在上一篇文章中介绍了并行计算的基础概念,也顺便介绍了OpenMP。
OpenMp提供了对于并行描述的高层抽象,降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMp中,OpenMp库从程序员手中接管了部分这两方面的工作。但是,作为高层抽象,OpenMp并不适合需要复杂的线程间同步和互斥的场合。OpenMp的另一个缺点是不能在非共享内存系统(如计算机集群)上使用,一般在这样的系统上,MPI使用较多。
在Visual Studio中使用OpenMP其实很简单,只要将 Project 的Properties中C/C++里Language的OpenMP Support开启(参数为 /openmp),就可以让VC++在编译时就可以支持OpenMP 的语法了。而在编写使用OpenMP 的程序时,添加#include <omp.h>即可。下面是一个实例:


#include <stdio.h> #include <omp.h> #include <windows.h> #define MAX_VALUE 10000000 double _test(int value) { int index = 0; double result = 0.0; for(index = value + 1; index < MAX_VALUE; index +=2 ) result += 1.0 / index; return result; } void OpenMPTest() { int index= 0; int time1 = 0; int time2 = 0; double value1 = 0.0, value2 = 0.0; double result[2]; time1 = GetTickCount(); for(index = 1; index < MAX_VALUE; index ++) value1 += 1.0 / index; time1 = GetTickCount() - time1; memset(result , 0, sizeof(double) * 2); time2 = GetTickCount(); #pragma omp parallel for for(index = 0; index < 2; index++) result[index] = _test(index); value2 = result[0] + result[1]; time2 = GetTickCount() - time2; printf("time1 = %d,time2 = %d ",time1,time2); return; } int main() { OpenMPTest(); system("pause"); return 0; }
在这里例子中用到了一个关键的语句:
#pragma omp parallel for
这个句子代表了C++中使用OpenMP的基本语法规则:#pragma omp 指令 [子句[子句]…]
1. OpenMP指令与库函数
OpenMP包括以下指令:
- parallel:用在一个代码段之前,表示这段代码将被多个线程并行执行
- for:用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性
- parallel for:parallel 和 for语句的结合,也是用在一个for循环之前,表示for循环的代码将被多个线程并行执行
- sections:用在可能会被并行执行的代码段之前
- parallel sections:parallel和sections两个语句的结合
- critical:用在一段代码临界区之前
- single:用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行
- barrier:用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执行
- atomic:用于指定一块内存区域被制动更新
- master:用于指定一段代码块由主线程执行
- ordered:用于指定并行区域的循环按顺序执行
- threadprivate:用于指定一个变量是线程私有的
OpenMP除上述指令外,还有一些库函数,下面列出几个常用的库函数:
- omp_get_num_procs:返回运行本线程的多处理机的处理器个数
- omp_get_num_threads:返回当前并行区域中的活动线程个数
- omp_get_thread_num:返回线程号
- omp_set_num_threads:设置并行执行代码时的线程个数
- omp_init_lock:初始化一个简单锁
- omp_set_lock:上锁操作
- omp_unset_lock:解锁操作,要和omp_set_lock函数配对使用
- omp_destroy_lock:omp_init_lock函数的配对操作函数,关闭一个锁
OpenMP还包括以下子句:
- private:指定每个线程都有它自己的变量私有副本
- firstprivate:指定每个线程都有它自己的变量私有副本,并且变量要被继承主线程中的初值
- lastprivate:主要是用来指定将线程中的私有变量的值在并行处理结束后复制回主线程中的对应变量
- reduce:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的运算
- nowait:忽略指定中暗含的等待
- num_threads:指定线程的个数
- schedule:指定如何调度for循环迭代
- shared:指定一个或多个变量为多个线程间的共享变量
- ordered:用来指定for循环的执行要按顺序执行
- copyprivate:用于single指令中的指定变量为多个线程的共享变量
- copyin:用来指定一个threadprivate的变量的值要用主线程的值进行初始化。
- default:用来指定并行处理区域内的变量的使用方式,缺省是shared
2. parallel指令用法
parallel 是用来构造一个并行块的,也可以使用其他指令如for、sections等和它配合使用。其用法如下:
#pragma omp parallel [for | sections] [子句[子句]…] { // 需要并行执行的代码 }
例如,可以写一个简单的并行输出提示信息的代码:
#pragma omp parallel num_threads(8) { printf(“Hello, World!, ThreadId=%d ”, omp_get_thread_num() ); }
在本机测试将会得到如下结果:
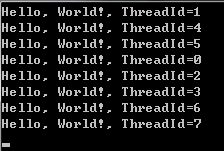
结果表明,printf函数被创建了8个线程来执行,并且每一个线程执行的先后次序并不确定。和传统的创建线程函数比起来,OpenMP相当于为一个线程入口函数重复调用创建线程函数来创建线程并等待线程执行完。如果在上面的代码中去掉num_threads(8)来指定线程数目,那么将根据实际CPU核心数目来创建线程数。
3. for指令用法
for指令则是用来将一个for循环分配到多个线程中执行。for指令一般可以和parallel指令合起来形成parallel for指令使用,也可以单独用在parallel语句的并行块中。其语法如下:
#pragma omp [parallel] for [子句] for循环语句
例如有这样一个例子:
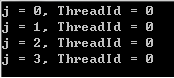
#pragma omp parallel for for ( int j = 0; j < 4; j++ ) { printf("j = %d, ThreadId = %d ", j, omp_get_thread_num()); }
可以得到如下结果:

从结果可以看出,for循环的语句被分配到不同的线程中分开执行了。需要注意的是,如果不添加parallel关键字,那么四次循环将会在同一个线程里执行,结果将会是下面这样的:
4. sections和section的用法
section语句是用在sections语句里用来将sections语句里的代码划分成几个不同的段,每段都并行执行。用法如下:
#pragma omp [parallel] sections [子句] { #pragma omp section { // 代码块 } }
例如有这样一个例子:
#pragma omp parallel sections { #pragma omp section printf("section 1 ThreadId = %d ", omp_get_thread_num()); #pragma omp section printf("section 2 ThreadId = %d ", omp_get_thread_num()); #pragma omp section printf("section 3 ThreadId = %d ", omp_get_thread_num()); #pragma omp section printf("section 4 ThreadId = %d ", omp_get_thread_num()); }
可以得到如下结果:

结果表明,每一个section内部的代码都是(分配到不同的线程中)并行执行的。使用section语句时,需要注意的是这种方式需要保证各个section里的代码执行时间相差不大,否则某个section执行时间比其他section长太多就达不到并行执行的效果了。
如果将上面的代码拆分成两个sections,即:
#pragma omp parallel sections { #pragma omp section printf("section 1 ThreadId = %d ", omp_get_thread_num()); #pragma omp section printf("section 2 ThreadId = %d ", omp_get_thread_num()); } #pragma omp parallel sections { #pragma omp section printf("section 3 ThreadId = %d ", omp_get_thread_num()); #pragma omp section printf("section 4 ThreadId = %d ", omp_get_thread_num()); }
产生的结果将会是这样的:
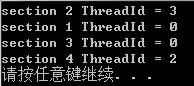
可以看出,两个sections之间是串行执行的,而section内部则是并行执行的。
小节:
用for语句来分摊任务是由系统自动进行的,只要每次循环间没有时间上的差距,那么分摊是很均匀的,使用section来划分线程是一种手工划分线程的方式,最终并行性的好坏依赖于程序员。
本篇文章中讲的几个OpenMP指令parallel, for, sections, section实际上都是用来如何创建线程的,这种创建线程的方式比起传统调用创建线程函数创建线程要更方便,并且更高效。