主要讨论的是C++早期编译器在处理对类相关成员在内存中的布局情况
1.加上封装后的布局成本
首先说明C++在增加封装特性后,简单的类类型并不比C/C++结构体类型带来的布局成本高。下面作简单说明:
class base { virtual ~base(); static int print(); static float m_f; int m_i; };
静态成员和非内联函数(c++ 内联函数不能成为虚函数)均不属于对象,如果不存在虚函数则只有普通成员变量属于对象,故而普通类类型和C结构体类型无异。
考虑到继承和多态的情况下,早期的编译器对类的对象模型衍生出几种不同的布局形式,用以支持”虚”的特性。
关于虚函数和虚继承后续说明。
先说明下早期的几种对象模型:
(1)简单对象模型
类只存储指针,指向所有类成员实体。

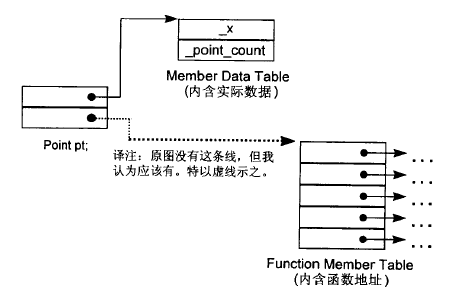
(2)表格驱动的对象模型
类只存储两个表的指针,而两个表实际存储的也是一堆指针。
成员表中的各个指针指向各个成员变量实体的地址。
函数表中的各个指针则指向各个成员函数实体的首地址。
(3) C++对象模型
简单对象模型已被丢弃,而现在的C++对象模型在出现虚函数或者虚继承的情况下,对象模型和表格驱动的对象模型有几分相似。
首先是虚函数表,其次是虚基类表。下面是包含虚函数表的情况。
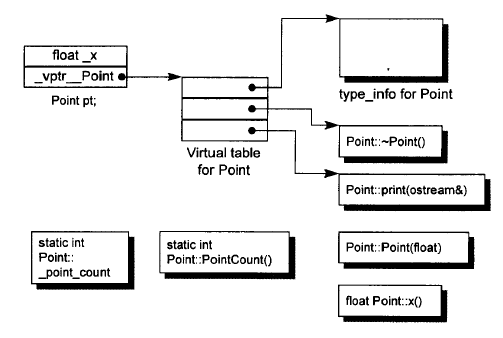
此种模型在存在虚表时相对于普通类,多存储了一个指针数据vptr,而在运行时增加了一种动态绑定机制需要根据偏移寻址函数实体,
这是间接性寻址之一,再加上虚继承时针对虚基类的多层间接寻址,此差异才是C++和C在内存布局和运行效率上差异的主要原因。
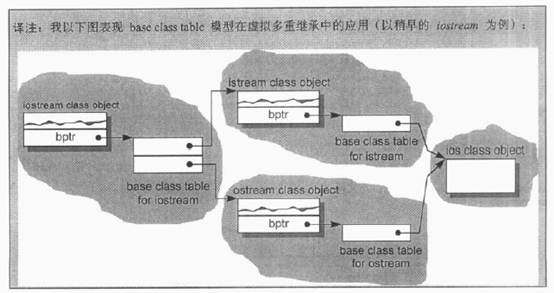
针对不同的编译器,对”虚”机制的有不同的处理方式,以上只是以C++发展过程中主流编译器的内存模型作说明。
另外,关于虚表中存储type_info指针的位置,即使现在的主流编译器实现也不同。
VC放在虚表首地址前的位置,而在老编译器CFront中可以看出放在虚表首地址,不必纠结。
以下就书中所讲的一段形式代码作解析:


- foobar如果是作为X的友元函数,则通过X对象调用foobar的时候等同于foobar(X x),则编译时调用者X会作为首参传递到foobar的形参中。类似对象调用其成员函数的this传递形式。
- 至于其foobar的返回值X类型。此例之一可能是为了说明一种优化手段(现行编译器如g++):即局部对象作为返回值时在函数执行结束不析构掉原局部对象,再重新构造一个临时对象作为返回值对象,而是直接返回已有的临时对象,从而减少一次对象构造开销。
- 引用型参数同样可以避免可能存在的一次无意义的构造(返回值对象)。
- 但作为引用型实参,是必须在定义的时候就初始化的,即其引用的对象实体其实是已经被构造出来了,意味着foobar内部的_result的再次调用构造会造成先前实体对象的重新初始化。
- px的构造说明了类的构造函数分为两步,第一步即内存分配,第二步成员初始化。这也是一个考虑到饿汉模式,减少非空判断,减少上锁次数和临界区大小且保证线程安全同时保证性能的完美的单例模式不好实现的原因之一。这里构造的两步就可能影响到线程安全。
