最近新系统上线,刷缓存刷个不停, 准备利用语音完成此操作,解放双手,不知道能不能实现,先一点点来。。
准备利用语音完成此操作,解放双手,不知道能不能实现,先一点点来。。
实现步骤拆分:
1、语音识别(百度语音识别api)
2、识别后操作前台实现刷新缓存
3、。。。
想要调用百度的语音识别功能,需要如下步骤
1、需要先注册百度云的账号
2、在控制台中创建个应用,获取到API Key 和 Secret Key
3、根据文档中心手册,使用(speech/len方式)JSON格式POST上传本地文件到 http://vop.baidu.com/server_api 或 https://vop.baidu.com/server_api
4、根据返回查看报错或成功解析后文字
1)第一步不说
2)第二步完成如图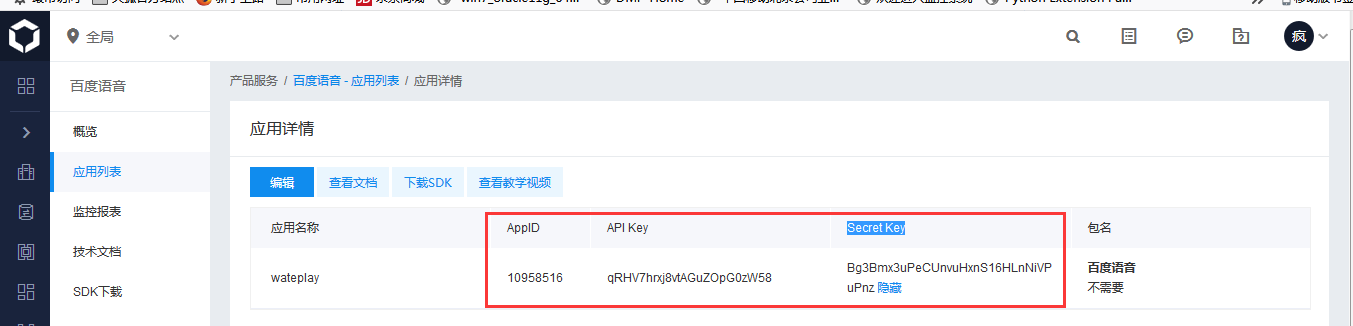
3)json 参数
JSON方式上传
语音数据和其他参数通过标准 JSON 格式串行化 POST 上传, JSON 里包括的参数:
| 字段名 | 可需 | 描述 |
|---|---|---|
| format | 必填 | 语音文件的格式,pcm 或者 wav 或者 amr。不区分大小写。推荐pcm文件 |
| rate | 必填 | 采样率,16000,固定值 |
| channel | 必填 | 声道数,仅支持单声道,请填写固定值 1 |
| cuid | 必填 | 用户唯一标识,用来区分用户,计算UV值。建议填写能区分用户的机器 MAC 地址或 IMEI 码,长度为60字符以内。 |
| token | 必填 | 开放平台获取到的开发者[access_token]获取 Access Token "access_token") |
| dev_pid | 选填 | 不填写lan参数生效,都不填写,默认1537(普通话 输入法模型),dev_pid参数见本节开头的表格 |
| lan | 选填,废弃参数 | 历史兼容参数,请使用dev_pid。如果dev_pid填写,该参数会被覆盖。语种选择,输入法模型,默认中文(zh)。 中文=zh、粤语=ct、英文=en,不区分大小写。 |
| url | 选填 | 可下载的语音下载地址,与callback连一起使用,确保百度服务器可以访问。 |
| callback | 选填 | 用户服务器的识别结果回调地址,确保百度服务器可以访问 |
| speech | 选填 | 本地语音文件的的二进制语音数据 ,需要进行base64 编码。与len参数连一起使用。 |
| len | 选填 | 本地语音文件的的字节数,单位字节 |
样例:
{
"format":"pcm",
"rate":16000,
"dev_pid":1536,
"channel":1,
"token":xxx,
"cuid":"baidu_workshop",
"len":4096,
"speech":"xxx", // xxx为 base64(FILE_CONTENT)
}
注意点:formate 为 语音文件格式
格式支持:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式);固定16k 采样率;
cuid:可以随意填,但是必须要有
speech为base64编码格式
dev_pid为不通语种
| dev_pid | 语言 | 模型 | 是否有标点 | 备注 |
|---|---|---|---|---|
| 1536 | 普通话(支持简单的英文识别) | 搜索模型 | 无标点 | 仅采样率16000支持自定义词库 |
| 1537 | 普通话(纯中文识别) | 输入法模型 | 可以有标点 | 不支持自定义词库 |
| 1736 | 英语 | 搜索模型 | 无标点 | 不支持自定义词库 |
| 1737 | 英语 | 输入法模型 | 可以有标点 | 不支持自定义词库 |
| 1636 | 粤语 | 搜索模型 | 无标点 | 不支持自定义词库 |
| 1637 | 粤语 | 输入法模型 | 可以有标点 | 不支持自定义词库 |
| 1836 | 四川话 | 搜索模型 | 无标点 | 不支持自定义词库 |
| 1837 | 四川话 | 输入法模型 | 可以有标点 | 不支持自定义词库 |
token参数的获取:
使用Client Credentials获取Access Token需要应用在其服务端发送请求(推荐用POST方法)到百度OAuth2.0授权服务的“ https://openapi.baidu.com/oauth/2.0/token ”地址上,并带上以下参数:
- grant_type:必须参数,固定为“client_credentials”;
- client_id:必须参数,应用的 API Key;
- client_secret:必须参数,应用的 Secret Key;
** 例如:**
https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=Va5yQRHl********LT0vuXV4&client_secret= 0rDSjzQ20XUj5i********PQSzr5pVw2&
我们只需利用requests模块发送post请求到拼出来的url就可以了。
import requests #获取tokent baidu_server = "https://openapi.baidu.com/oauth/2.0/token?" grant_type = "client_credentials" #API Key client_id = "qRHV7hrxj8vtAGuZOpG0zW58" #Secret Key client_secret = "Bg3Bmx3uPeCUnvuHxnS16HLnNiVPuPnz" #拼url url ="%sgrant_type=%s&client_id=%s&client_secret=%s"%(server,grant_type,client_id,client_secret) print(url) #获取token res = requests.post(url) print(res.text) token = json.loads(res.text)["access_token"] print(token)
#24.b891f76f5d48c0b9587f72e43b726817.2592000.1524124117.282335-10958516
然后拼凑json数据
#设置格式 RATE = "16000" FORMAT = "amr" CUID="wate_play" DEV_PID="1536" #以字节格式读取文件之后进行编码 with open(r'C:UsersAdministratorDesktop16k-23850.amr', "rb") as f: speech = base64.b64encode(f.read()).decode('utf8') size = os.path.getsize(r'C:UsersAdministratorDesktop16k-23850.amr') headers = { 'Content-Type' : 'application/json'} url = "https://vop.baidu.com/server_api" data={ "format":FORMAT, "rate":RATE, "dev_pid":DEV_PID, "speech":speech, "cuid":CUID, "len":size, "channel":1, "token":token, } req = requests.post(url,json.dumps(data),headers) result = json.loads(req.text) print(result["result"][0])
