线程与进程的区别
进程:正在运行的程序,是资源单位,不同进程间资源是隔离的,创建开销大(创建子进程会拷贝父进程的状态,当做自己的初始状态,之后的修改与父进程无关。)需要使用ipc机制,进行进程间的交互。
线程:如果把进程比作车间,那么线程就是车间的流水线,每个车间至少要有一条流水线(一个进程至少一个线程),线程是cpu的调度单位,创建开销小。同一进程里的线程是共享的,能进行相互通信,但是会产生抢占问题,数据不安全,所以使用锁或者队列保证共享数据的安全性。
多线程:(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
多线程的用途
1. 多线程共享一个进程的地址空间
2. 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3、若多个线程都是cpu密集型的(程序中计算多),那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而加快程序的执行速度。
4、在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(不适用于cpython解释器)
创建线程的两种方式
#第一种 def work(): print('run thead') if __name__ == '__main__': t = Thread(target=work) t.start() t.join() print('主') #打开线程的第二种方式 class MyThead(Thread): def __init__(self,name): super().__init__() self.name = name def run(self): print('run thead') if __name__ == '__main__': t = MyThead('wate') t.start() t.join() print('主')
线程与进程开销的比较
#我们创建个线程和进程来根据结果判断执行效率 from threading import Thread from multiprocessing import Process def work(): print('run thead') if __name__ == '__main__': t = Thread(target=work) t.start() #先打印线程的结果 print('主') if __name__ == '__main__': t = Process(target=work) t.start() #先打印主进程的结果 print('主') //run thead //主 //主 //run thead #由于进程开销大,所以,我们看到的结果是先执行了主进程,然后执行了子进程的代码
线程间的资源共享示例
from threading import Thread n = 100 def work(): global n n = 0 if __name__ == '__main__': t = Thread(target=work) t.start() print(n) //0 #线程共享主进程的资源,子线程修改后,会影响主进程的值 from multiprocessing import Process n = 100 def work(): global n n = 0 if __name__ == '__main__': p = Process(target=work)#进程间的资源是隔离的 p.start() print(n) //100 #进程间资源不共享n在子进程中修改,不会影响主进程中的值
多线程之间协作练习
用户输入内容,进行格式化,写入文件,我们使用3个线程并发实现操作
from threading import Thread msg_l = [] format_l=[] def talk():#用户输入内容 while True: msg = input('>>').strip() msg_l.append(msg) def format():#格式化 while True: if msg_l: data = msg_l.pop() format_l.append(data.upper()) def save():#写入 while True: if format_l: data = format_l.pop() with open('db.txt','a') as f: f.write('%s '%data) if __name__ == '__main__': t1 = Thread(target=talk) t2 = Thread(target=format) t3 = Thread(target=save) t1.start() t2.start() t3.start()
线程的其他方法
from threading import Thread,activeCount,enumerate,current_thread def work(): print('run thead%s'%current_thread().getName())#在函数中获得线程名 if __name__ == '__main__': t = Thread(target=work) t.start() print(activeCount())#存活的线程 print(enumerate())#当前活跃的线程对象 print(t.is_alive())#线程是否存活//true print(t.getName())#线程名字//Thread-1 t.join()#等线程执行完,执行主线程 print(t.is_alive())#//false print('主')
守护进程
#无论是进程还是线程都遵循,守护xxx会等待主xxx执行完成后,被销毁
#对主进程来说,运行完毕指的是主进程代码运行完毕
#对于主线程来说,运行完毕指的是主线程所在进程内所有非守护线程统统运行完毕,主线程才算运行完成
#1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束,
#2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
from threading import Thread import time def work(): time.sleep(1) print('aaa') def task(): time.sleep(2) print('bbbb') if __name__ == '__main__': t1 = Thread(target=work) t2 = Thread(target=task) t1.daemon =True t1.start() t2.start() print('主') //主 //aaa //bbbb #对于守护线程来说,主线程结束后,守护线程才会结束,而线程会在所有非守护线程执行结束后结束,所以1秒的守护线程会执行完毕。
#与守护进程不同 #守护进程会在主进程执行完成后便结束,不会等其他进程执行 from multiprocessing import Process import time def work(): time.sleep(1) print('aaa') def task(): time.sleep(2) print('bbbb') if __name__ == '__main__': t1 = Process(target=work) t2 = Process(target=task) t1.daemon =True t1.start() t2.start() print('主') //主 //bbbb #守护线程t1在打印主之后主进程结束时便结束了,即使t2还在运行