- 后面两种调用X的foo,_result因为是对象而非指针函数的动态绑定,所以在使用时不表现多态性,直接调用基类的foo,而px如果是作为基类指针但实际上指向一个子类对象,而foo又在子类中重写形成和父类X的foo形成有效覆盖,则此种调用形式将形成多态调用,px虽然是基类指针,实际却调用的是覆盖版本即子类的foo。
- 多态情况下虚函数实体的调用通过虚表指针。通过虚表指针偏移,先调用覆盖版本的foo后调用了覆盖版本的析构。
- 这里说覆盖版本的析构不太准确,但C++的机制是,一旦基类是虚析构,则可以通过delete基类指针来析构子类对象,而子对象的析构又会在子类析构完后自动调用其基类的析构从而完成整个子对象的析构,具体实现待研究。
- 关于构造和析构的顺序,构造时先构造基类,再构造子类,而在析构时则是先析构子类中的非基类部分,再析构基类。
以上为个人关于这段形式代码的分析。
2.关键词差异
主要做两个说明:
(1)一个是为了C++编译器或者解析器对函数调用和函数声明的额外处理
int (*pf)(124);
int (*pq)();
书中所说,第一个位函数调用(带返回值类型,具体原因不懂),第二个为函数声明。
但是以现在C++语法来看,首先函数声明是不能带实参的,函数调用是不能带类型的。
#include <iostream> using namespace std; int (*ff)(int, int);//函数指针类型声明 typedef int (*pff)(int, int); int mymax(int a,int b) { return a > b ? a : b; } int main() { int ret = -1; pff pf1 = &mymax;//等价pff pf1 = mymax;编译器允许使用函数名称作为函数首地址。 pff* ppf1 = &pf1; ret = pf1(123,456); ret = (*ppf1)(123,456); return 0; }
(2)第二个说明下结构体
首先,C++中为什么要有结构体类型?事实上,如果不用考虑C++对C的兼容,使用结构体的地方基本可以用类替换。
下面说明下结构体和类的差异:本质上来讲,struct拥有class的区别仅仅在于默认的访控属性。
首选是成员的访控属性,struct默认公有,class默认私有。
其次是继承时的子类对象对基类成员的访控属性,如果没有显式指定继承方式,则由子类是结构体还是类决定。如下:
struct A:B{}; 不管B是class还是struct都是 公有继承,
class A:B{}; 不管B是class还是struct都是 私有继承。
除非显式指定struct A:private B; 或者class A:public B; 即:默认的继承属性看子类/结构体的默认访控属性。
这也是一般类继承的时候class A: public class B;要指定public继承方式,因为默认是private的。
如果以默认方式继承则在该类外部就无法访问基类的所有成员,因为基类成员被私有继承后在子类中将全部被私有化。
这一点可以参考 C++中结构体与类的区别(struct与class的区别)
以上来看,类和结构体确实是没有多大差异,通常来讲,如果仅仅是作为一种数据结构,使用结构体,注重对象功能则使用类。
但如果定义了一个strcut却用class声明,vc编译器不报错,但会给警告,反之也一样。
通常容易忽略的是,C++中结构体同样支持继承,多态,虚析构。
struct A
{
int m_a;
A(int a):m_a(a){}