运行出结果!
示例音频文件下载:http://speech-doc.gz.bcebos.com/rest-api-asr/public_audio/16k.pcm
speech-doc.gz.bcebos.com/rest-api-asr/public_audio/16k.wav
speech-doc.gz.bcebos.com/rest-api-asr/public_audio/16k-23850.amr
-----------------------------------------------------------------------------------------------------
第二阶段,利用python的 PyAudio 模块,进行录音
参考文档:http://old.sebug.net/paper/books/scipydoc/wave_pyaudio.html#pymediamp3
WAV是Microsoft开发的一种声音文件格式,虽然它支持多种压缩格式,不过它通常被用来保存未压缩的声音数据(PCM脉冲编码调制)。WAV有三个重要的参数:声道数、取样频率和量化位数。
- 声道数:可以是单声道或者是双声道
- 采样频率:一秒内对声音信号的采集次数,常用的有8kHz, 16kHz, 32kHz, 48kHz, 11.025kHz, 22.05kHz, 44.1kHz
- 量化位数:用多少bit表达一次采样所采集的数据,通常有8bit、16bit、24bit和32bit等几种
理论知识不多说了,上面链接中都有的。直接上代码。。
import wave from pyaudio import PyAudio,paInt16 import json import base64 import os import requests import time RATE = "16000" FORMAT = "wav" CUID="wate_play" DEV_PID="1536" framerate=16000 NUM_SAMPLES=2000 channels=1 sampwidth=2 TIME=2 def get_token(): server = "https://openapi.baidu.com/oauth/2.0/token?" grant_type = "client_credentials" #API Key client_id = "qRHV7hrxj8vtAGuZOpG0zW58" #Secret Key client_secret = "Bg3Bmx3uPeCUnvuHxnS16HLnNiVPuPnz" #拼url url ="%sgrant_type=%s&client_id=%s&client_secret=%s"%(server,grant_type,client_id,client_secret) #获取token res = requests.post(url) token = json.loads(res.text)["access_token"] return token def get_word(token): with open(r'C:UsersAdministratorDesktop�1.wav', "rb") as f: speech = base64.b64encode(f.read()).decode('utf8') size = os.path.getsize(r'C:UsersAdministratorDesktop�1.wav') headers = { 'Content-Type' : 'application/json'} url = "https://vop.baidu.com/server_api" data={ "format":FORMAT, "rate":RATE, "dev_pid":DEV_PID, "speech":speech, "cuid":CUID, "len":size, "channel":1, "token":token, } req = requests.post(url,json.dumps(data),headers) result = json.loads(req.text) print(result) ret=result["result"][0] return result def save_wave_file(filename,data): '''save the date to the wavfile''' wf=wave.open(filename,'wb') wf.setnchannels(channels) wf.setsampwidth(sampwidth) wf.setframerate(framerate) wf.writeframes(b"".join(data)) wf.close() def my_record(): pa=PyAudio() stream=pa.open(format = paInt16,channels=1, rate=framerate,input=True, frames_per_buffer=NUM_SAMPLES) my_buf=[] count=0 print('.') while count<TIME*10:#控制录音时间 string_audio_data = stream.read(NUM_SAMPLES) my_buf.append(string_audio_data) count+=1 save_wave_file('01.wav',my_buf) stream.close() chunk=2014 def play(): wf=wave.open(r"01.wav",'rb') p=PyAudio() stream=p.open(format=p.get_format_from_width(wf.getsampwidth()),channels= wf.getnchannels(),rate=wf.getframerate(),output=True) while True: data=wf.readframes(chunk) if data=="":break stream.write(data) stream.close() p.terminate() if __name__ == '__main__': while True: time.sleep(5) my_record() token=get_token() try: ret = get_word(token) except: print('失败了') print(ret)
循环录音,识别准确性还算不错,可以把常用的词放到txt中上传到,百度云应用中增加识别优先级。