GIL锁
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
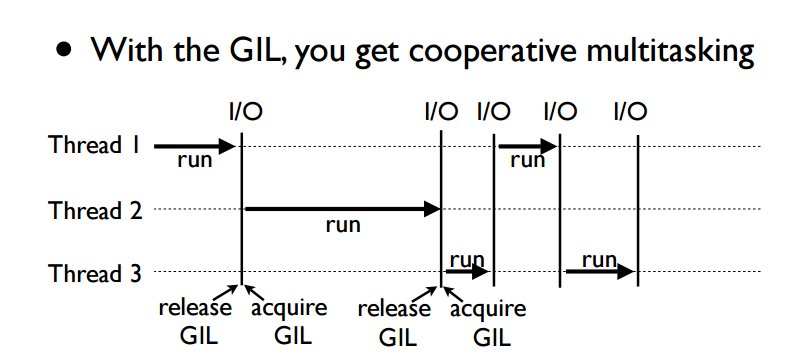
对于python的cpython解释器来说,进程中的线程的运行首先要抢到GIL锁,才能执行自己的任务,所以进程中的线程始终是一个线程在运行,在遇到io时,锁会释放,允许其他的线程抢锁,执行任务。
from threading import Thread import time n=100 def work():#第一个线程抢到gil锁运行代码 global n print('work is runing') temp = n time.sleep(0.1) #第一个线程遇到阻塞,释放gil锁,第二个线程获得gil锁,第二个线程遇到阻塞,第三个线程获得gil锁。。。每个线程在获得锁的时候,都保存了数据n=100,所以n最后是99 #gil锁无法保证python内部的数据安全,只能保证,解释器级别的数据安全 n = temp-1 if __name__ == '__main__': t1 = Thread(target=work) t2 = Thread(target=work) t3 = Thread(target=work) t1.start() t2.start() t3.start() t1.join() t2.join() t3.join() print(n)
#互斥锁 #gil锁无法保证python内数据的安全性,所以,我们手动给加锁 from threading import Thread,Lock import time n=100 def work():#第一个线程抢到gil锁运行代码 global n mutex.acquire()#加锁让线程串行执行 print('work is runing') temp = n time.sleep(0.1) n = temp-1 mutex.release() if __name__ == '__main__': mutex = Lock() t1 = Thread(target=work) t2 = Thread(target=work) t3 = Thread(target=work) t1.start() t2.start() t3.start() t1.join() t2.join() t3.join() print(n)
线程与进程的性能讨论
from threading import Thread from multiprocessing import Process import time #计算密集型 def work(): res = 0 for i in range(10000000): res+=i if __name__ == '__main__': p_l = [] start = time.time() for i in range(4): # p = Process(target=work)#2.9671072959899902 p = Thread(target=work)#4.874460935592651 p_l.append(p) p.start() for p in p_l: p.join() print(time.time()-start)
#多进程,可以利用多核优势 #缺点:开销大 # 多线程:优点,开销小 # 缺点,不能利用多核优势 from threading import Thread from multiprocessing import Process import time #IO密集型 def work(): time.sleep(2) if __name__ == '__main__': p_l = [] start = time.time() for i in range(4): p = Process(target=work)#2.330955743789673 # p = Thread(target=work)#2.002347230911255 p_l.append(p) p.start() for p in p_l: p.join() print(time.time()-start)
结论:io密集型使用线程,计算密集型使用进程。
死锁与递归锁
from threading import Thread,Lock,RLock import time mutexA = Lock() mutexB = Lock() class Mythread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print('%s 抢到A锁'%self.name) mutexB.acquire() print('%s 抢到B锁'%self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print('%s 抢到A锁' % self.name) time.sleep(1) mutexA.acquire() print('%s 抢到B锁' % self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(20): t = Mythread() t.start() #死锁,线程1拿到a锁等b锁,线程2拿到b锁等a锁,产生死锁
#递归锁:内部有个引用计数器,每锁一次计数器加一,release一次就减一,其他的线程抢锁,必须count变成0 from threading import Thread,Lock,RLock import time mutex = RLock() class Mythread(Thread): def run(self): self.f1() self.f2() def f1(self): mutex.acquire() print('%s 抢到A锁'%self.name) mutex.acquire() print('%s 抢到B锁'%self.name) mutex.release() mutex.release() def f2(self): mutex.acquire() print('%s 抢到A锁' % self.name) time.sleep(1) mutex.acquire() print('%s 抢到B锁' % self.name) mutex.release() mutex.release()
信号量
#信号量管理一个内置的计数器,每当调用acquire时内置计数器-1, #调用release时内置计数器+1 #计数器不能小于0,当计数器胃0时,acuqire将阻塞先蹭知道其他先蹭调用 #同时只有5个线程可以获得semaphore,即可以限制最大连接数为5 from threading import Thread,current_thread,Semaphore import time,random sm = Semaphore(5) def work(): sm.acquire() print('%s 上厕所'%current_thread().getName()) time.sleep(random.randint(1,5)) sm.release() if __name__ == '__main__': for i in range(20): t = Thread(target = work) t.start()
事件