virtual void ptf()
{
cout <<"A::ptf" << endl;
}
virtual ~A()
{
cout <<"~A" << endl;
}
};
struct B :A
{
B(int b):A(b),m_b(b+1){}
virtual void ptf()
{ cout <<"B::ptf" << endl; }
virtual ~B()
{ cout <<"~B" << endl; } int m_b; }; int main (void) { B* pb = new B(10); cout << pb->m_a << pb->m_b << endl; pb->ptf(); delete pb; A* pa = new B(10); delete pa;; getchar(); return 0; }
输出:
1011 B::ptf ~B ~A ~B ~A
书中接下来讲的差异是从内存布局上来讲的。
但个人不是很理解,因为就现在的编译器来讲,成员变量在内存中总是按照声明顺序来排列的,和访控属性并无关系。目前主流编译器也是把基类成员放在前面,派生类的非基类成员放在后面,并不会改变基类本身的内存布局。
揣摩作者的表述,猜想可能是当初的C++对结构体成员不区分访控属性,而恰好当时的编译器在处理类的成员变量时会考虑类成员变量的访控属性,将相同访控属性的按声明顺序放在一起。不再作深究。
比较明确的一点就是:不同的编译器确实对于基类在子类的中位置以及虚表指针和type_info信息存放位置有不同的处理方式,了解目前主流编译器的内存布局就行了。
结论:struct作为一个数据集合体使用,即纯C结构体的用法。class来体现C++面向对象特性。将结构体作为一种纯数据封装体组合到类中。
在面向对象设计原则上,不管是类继承结构体还是结构体继承类,均按照优先使用组合而非继承的原则。
但并非一定要用组合,也是要看使用场景的。组合通常是黑箱复用,继承通常是白箱复用,has A和 Is A还是有区别的。尤其是在钻石继承中(暂不考虑虚继承),可能最终子类实体四不像,耦合度更高,还更加重复。
附带说下对齐和补齐:
结构体或者类的成员变量内存布局是按照声明顺序在内存中顺序存储的,考虑到CPU存取指令和内存数据存取效率问题,有对其和补齐。
实际上为了实现高效存取,损失了内存使用率,即在按照声明顺序存数据时,按照指定的对齐方式来对齐,并对不够的部分进行补齐。
例如
struct st{
int a;
char b;
float c;
char d;
};
实际上如果是4字节对齐,则sizeof(struct st) = 16,而如果不考虑对齐和补齐,10个字节就够了。
C/C++均要求内存的对齐和补齐,lds指定align或默认对齐方式。
3.对象差异
可以先看下虚表及其指针的内存布局,虚基类中的虚表指针属于代码段,对应的虚函数表大小也是在编译期就决定了。虚表,虚表指针的内存布局
子类继承基类后,子类除了包含基类对象的虚函数表外还存在自己的虚函数表,如果多态实现的有效覆盖,则实际上子类中的覆盖版本虚函数函数地址覆盖保存到基类子对象的虚表中,子类独有的虚函数则保存在自己的虚函数表中。
(1)c++程序设计模型
- 程序模型--面向过程
基本C面向过程编程。
- 接口模型--面向抽象/接口,具体对象行为的抽象表示,OO
抽象即隐而未明的一组公有(私有或者保护,外部将无法访问,接口也就无实际使用意义)接口,依赖具体实现,体现:继承和多态
- 对象模型--面向对象
