范围为 0≤ki≤9,所以每个关键字可取值的数目为 10。通常将关键字取值的数目称为基数,用 r 表示,在本例中 r =10。对于关键字序列(AB, BD, ED)可以将每个关键字看成是由二个单字母关键字组成的复合关键字,并且每个关键字的取值范围为 “A~Z”,所以关键字的基数 r = 26。
基数排序可用多关键字的LSD方法排序,即对待排序的记录序列按复合关键字从低位到高位的顺序交替地进行“分组”、“收集”,最终得到有序的记录序列。在此我们将一次“分组”、“收集”称为一趟。
对于由 d 位关键字组成的复合关键字,需要经过d 趟的“分配”与“收集”。 因此,若 d 值较大,基数排序的时间效率就会随之降低。
链式的基数排序算法
在计算机上实现基数排序时,为减少所需辅助存储空间,应采用链表作存储结构,即链式基数排序,具体作法为:
1、以静态链表存储待排记录,并令表头指针指向第一个记录;
2、“分配” 时,按当前“关键字位”所取值,将记录分配到不同的 “链队列” 中,每个队列中记录的 “关键字位” 相同;
3、“收集”时,按当前关键字位取值从小到大将各队列首尾相链成一个链表;
4、对每个关键字位均重复 2 和 3 两步。
例:链式基数排序,下面以静态链表存储待排记录,并令表头指针指向第一个记录。

“分配” 时,按当前“关键字位”所取值,将记录分配到不同的“链队列”中,每个队列中记录的 “关键字位” 相同。 因为是 LSD,故从地位开始 ,也就是kd-1位开始,进行一趟分配:

然后xx9,xx3,xx0
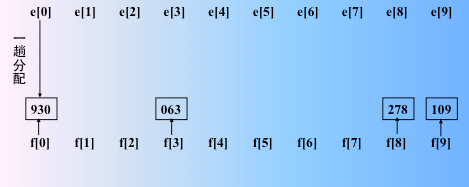
又遇到了 xx9,那么按照链式队列的存储方式,先进先出的入队(类似一个桶,数据从上面进入,从下面露出)
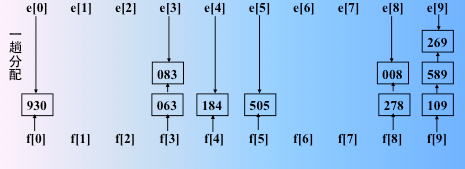
第一趟收集:按当前关键字位取值从小到大将各队列首尾相链成一个链表;(从队列的下面出去,先进先出)

