笔记中函数简介:
- map函数:遍历序列,对序列中每个元素进行操作,最终获取新的序列。
- reduce函数:对于序列内所有元素进行累计操作。
- filter函数:对于序列中的元素进行筛选,最终获取符合条件的序列。
Tips:这三条函数经常与lambda关键字搭配使用。
一、map()
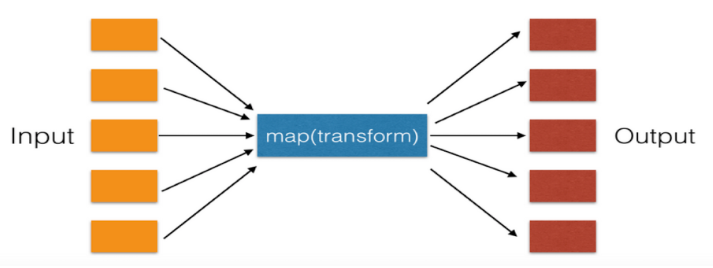
#map在这里我理解翻译为"比对"的意思
接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数f(x)=x^2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
>>> def f(x): ... return x * x ... >>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> list(r) [1, 4, 9, 16, 25, 36, 49, 64, 81]
#使用lambda关键字
list(map(lambda x:x*x , [1,2,3,4,5,6,7,8,9]))
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
>>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])) ['1', '2', '3', '4', '5', '6', '7', '8', '9']
练习:
利用map()函数,把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字。输入:['adam', 'LISA', 'barT'],输出:['Adam', 'Lisa', 'Bart']:
def kumata(name): return name[0].upper + name[1:].lower #或者 def kumata(name): return name.title() # 测试: L1 = ['adam', 'LISA', 'barT'] L2 = list(map(kumata, L1)) print(L2) #输出 ['Adam', 'Lisa', 'Bart']
二、reduce()
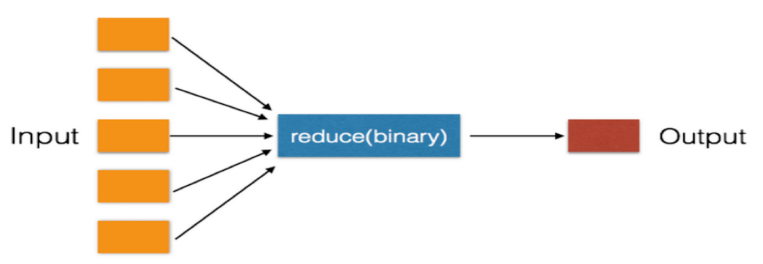
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce实现:
>>> from functools import reduce >>> def add(x, y): ... return x + y ... >>> reduce(add, [1, 3, 5, 7, 9]) 25 #使用lambda关键字 from functools import reduce reduce(lambda x,y:x+y ,[1,3,5,7,9])
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
>>> from functools import reduce >>> def fn(x, y): ... return x * 10 + y ... >>> reduce(fn, [1, 3, 5, 7, 9]) 13579
练习:
Python提供的sum()函数可以接受一个list并求和,请编写一个prod()函数,可以接受一个list并利用reduce()求[3,5,7,9]的积:
from functools import reduce >>> reduce(kuma,[3,5,7,9]) 945
三、filter()
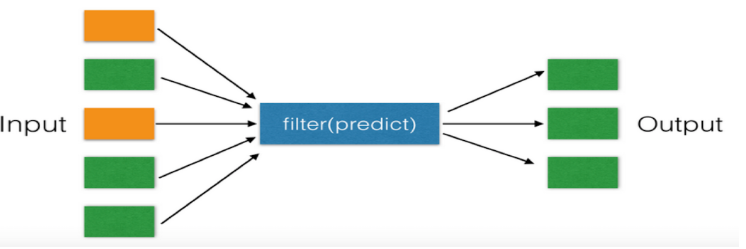
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n): return n % 2 == 1 list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])) [1, 5, 9, 15] #使用lambda关键字 list(filter(lambda n:n%2 == 1 , [1,2,4,5,6,9,10,15]))
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s): return s and s.strip() list(filter(not_empty, ['A', '', 'B', None, 'C', ' '])) ['A', 'B', 'C'] #使用lambda关键字 list(filter(lambda s:s and s.strip(),['A', '', 'B', None, 'C', ' '])) ['A', 'B', 'C'] #注意:这里没有直接用 lambda s:s.strip() 是因为None是没有strip和len方法的,如果直接这样用会报错 #加上and之后,就会先判断s的存在,如果s是None那就不用往下执行了,直接返回None
可见用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。