作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.列表,元组,字典,集合的增删改查及遍历
| 操作 | 方法 | 示例 |
| 增加 |
list.append(obj) 增加元素到末尾 |

list=['Michael','Bob','Tracy','李三','Tracy','Sarah']
list.append('张四')
print(list)
|
|
list.insert(index, obj) 增加元素到指定位置 |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah']
list.insert(1,'Jack')
print(list)
|
|
|
list.extend(list2) 将list2列表中的元素增加到list中 |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah']
list2=['张四','Jack']
list.extend(list2)
print(list)
|
|
| 删除 |
list.pop(index) 删除指定位置的元素 list.pop() 删除最后一个元素 |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah']
list2=['张四','Jack']
list.pop(1)
list2.pop()
print(list,list2)
|
| 修改 |
list[index]=obj 修改指定位置的元素 |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah']
list[2]='张四'
print(list)
|
| 查询 |
list[index] 通过下标索引,从0开始 |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah']
print(list[2])
|
|
list[a:b] 切片,从哪里到哪里 |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah']
print(list[1:4])
|
|
| 遍历 |
for x in list |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah'] for x in list: print(x, end=",")
|
|
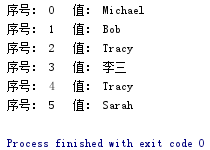
for i in range(len(list)) |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah'] for i in range(len(list)): print("序号:", i, " 值:", list[i])
|
|
|
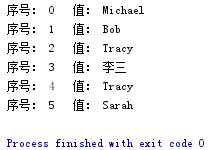
for i,val in enumerate(list) |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah'] for i, val in enumerate(list): print("序号:", i, " 值:", val) |
|
|
for i in list |
list=['Michael','Bob','Tracy','李三','Tracy','Sarah'] for i in list: idx = list.index(i) # 索引 if (idx < len(list) - 1): print(i, '---------', list[idx + 1]) |










| 操作 | 方法 | 示例 |
| 增加 |
tup=tup1+tup2 元组不支持修改,但可以通过连接组合的方式进行增加 |
tup1=('Michael','Bob','Tracy','李三','Tracy','Sarah')
tup2=('张四','Jack')
tup=tup1+tup2
print(tup)
|
| 删除 |
del tup 元组不支持单个元素删除,但可以删除整个元组 |
tup=('Michael','Bob','Tracy','李三','Tracy','Sarah')
print(tup)
del tup
print(tup)
|
| 修改 |
tup[index]=obj 修改指定位置的元素 元组和列表转换 |
tup=('Michael','Bob','Tracy','李三','Tracy','Sarah') tup=list(tup) tup[0]='张四' tup[1]='Jacky' tup=tuple(tup) print(tup)
|
| 查询 |
tup[index] 通过下标索引,从0开始 |
tup=('Michael','Bob','Tracy','李三','Tracy','Sarah') print(tup[2])
|
|
tup[a:b] 切片,顾头不顾尾 |
tup=('Michael','Bob','Tracy','李三','Tracy','Sarah') print(tup[2:5])
|
|
|
遍历 |
for x in (tup) |
tup=('Michael','Bob','Tracy','李三','Tracy','Sarah') for x in (tup): print(x)
|






| 操作 | 方法 | 示例 |
| 增加 |
dict[key]=value 通过赋值的方法增加元素 |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
dict['张四']=8
print(dict)
|
| 删除 |
del dict[key] 删除单一元素,通过key来指定删除 |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
del dict['Bob']
print(dict)
|
|
dict.pop(key) 删除单一元素,通过key来指定删除 |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
dict.pop('Tracy')
print(dict)
|
|
| 修改 |
dict[key]=value 通过对已有的key重新赋值的方法修改 |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
dict['Bob']=8
print(dict)
|
| 查询 |
dict[key] 通过key访问value值 |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
print(dict['李三'])
|
|
dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
print(dict.items())
|
|
|
dict.keys() 以列表返回一个字典所有键值 dict.values() 以列表返回一个字典所有值 |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
print(dict.keys(),dict.values())
|
|
|
dict.get(key) 返回指定key的对应字典值,没有返回none |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
print(dict.get('Michael'))
|
|
| 遍历 |
for key in dict.keys() |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
for key in dict.keys():
print(key)
|
|
for val in dict.values() |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
for val in dict.values():
print(val)
|
|
|
for key,val in dict.items() |
dict={'Michael':1,'Bob':5,'Tracy':3,'李三':7,'Tracy':6,'Sarah':9}
for key, val in dict.items():
print(key, " : ", val)
|











| 操作 | 方法 | 示例 |
| 增加 |
s.add(obj) 在集合s中添加对象obj |
s=set(['Michael','Bob','Tracy','李三','Tracy','Sarah']) s.add('张四') print(s)
|
| 删除 |
s.remove(obj) 从集合s中删除对象obj |
s=set(['Michael','Bob','Tracy','李三','Tracy','Sarah']) s.remove('Bob') print(s)
|
| 修改 |
s[index]=obj 修改指定位置的元素 集合和列表转换 |
s=set(['Michael','Bob','Tracy','李三','Tracy','Sarah']) s=list(s) s[2]='张四' s=set(s) print(s)
|
| 遍历 | for x in s |
s=set(['Michael','Bob','Tracy','李三','Tracy','Sarah']) for x in s: print(x)
|


