目标:sparkStreaming每2s中读取一次kafka中的数据,进行单词计数。
topic:topic1
broker list:192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092
1、首先往一个topic中实时生产数据。
代码如下: 代码功能:每秒向topic1发送一条消息,一条消息里包含4个单词,单词之间用空格隔开。
1 package kafkaProducer 2 3 import java.util.HashMap 4 5 import org.apache.kafka.clients.producer._ 6 7 8 object KafkaProducer { 9 def main(args: Array[String]) { 10 val topic="topic1" 11 val brokers="192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092" 12 val messagesPerSec=1 //每秒发送几条信息 13 val wordsPerMessage =4 //一条信息包括多少个单词 14 // Zookeeper connection properties 15 val props = new HashMap[String, Object]() 16 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers) 17 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, 18 "org.apache.kafka.common.serialization.StringSerializer") 19 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, 20 "org.apache.kafka.common.serialization.StringSerializer") 21 val producer = new KafkaProducer[String, String](props) 22 // Send some messages 23 while(true) { 24 (1 to messagesPerSec.toInt).foreach { messageNum => 25 val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString) 26 .mkString(" ") 27 val message = new ProducerRecord[String, String](topic, null, str) 28 producer.send(message) 29 println(message) 30 } 31 Thread.sleep(1000) 32 } 33 } 34 }
打包运行命令:hadoop jar jar包 (注意jar包是可运行的jar包)
消费者消费命令: ./kafka-console-consumer.sh --zookeeper zk01:2181,zk02:2181 --topic topic1 --from-beginning
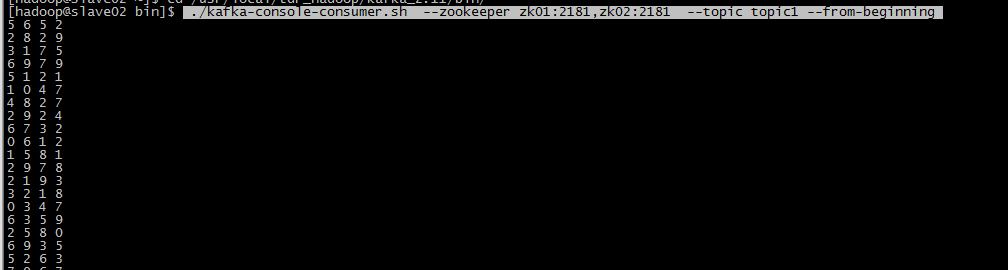
可以正常消费。
2、编写SparkStreaming代码读kafka中的数据,每2s读一次
代码如下:
1 package kafkaSparkStream 2 3 import org.apache.spark.SparkConf 4 import org.apache.spark.streaming.StreamingContext 5 import org.apache.spark.streaming.Seconds 6 import org.apache.spark.streaming.kafka.KafkaUtils 7 import kafka.serializer.StringDecoder 8 /** 9 * sparkStreaming读取kafka中topic的数据 10 */ 11 object KafkaToSpark { 12 def main(args: Array[String]) { 13 if (args.length<2) { 14 System.err.println("Usage: <brokers> <topics>"); 15 System.exit(1) 16 } 17 val Array(brokers,topics)=args 18 //2s从kafka中读取一次 19 val conf=new SparkConf().setAppName("KafkaToSpark"); 20 val scc=new StreamingContext(conf,Seconds(2)) 21 // Create direct kafka stream with brokers and topics 22 val topicSet=topics.split(",").toSet 23 val kafkaParams=Map[String,String]("metadata.broker.list"->brokers) 24 //获取信息 25 val messages=KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( 26 scc,kafkaParams,topicSet) 27 // Get the lines, split them into words, count the words and print 28 val lines= messages.map(_._2) 29 val words=lines.flatMap(_.split(" ")) 30 val wordCouts=words.map(x =>(x,1L)).reduceByKey(_+_) 31 wordCouts.print 32 //开启计算 33 scc.start() 34 scc.awaitTermination() 35 } 36 37 }
打包运行命令:./spark-submit --class kafkaSparkStream.KafkaToSpark --master yarn-client /home/hadoop/sparkJar/kafkaToSpark.jar 192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092 topic1
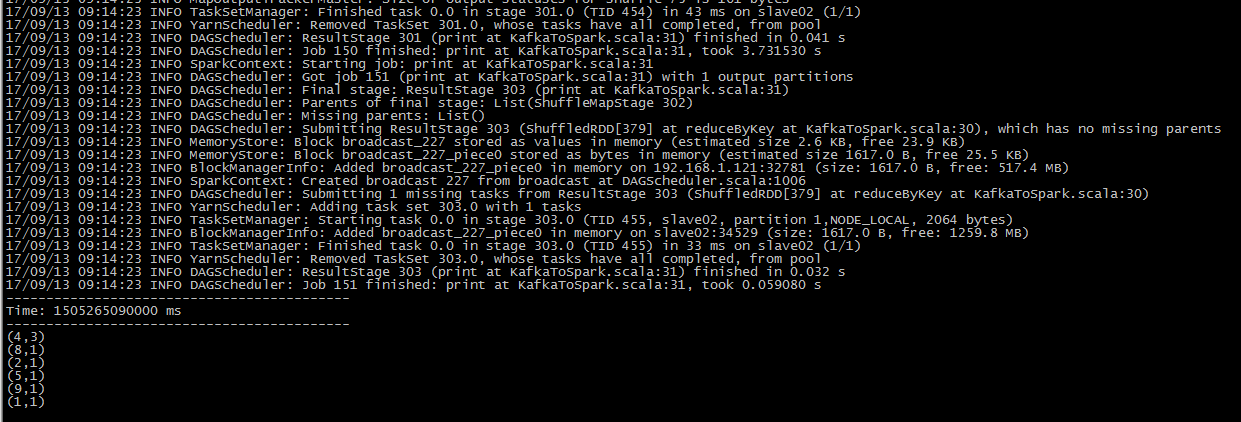
运行成功!