前言
因为比赛的限制是使用Hadoop2.7.2,估在此文章下面的也是使用Hadoop2.7.2,具体下载地址为Hadoop2.7.2
开始的准备
目前在我的实验室上有三台Linux主机,因为需要参加一个关于spark数据分析的比赛,所以眼见那几台服务器没有人用,我们团队就拿来配置成集群。具体打算配置如下的集群
| 主机名 | IP地址(内网) |
|---|---|
| SparkMaster | 10.21.32.106 |
| SparkWorker1 | 10.21.32.109 |
| SparkWorker2 | 10.21.32.112 |
首先进行的是ssh免密码登录的操作
具体操作在上一篇学习日记当中已经写到了,在此不再详细说。
配置Java环境
因为我那三台电脑也是配置好了JDK了,所以在此也不详细说。
配置好Java的机子可以使用
java -version
来查看Java的版本
下载Hadoop2.7.2
因为我最后的文件是放在/usr/local下面的,所以我也直接打开/usr/local文件夹下。直接
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
安装Hadoop以及配置Hadoop环境
解压
tar -zxvf hadoop-2.7.2.tar.gz
删除
rm -rf hadoop-2.7.2.tar.gz
解压删除之后打开hadoop-2.7.2文件夹,在etc/hadoop/hadoop-env.sh中配置JDK的信息
先查看本机的jdk目录地址在哪里
echo $JAVA_HOME

vi etc/hadoop/hadoop-env.sh
将
export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/java/jdk1.8.0_131

为了方便我们以后开机之后可以立刻使用到Hadoop的bin目录下的相关命令,可以把hadoop文件夹下的bin和sbin目录配置到/etc/profile文件中。
vi /etc/profile
添加
export PATH=$PATH:/usr/local/hadoop-2.7.2/bin:/usr/local/hadoop-2.7.7/sbin
按一下esc,按着shift+两次z键保存
使用
source /etc/profile

使得命令配置信息生效,是否生效可以通过
hadoop version
查看
配置Hadoop分布式集群
前言
考虑是为了建立
spark集群,所以主机命名为SparkMasterSparkWorker1SparkWorker2
修改主机名
vi /etc/hostname
修改里面的名字为SprakMaster,按一下esc,按着shift+两次z键保存。

设置hosts文件使得主机名和IP地址对应关系
vi /etc/hosts

配置主机名和IP地址的对应关系。

Ps:其他两台slave的主机也修改对应的SparkWorker1 SparkWorker2,如果修改完主机名字之后户籍的名字没有生效,那么重启系统便可以。三台机子的hostname与hosts均要修改

