1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
(1)逻辑回归是怎么防止过拟合的?
1. 可以增加样本量,这是万能的方法,适用任何模型。
2. 如果数据比较稀疏,使用L1正则,其他情况,用L2要好,可自己尝试。
3. 通过特征选择,剔除一些不重要的特征,从而降低模型复杂度。
4. 如果还过拟合,那就看看是否使用了过度复杂的特征构造工程,比如,某两个特征相乘/除/加等方式构造的特征,不要这样做了,保持原特征。
5. 检查业务逻辑,判断特征有效性,是否在用结果预测结果等。
6.最重要的,逻辑回归特有的防止过拟合方法:进行离散化处理,所有特征都离散化。
(2)为什么正则化可以防止过拟合?
过拟合的时候,拟合函数的系数往往非常大,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
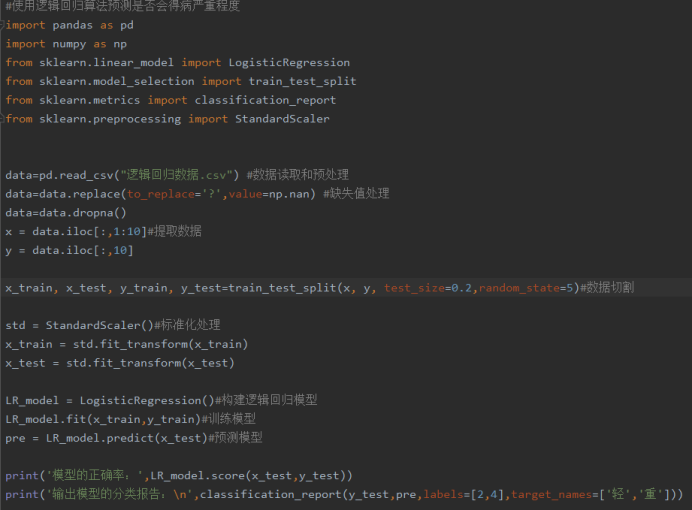
2.用logiftic回归来进行实践操作,数据不限。
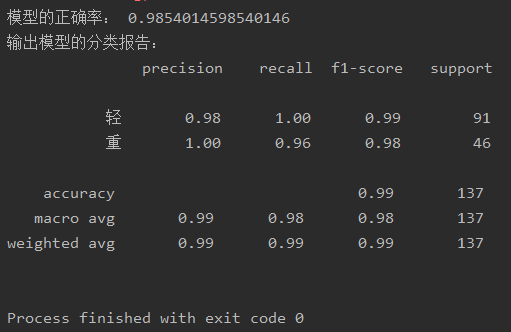
#使用逻辑回归算法预测是否会得病严重程度 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.preprocessing import StandardScaler data=pd.read_csv("逻辑回归数据.csv") #数据读取和预处理 data=data.replace(to_replace='?',value=np.nan) #缺失值处理 data=data.dropna() x = data.iloc[:,1:10]#提取数据 y = data.iloc[:,10] x_train, x_test, y_train, y_test=train_test_split(x, y, test_size=0.2,random_state=5)#数据切割 std = StandardScaler()#标准化处理 x_train = std.fit_transform(x_train) x_test = std.fit_transform(x_test) LR_model = LogisticRegression()#构建逻辑回归模型 LR_model.fit(x_train,y_train)#训练模型 pre = LR_model.predict(x_test)#预测模型 print('模型的正确率:',LR_model.score(x_test,y_test)) print('输出模型的分类报告: ',classification_report(y_test,pre,labels=[2,4],target_names=['轻','重']))