进行第二趟分配,kd-2位

进行第二题收集

进行第三趟分配,也就是 kd-3位。本例子是 k1位关键字
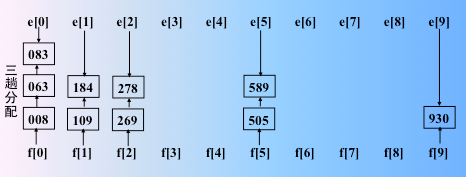
进行第三趟收集

序列按照多关键字从小到大的排序有序了
具体实现代码如下:
1 //链式队列的节点结构,模拟桶 2 struct Node 3 { 4 int data;//数据域 5 Node *next;//指针域 6 }; 7 8 //定义程序所需的特殊队列 9 class Queue 10 { 11 private: 12 Node *front;//链式对列的头指针 13 Node *rear;//链队的尾指针 14 15 public: 16 //构造函数,初始化队列(带头结点的链式队列) 17 Queue() 18 { 19 //开始先构造一个空结点,没有数据元素存储 20 Node *p = new Node; 21 p->data = NULL; 22 p->next = NULL; 23 //开始是空链队,首尾指针分别去指向队头结点 24 front = p; 25 rear = p; 26 } 27 //析构函数,销毁链队的结点占据的内存 28 ~Queue() 29 { 30 //标记指针 31 Node *p = front; 32 //辅助的标记指针,作用是删除结点 33 Node *q; 34 //循环遍历整个队列,直到标记指针 p 为 null 35 while (p != NULL) 36 { 37 //比较常见的删除结点内存的写法 38 q = p; 39 //指向队列的下一个结点 40 p = p->next; 41 //销毁之 42 delete q; 43 } 44 } 45 //入队方法,从尾进入,节点不存在,需要自行创建结点的方法 46 void push(int e) 47 { 48 Node *p = new Node; 49 p->data = e; 50 //本结点作为了队列的尾结点 51 p->next = NULL; 52 //然后连接结点到队尾 53 rear->next = p; 54 //最后尾指针指向新的末位结点 55 rear = p; 56 } 57 //入队方法,尾进入,节点原来就存在的方法,不需要再新建结点和存储结点的内容 58 void push(Node *p) 59 { 60 //设置此结点为尾结点 61 p->next = NULL; 62 //链接结点 63 rear->next = p; 64 //尾指针指向新的尾结点 65 rear = p; 66 } 67 //求数据元素的最大位数的方法,也就是求出需要分配和收集的次数 68 int lengthData() 69 { 70 int length = 0;//保存数据元素的 最大位数 71 int n = 0; //单个数据元素具有的位数 72 int d; //用来存储待比较的数据元素 73 //指示指针 74 Node *p = front->next; 75 //遍历 76 while (p != NULL) 77 { 78 //取出结点的数据,也就是代比较的数据元素 79 d = p->data; 80 //如果 d 为正数,很重要的一个技巧,必须是 d 大于 0 的判断 81 while (d > 0) 82 { 83 //数据位数分离算法 84 d /= 10; 85 //单个数据元素的位数存储在此 86 n++; 87 } 88 //沿着链队后移一个元素 89 p = p->next; 90 //找出数据元素的最大位数 91 if (length < n) 92 { 93 length = n; 94 } 95 //重新循环往复,n 设置为0 96 n = 0; 97 } 98 //返回最终位数 99 return length; 100 } 101 //判断队列是否为空 102 bool empty() 103 { 104 //队头指针和队尾指针重合,说明空 105 if (front == rear) 106 { 107 return true; 108 } 109 //否则为不空 110 return false; 111 } 112 //清除队列中的元素 113 void clear() 114 { 115 //直接把头结点之后的链接断开 116 front->next = NULL; 117 //设置尾指针指向头结点即可,回到了构造函数初始化的情景 118 rear = front; 119 } 120 //输出队列中的元素,传入引用参数比较好 121 void print(Queue &que) 122 { 123 //第一个结点是头结点,next 才是第一个存储元素的结点 124 Node *p = que.front->next; 125 //直到尾结点为止 126 while (p != NULL) 127 { 128 cout << p->data << " "; 129 //遍历所有结点 130 p = p->next; 131 } 132 } 133 //基数排序过程 134 void RadixSort(Queue& que) 135 { 136 //声明一个指针数组,该指针数组中存放十个指针,这十个指针需要分别指向十个队列,这是模拟10个桶,因为是0-9的数字,取值范围为10 137 Queue *arr[10]; 138 //初始化这十个队列 139 for (int i = 0; i < 10; i++) 140 { 141 //初始化建立头结点 142 arr[i] = new Queue; 143 } 144 //取得待排序数据元素中的最大位数 145 int maxLen = que.lengthData(); 146 //因为是 