以对象为基本单位,体现:继承和封装,OB,ADT
形成多态的条件:多态性除了需要在子类和基类间形成有效的虚函数覆盖外,还必须通过指针或引用去访问虚函数。
对象一旦定义则其类型决定了对象大小是固定的,而指针和引用指向的对象实体(派生类对象)可能并非指针或者引用本身(基类对象)的类型,正是这种伸缩性才是形成多态的必要条件。
形成有效覆盖的前提条件:
a.只有类的非静态成员函数才能被声明为虚函数,全局函数和类的静态成员函数都不能是虚函数。
b.有在基类中被声明为虚函数的成员函数才能在子类中覆盖。
c.虚函数在子类中的覆盖版本必须和该函数基类版本拥有完全相同的签名,即函数名,形参表,常属性严格一致。
d.如果基类中虚函数的返回类型为基本类型或类类型的对象,那么子类的覆盖版本必须返回相同的类型。
基于覆盖,顺便提下如何区分重载、覆盖和隐藏
重载必须在同一个作用域中
覆盖必须是同型的虚函数
如果不是重载也不是覆盖,而且函数名还是一样,那就一定是隐藏
就书中讲到的两个sizeof作下记录:
基本string类型包含一个指针和一个记录指针数据实体的长度,大小8字节
引用,本质上也是指针,但是又和指针不同。指针和引用的区别:
a.指针可以不初始化,其目标可以在初始化后随意变更。但是引用必须初始化,而且一旦初始化就无法变更其目标
b.可以定义空指针,即什么也不指向的指针,但是不能定义空引用,引用必须有所指引,否则引用将失去意义
c.可以定义指向指针的指针,但是没法定义一个引用引用的引用。C++2011中类似"int&&"的类型是合法的,但是他表示右值引用,而非二级引用。
d.可以定义一个引用指针的引用,但是无法定义一个指向引用的指针。
e.可以定义存放指针的数组,但无法定义存放引用的数组.可以定义引用数组的引用
另外,引用的sizeof由引用的对象决定,指针的sizeof固定大小一般为4。
(2)指针的类型
指针本质上是没有类型的,之所以我们定义指针的时候加上类型,是要确认指针指向的那块数据的类型。
就像是函数要定义返回值类型一样,只是告诉我们需要用什么类型来接收函数执行结果
(3)多态可能造成的对象切割
C++加上继承之后,基类指针指向子类对象时如果不考虑多态,则使用基类指针操作子类对象,会发生切割,只会被当做一个独立的基类对象,只允许访问其中的基类成员部分。
如果考虑到多态,由于不同编译器对虚表指针布局不同切割可能导致对象不完整,从而引发未知错误。
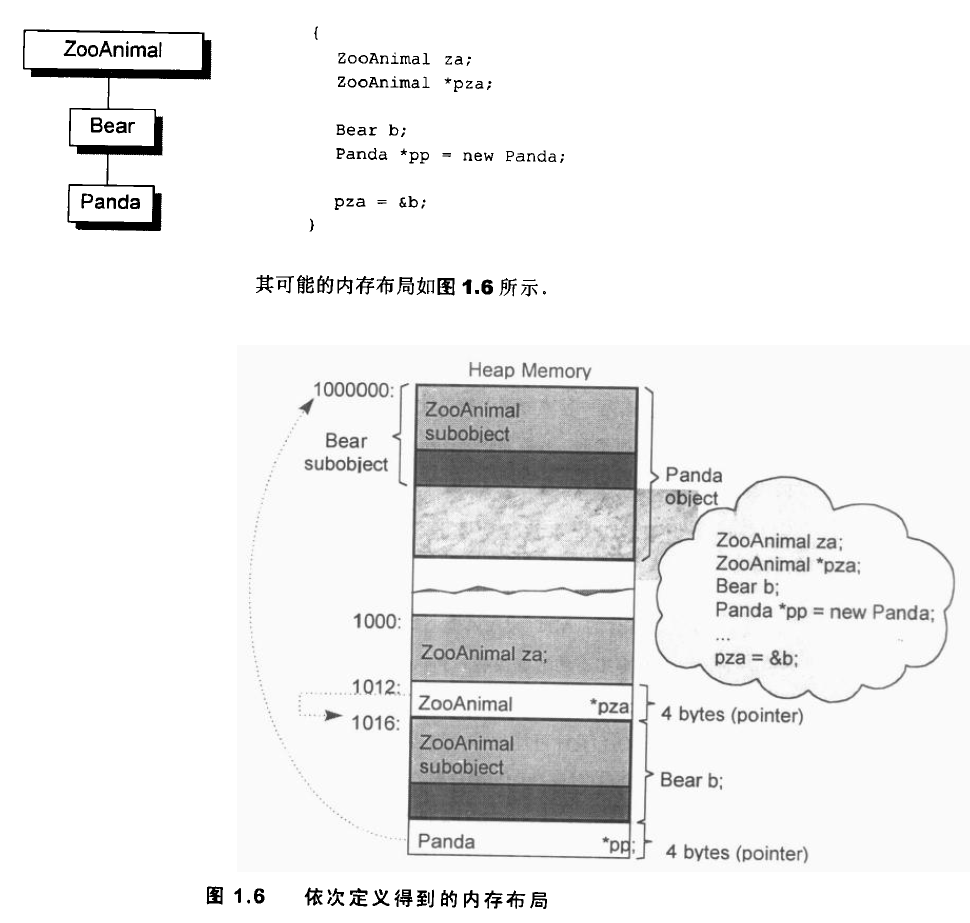
借助书中的图,简单看下对象的存储。
先说明:
a.内存堆栈划分:堆低地址到高地址使用,栈由高地址向低地址使用(但不代表定义一个in a[4]后&a[0] > &a[3]),高地址为栈底,低地址为栈顶,程序运行由sp栈指针偏移访问。
b.关于压栈顺序,不同的编译器局部变量和函数实参的压栈顺序存在差异(MSVC函数 是从右向左,mingw从左向右,局部变量MSVC好像是按定义顺序。。局部变量入栈顺序与输出关系)
再来说说上图:
局部变量,包括指针都是存在栈中的,只有new,malloc/calloc/realloc出来对象的放在堆中。
按图中,上半部为堆,下半部为栈。堆中只有Panda对象。按照图中的排列,该编译器局部变量的压栈顺序应该是先定义的后压栈。za最后定义,却在栈顶可以看出,至于其他变量不再赘述。
以上即个人对书中第一章关于C++对象的一个基本认识 附带加上了部分C++个人储备。如有错误,请指出,共同学习。