在三台机子的总的hadoop-2.7.2文件夹下建立如下四个文件夹
- 目录/tmp,用来存储临时生成的文件
- 目录/hdfs,用来存储集群数据
- 目录hdfs/data,用来存储真正的数据
- 目录hdfs/name,用来存储文件系统元数据
mkdir tmp hdfs hdfs/data hdfs/name
配置hadoop文件
在此先修改SparkMaster的配置文件,然后修改完毕后通过
rsync命令复制到其他节点电脑上。
修改core-site.xml
vi etc/hadoop/core-site.xml
具体修改如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://SparkMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.2/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
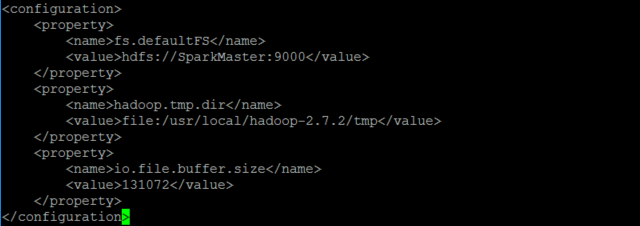
变量fs.defaultFS保存了NameNode的位置,HDFS和MapReduce组件都需要它。这就是它出现在core-site.xml文件中而不是hdfs-site.xml文件中的原因。
修改marpred-site.xml
具体修改如下
首先我们需要的是将marpred-site.xml复制一份:
cp etc/hadoop/marpred-site.xml.template etc/hadoop/marpred-site.xml
vi etc/hadoop/marpred-site.xml.template
此处修改的是
marpred-site.xml,不是marpred-site.xml.template。
具体修改如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>SparkMaster:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>SparkMaster:19888</value>
</property>
</configuration>
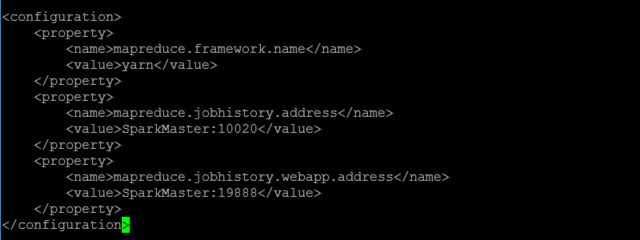
修改hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
具体修改如下
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.2/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>SparkMaster:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
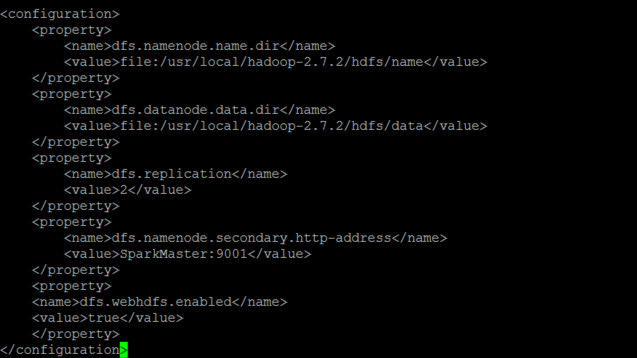
PS:变量dfs.replication指定了每个HDFS数据块的复制次数,即HDFS存储文件的副本个数.我的实验环境只有一台Master和两台Worker(DataNode),所以修改为2。
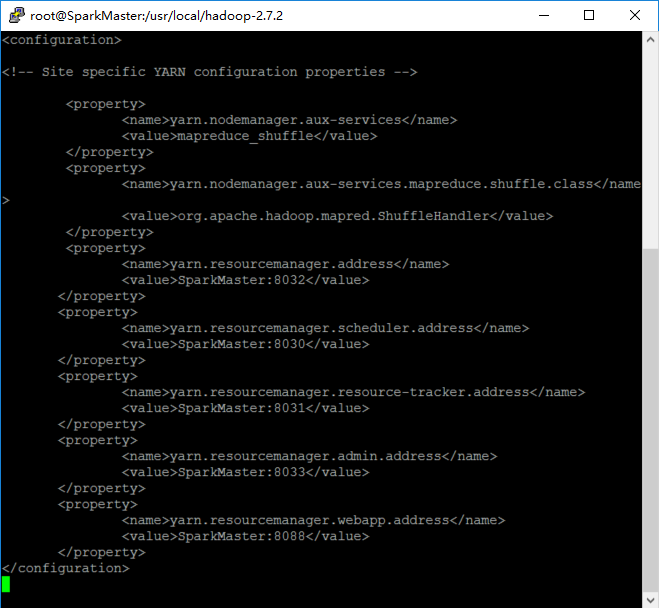
配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
具体配置如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>SparkMaster:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>SparkMaster:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>SparkMaster:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>SparkMaster:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>SparkMaster:8088</value>
</property>
</configuration>
修改slaves的内容
将localhost修改成为SparkWorker1、SparkWorker2

将SparkMaster节点的`hadoop-2.7.2/etc/下面的文件通过以下方式放去其他节点
rsync -av /usr/local/hadoop-2.7.2/etc/ SparkWorker1:/usr/local/hadoop-2.7.2/etc/
rsync -av /usr/local/hadoop-2.7.2/etc/ SparkWorker1:/usr/local/hadoop-2.7.2/etc/
完成之后可以查看SparkWorker1、SparkWorker2下面的文件是否变了
启动hadoop分布式集群
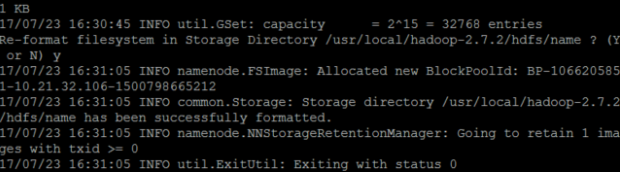
在SparkMaster节点格式化集群的文件系统
输入
hadoop namenode -format
启动Hadoop集群
start-all.sh