LSD 方式,从后到前,开始比较关键字,然后分配再收集,故开始设置数据分离算法中的除数为 1 147 int d = 1; 148 //将初始队列中的元素分配到十个队列中,maxlen 代表了需要分配和收集的次数 149 for(int i = 0; i < maxLen; i++) 150 { 151 Node *p = que.front->next; 152 //辅助指针 q 153 Node *q; 154 //余数为k,则存储在arr[k]指向的链式队列(桶)中 155 int k; 156 //遍历原始序列 157 while (p != NULL) 158 { 159 //重要的技巧,数据分离算法过程,最后勿忘模10,取余数,分离出需要的关键字位 160 k = (p->data / d) % 10; 161 q = p->next; 162 //把本结点 p 加入对应的队列中 163 arr[k]->push(p); 164 //指针后移,指向下一个结点 165 p = q; 166 } 167 //清空原始队列 168 que.clear(); 169 //分配完毕,马上将十个队列中的数据收集到原始队列中 170 for (int i = 0; i < 10; i++) 171 { 172 if (!arr[i]->empty()) 173 { 174 //从首节点开始遍历,不是头结点开始 175 Node *p = arr[i]->front->next; 176 //辅助指针 q 177 Node *q; 178 while (p != NULL) 179 { 180 q = p->next; 181 //收集到原始队列中,这就是为什么每次分配完毕,需要清除原始队列 182 que.push(p); 183 p = q; 184 } 185 } 186 } 187 //一趟的分配收集完毕,最后要清空十个队列 188 for (int i = 0; i < 10; i++) 189 { 190 arr[i]->clear(); 191 } 192 //进行下一趟的分配和收集 193 d *= 10; 194 } 195 //输出队列中排好序的元素 196 print(que); 197 } 198 }; 199 200 int main(void) 201 { 202 Queue oldque; 203 int i; 204 205 cout << "输入 int 类型的待排序的整数序列:输入 ctrl+z 结束输入,再回车即可" << endl; 206 //顺序输入元素 207 while (cin >> i) 208 { 209 oldque.push(i); 210 } 211 //基数排序 212 oldque.RadixSort(oldque); 213 214 return 0; 215 }
输入 int 类型的待排序的整数序列:输入 ctrl+z 结束输入,再回车即可
505 800 109 930 630 662 663 269 278 287 299 200 830 184 187 528 112 125 589
109 112 125 184 187 200 269 278 287 299 505 528 589 630 662 663 800 830 930
Program ended with exit code: 0
链式基数排序的时间复杂度和空间复杂度分析
假设:n —— 记录数 , d —— 关键字数, rd —— 关键字取值范围(如十进制为10)
分配(每趟):T(n)=O(n) ,每次分配,分配的都是所有的关键字,故是 n
收集(每趟):T(n)=O(rd) ,收集的是桶里的数据,也就是关键字的取值范围大小rd,是桶的数目
总的时间复杂度:因为一次完整的排序是分配+收集,也就是 n+rd ,而一共需要的排序趟数,恰恰就是关键字的数目 d,故T(n)=O(d(n+rd))
空间复杂度:S(n)=2rd 个队列指针 + n 个指针域空间,因为一个桶本质是一个链式队列,一共 rd 个桶,每个队列有队头和队尾两个指针,就是2rd 个队列指针。又原来的代拍序列是一个单链表,那么自然需要 n 个next指针控件。
排序小结
一、时间性能
平均情况下,记住一个口诀:快些以 n log2 n 的速度归队
快=快速排序,些=希尔排序,归=归并排序,队=堆排序
这四种排序算法,时间都是 n log2 n 的,除了这四个之外,其他的排序算法平均时间都为 n^2
记住一个特殊的排序算法:基数排序的时间复杂度
d(n+rd),其中 d 是分配和收集的趟数,n 是原始序列的数目(分配次数),rd 是桶的个数,也就是关键字最大位数(收集次数)
最坏的情况下,这四个中,快速排序为 n^2,其余的和平均时间相同,还是 n log2 n
二、空间复杂度
快速排序是 log2 n
归并排序是 n
基数排序是 2rd
其余的都是1
又有口诀:直接插的好,为 n,起泡起的好为 n
三、稳定性
心情不稳定,快些选一堆好友来陪我
快=快速排序
些=希尔排序
选=简单选择排序
堆=堆排序
其余的排序算法都稳定
四、一趟排序,保证一个元素为最终位置的有两类排序算法:交换类(冒泡和快速)排序和选择类排序(简单和堆)
五、元素比较次数和原始序列无关的算法:简单选择排序,折半插入排序
六、排序趟数和原序列有关的算法:交换类,其余类无关
七、借助于比较进行排序的算法,在最坏的时候,最好的时间复杂度为 n log2 n
八、堆排序和简单选择排序的时间复杂度和初始序列无关
注意,这些东西,不必要必须死记硬背,明白每个算法的类别和实现原理,在理解的基础上,记忆,在脑海里推导演示排序的过程,帮助记忆。
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!