from threading import Thread,current_thread,Event import time event = Event()#默认为false def conn_mysql(): count = 1 while not event.is_set():#判断事件真假 if count>3: raise ConnectionError('链接失败') print('%s 等待第%s次链接mysql'%(current_thread().getName(),count)) event.wait(0.5) count+=1 print('%s 链接ok' % (current_thread().getName())) def check_mysql(): print('%s 正在检查mysql状态'%current_thread().getName()) time.sleep(1) event.set()#设置为真 if __name__ == '__main__': t1 = Thread(target=conn_mysql) t2 =Thread(target=conn_mysql) check= Thread(target=check_mysql) t1.start() t2.start() check.start()
concurrent.futures模块创建进程池线程池
#concurrent.futures 异步调用 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import os,time,random def work(n): print('%s is runing'%os.getpid()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': p = ProcessPoolExecutor() objs = [] for i in range(10): obj = p.submit(work,i) objs.append(obj) p.shutdown() #相当于进程池中的p.close() p.join for obj in objs: print(obj.result())#相当于进程池中的obj.get
#线程池 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import os,time,random from threading import current_thread def work(n): print('%s is runing'%current_thread().getName()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': p = ThreadPoolExecutor()#默认cpu*5 objs = [] for i in range(10): obj = p.submit(work,i) objs.append(obj) p.shutdown() #相当于进程池中的p.close() p.join for obj in objs: print(obj.result())#相当于进程池中的obj.get
#p = ThreadPoolExecutor()
#obj = p.map(work,range(10))
#p.shutdown()
#print(list(obj))
回调函数
import requests #pip3 install requests from concurrent.futures import ThreadPoolExecutor import os,time def get_page(url): print('<%s> get :%s' %(os.getpid(),url)) respone = requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} def parse_page(dic): #差异 dic = dic.result() print('<%s> parse :%s' %(os.getpid(),dic['url'])) time.sleep(0.5) res='url:%s size:%s ' %(dic['url'],len(dic['text'])) #模拟解析网页内容 with open('db.txt','a') as f: f.write(res) if __name__ == '__main__': p=ThreadPoolExecutor(4) urls = [ 'http://www.baidu.com', 'http://www.baidu.com', 'http://www.baidu.com', 'http://www.baidu.com', 'http://www.baidu.com', 'http://www.baidu.com', 'http://www.baidu.com', ] for url in urls: #与进程池的差异 p.submit(get_page,url).add_done_callback(parse_page) p.shutdown() print('主进程pid:',os.getpid())
协程
from gevent import monkey monkey.patch_all()#打补丁,打成gevent能识别的io import gevent import time def eat(name): print('%s eat 1'%name) # gevent.sleep(3) time.sleep(3) print('%s eat 2'%name) def play(name): print('%s play 1'%name) # gevent.sleep(2) time.sleep(2) print('%s play 2'%name) g1 = gevent.spawn(eat,'egon')#异步提交方式 g2 = gevent.spawn(play,'egon') gevent.joinall([g1,g2]) #单线程下两个任务,先提交eat,睡3秒gevent检测到io切换到第二个任务,第二个遇到io切换eat,来回切,直到两秒睡完执行play2,一共花费3秒 #但是gevent不识别time.sleep(2),需要导入monkey
协程之socket
#服务端 from gevent import monkey;monkey.patch_all() from socket import * import gevent #如果不想用money.patch_all()打补丁,可以用gevent自带的socket # from gevent import socket # s=socket.socket() def server(server_ip,port): s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((server_ip,port)) s.listen(5) while True: conn,addr=s.accept() gevent.spawn(talk,conn,addr) def talk(conn,addr): try: while True: res=conn.recv(1024) print('client %s:%s msg: %s' %(addr[0],addr[1],res)) conn.send(res.upper()) except Exception as e: print(e) finally: conn.close() if __name__ == '__main__': server('127.0.0.1',8080)