查看各个节点的进程信息
使用
jps
查看各节点的进程信息
可以看到



此时分布式的hadoop集群已经搭好了
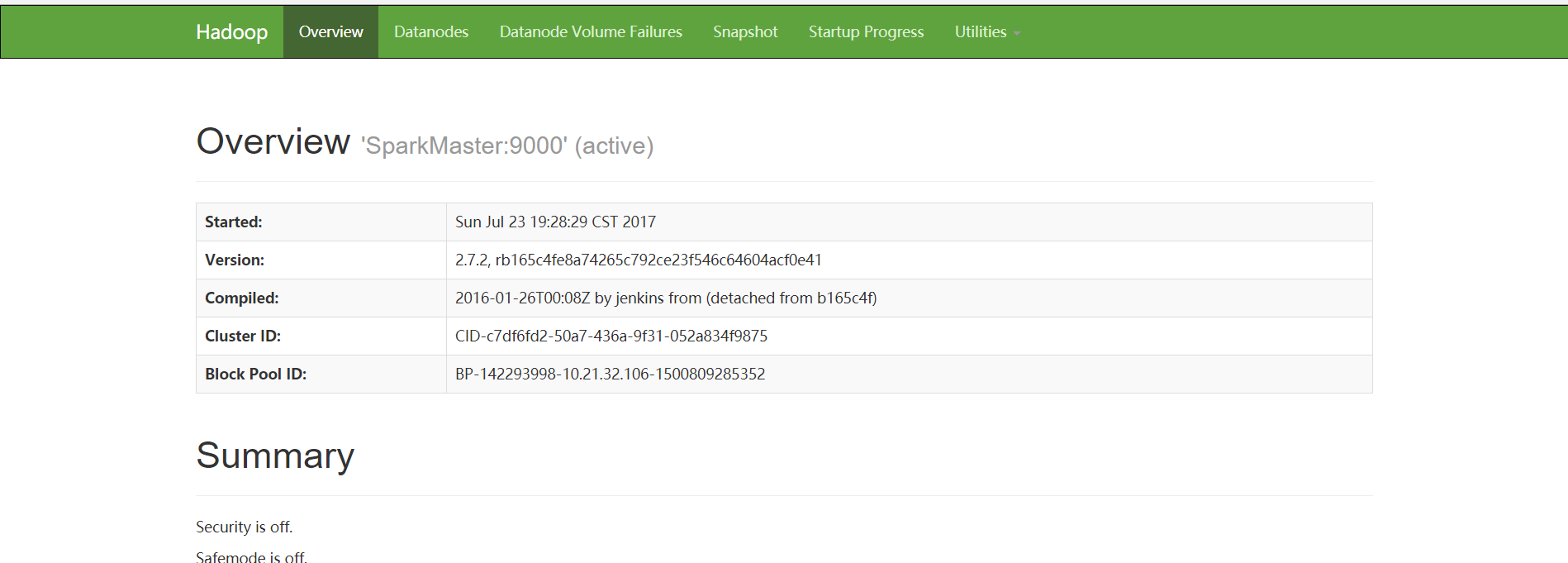
在浏览器输入
SparkMaster_IP:50070
SparkMaster_IP:8088
看到以下界面代表Hadoop集群已经开启了

结言
到此Hadoop的分布式集群就搭好了。这个Spark运行的基础。
参见:CentOS 6.7安装Hadoop 2.7.2
++王家林/王雁军/王家虎的《Spark 核心源码分析与开发实战》++
文章出自kwongtai'blog,转载请标明出处!