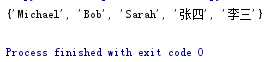

2.总结列表,元组,字典,集合的联系与区别
(1)列表
- 列表list,用中括号“[ ]”表示
- 列表是一组任意类型的值,按照一定顺序组合而成的
- 可以随时添加删除修改其中的元素
- 元素可重复
- 存储时每一个元素被标识一个索引,每当引用时,会将这个引用指向一个对象,所以程序只需处理对象的操作
(2)元组
- 元组tuple,用小括号“( )”表示
- 与列表相同,有序
- 一旦初始化就不能修改
- 元素可重复
- 与列表相似,元组是对象引用的数组
(3)字典
- 字典dict,用大括号“{key,value}”表示
- 字典中的项没有特定顺序,以“键”为象征
- 因为是无序,故不能进行序列操作,但可以在远处修改,通过键映射到值
- key不能重复
- 字典存储的是对象引用,不是拷贝,和列表一样
(4)集合
- 集合set,用小括号“( )”表示
- 无序
- 可变,可以添加和删除元素
- 无重复
- 与列表相似
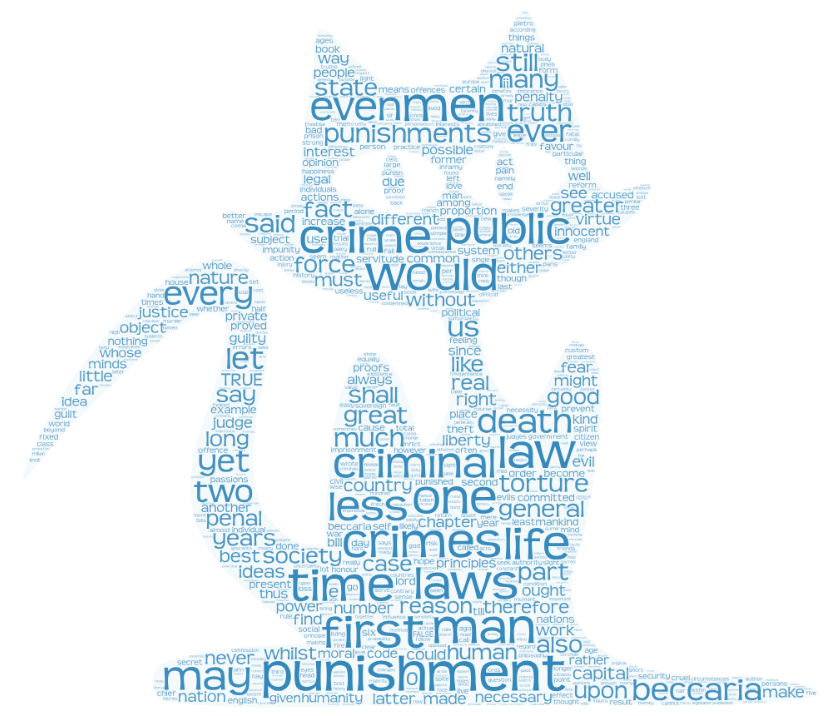
3.词频统计
# import nltk # nltk.download("stopwords") from nltk.corpus import stopwords stops=set(stopwords.words('english')) #通过文件读取字符串 str,对文本进行预处理 def gettxt(): sep=".,:;?!-_'" txt=open('Crimes and Punishments.txt','r', encoding='UTF-8').read().lower() for ch in sep: txt=txt.replace(ch,' ') return txt #分解提取单词 list txtList=gettxt().split() print(txtList) print('crimes:',txtList.count('crimes')) txtSet=set(txtList) #排除语法型词汇,单词计数字典 set , dict txtSet=txtSet-stops print(txtSet) txtDict={} for word in txtSet: txtDict[word]=txtList.count(word) print(txtDict) print(txtDict.items()) word=list(txtDict.items()) #按词频排序 list.sort(key=lambda),turple word.sort(key=lambda x:x[1],reverse=True) print(word) #输出频率较高的词语top20# for i in range(20): print(word[i]) #排序好的单词列表word保存成csv文件 import pandas as pd pd.DataFrame(data=word).to_csv('Crimes and Punishments.csv',encoding='utf-8')
结果如下图:

词云如下图: