四、三种特殊数据类型
Geospatial(地理位置)
使用经纬度定位地理坐标并用一个有序集合zset保存,所以zset命令也可以使用
geoadd key longitud(经度) latitude(纬度) member [..]将具体经纬度的坐标存入一个有序集合geopos key member [member..]获取集合中的一个/多个成员坐标geodist key member1 member2 [unit]返回两个给定位置之间的距离。默认以米作为单位。georadius key longitude latitude radius m|km|mi|ft [WITHCOORD][WITHDIST] [WITHHASH] [COUNT count]以给定的经纬度为中心, 返回集合包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。GEORADIUSBYMEMBER key member radius...功能与GEORADIUS相同,只是中心位置不是具体的经纬度,而是使用结合中已有的成员作为中心点。geohash key member1 [member2..]返回一个或多个位置元素的Geohash表示。使用Geohash位置52点整数编码。
有效经纬度
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
指定单位的参数 unit 必须是以下单位的其中一个:
m 表示单位为米。
km 表示单位为千米。
mi 表示单位为英里。
ft 表示单位为英尺。
关于GEORADIUS的参数
通过georadius就可以完成 附近的人功能
withcoord:带上坐标
withdist:带上距离,单位与半径单位相同
COUNT n : 只显示前n个(按距离递增排序)
----------------georadius--------------------- 127.0.0.1:6379> GEORADIUS china:city 120 30 500 km withcoord withdist # 查询经纬度(120,30)坐标500km半径内的成员 1) 1) "hangzhou" 2) "29.4151" 3) 1) "120.20000249147415" 2) "30.199999888333501" 2) 1) "shanghai" 2) "205.3611" 3) 1) "121.40000134706497" 2) "31.400000253193539"------------geohash---------------------------
127.0.0.1:6379> geohash china:city yichang shanghai # 获取成员经纬坐标的geohash表示
- "wmrjwbr5250"
"wtw6ds0y300"
Hyperloglog(基数统计)
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
其底层使用string数据类型。
什么是基数?
数据集中不重复的元素的个数。
应用场景:
网页的访问量(UV):一个用户多次访问,也只能算作一个人。
传统实现,存储用户的id,然后每次进行比较。当用户变多之后这种方式及其浪费空间,而我们的目的只是计数,Hyperloglog就能帮助我们利用最小的空间完成。
PFADD key element1 [elememt2..]添加指定元素到 HyperLogLog中PFCOUNT key [key]返回给定 HyperLogLog 的基数估算值。PFMERGE destkey sourcekey [sourcekey..]将多个 HyperLogLog 合并为一个 HyperLogLog
代码示例
----------PFADD--PFCOUNT--------------------- 127.0.0.1:6379> PFADD myelemx a b c d e f g h i j k # 添加元素 (integer) 1 127.0.0.1:6379> type myelemx # hyperloglog底层使用String string 127.0.0.1:6379> PFCOUNT myelemx # 估算myelemx的基数 (integer) 11 127.0.0.1:6379> PFADD myelemy i j k z m c b v p q s (integer) 1 127.0.0.1:6379> PFCOUNT myelemy (integer) 11
----------------PFMERGE-----------------------
127.0.0.1:6379> PFMERGE myelemz myelemx myelemy # 合并myelemx和myelemy 成为myelemz
OK
127.0.0.1:6379> PFCOUNT myelemz # 估算基数
(integer) 17
BitMaps(位图)
使用位存储,信息状态只有 0 和 1
Bitmap是一串连续的2进制数字(0或1),每一位所在的位置为偏移(offset),在bitmap上可执行AND,OR,XOR,NOT以及其它位操作。
应用场景: 签到统计、状态统计
setbit key offset value为指定key的offset位设置值getbit key offset获取offset位的值bitcount key [start end]统计字符串被设置为1的bit数,也可以指定统计范围按字节bitop operration destkey key[key..]对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。BITPOS key bit [start] [end]返回字符串里面第一个被设置为1或者0的bit位。start和end只能按字节,不能按位
代码示例
------------setbit--getbit-------------- 127.0.0.1:6379> setbit sign 0 1 # 设置sign的第0位为 1 (integer) 0 127.0.0.1:6379> setbit sign 2 1 # 设置sign的第2位为 1 不设置默认 是0 (integer) 0 127.0.0.1:6379> setbit sign 3 1 (integer) 0 127.0.0.1:6379> setbit sign 5 1 (integer) 0 127.0.0.1:6379> type sign string127.0.0.1:6379> getbit sign 2 # 获取第2位的数值
(integer) 1
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 4 # 未设置默认是0
(integer) 0
-----------bitcount----------------------------
127.0.0.1:6379> BITCOUNT sign # 统计sign中为1的位数
(integer) 4
五、事务
Redis的单条命令是保证原子性的,但是redis事务不能保证原子性
Redis事务本质:一组命令的集合。----------------- 队列 set set set 执行 -------------------
事务中每条命令都会被序列化,执行过程中按顺序执行,不允许其他命令进行干扰。
一次性
顺序性
排他性
Redis事务没有隔离级别的概念
Redis单条命令是保证原子性的,但是事务不保证原子性!
Redis事务操作过程
- 开启事务(multi)
- 命令入队
- 执行事务(exec)
所以事务中的命令在加入时都没有被执行,直到提交时才会开始执行(Exec)一次性完成。
正常执行
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v1 # 命令入队
QUEUED
127.0.0.1:6379> set k2 v2 # ..
QUEUED
127.0.0.1:6379> get k1
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> exec # 事务执行
1) OK
2) OK
3) "v1"
4) OK
5) 1) "k3"
2) "k2"
3) "k1"
取消事务(discurd)
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> DISCARD # 放弃事务
OK
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI # 当前未开启事务
127.0.0.1:6379> get k1 # 被放弃事务中命令并未执行
(nil)
事务错误
代码语法错误(编译时异常)所有的命令都不执行
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> error k1 # 这是一条语法错误命令
(error) ERR unknown command `error`, with args beginning with: `k1`, # 会报错但是不影响后续命令入队
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors. # 执行报错
127.0.0.1:6379> get k1
(nil) # 其他命令并没有被执行
代码逻辑错误 (运行时异常) **其他命令可以正常执行 ** >>> 所以不保证事务原子性
127.0.0.1:6379> multi OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> INCR k1 # 这条命令逻辑错误(对字符串进行增量) QUEUED 127.0.0.1:6379> get k2 QUEUED 127.0.0.1:6379> exec 1) OK 2) OK 3) (error) ERR value is not an integer or out of range # 运行时报错 4) "v2" # 其他命令正常执行虽然中间有一条命令报错了,但是后面的指令依旧正常执行成功了。
所以说Redis单条指令保证原子性,但是Redis事务不能保证原子性。
监控
悲观锁:
- 很悲观,认为什么时候都会出现问题,无论做什么都会加锁
乐观锁:
- 很乐观,认为什么时候都不会出现问题,所以不会上锁!更新数据的时候去判断一下,在此期间是否有人修改过这个数据
- 获取version
- 更新的时候比较version
使用watch key监控指定数据,相当于乐观锁加锁。
正常执行
127.0.0.1:6379> set money 100 # 设置余额:100
OK
127.0.0.1:6379> set use 0 # 支出使用:0
OK
127.0.0.1:6379> watch money # 监视money (上锁)
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY use 20
QUEUED
127.0.0.1:6379> exec # 监视值没有被中途修改,事务正常执行
1) (integer) 80
2) (integer) 20
测试多线程修改值,使用watch可以当做redis的乐观锁操作(相当于getversion)
我们启动另外一个客户端模拟插队线程。
线程1:
127.0.0.1:6379> watch money # money上锁
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY use 20
QUEUED
127.0.0.1:6379> # 此时事务并没有执行
模拟线程插队,线程2:
127.0.0.1:6379> INCRBY money 500 # 修改了线程一中监视的money
(integer) 600
回到线程1,执行事务:
127.0.0.1:6379> EXEC # 执行之前,另一个线程修改了我们的值,这个时候就会导致事务执行失败 (nil) # 没有结果,说明事务执行失败
127.0.0.1:6379> get money # 线程2 修改生效
"600"
127.0.0.1:6379> get use # 线程1事务执行失败,数值没有被修改
"0"
解锁获取最新值,然后再加锁进行事务。
unwatch进行解锁。
注意:每次提交执行exec后都会自动释放锁,不管是否成功
六、Jedis
使用Java来操作Redis,Jedis是Redis官方推荐使用的Java连接redis的客户端。
1.导入依赖
<!--导入jredis的包-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
2.编码测试
连接数据库
操作命令
断开连接
代码示例
public class TestPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.xx.xxx", 6379);
String response = jedis.ping();
System.out.println(response); // PONG
}
}
输出PONG
常用的API
string、list、set、hash、zset
所有的api命令,就是我们对应的上面学习的指令,一个都没有变化!
public class TestTX {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","kuangshen");
// 开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
// jedis.watch(result)
try {
multi.set("user1",result);
multi.set("user2",result);
int i = 1/0 ; // 代码抛出异常事务,执行失败!
multi.exec(); // 执行事务!
} catch (Exception e) {
multi.discard(); // 放弃事务
e.printStackTrace();
} finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close(); // 关闭连接
}
}
}
七、SpringBoot整合
SpringBoot 操作数据:spring-data jpa jdbc mongodb redis!
SpringData 也是和 SpringBoot 齐名的项目!
说明: 在 SpringBoot2.x 之后,原来使用的jedis 被替换为了 lettuce?
jedis : 采用的直连,多个线程操作的话,是不安全的,如果想要避免不安全的,使用 jedis pool 连接池! 更像 BIO 模式
lettuce : 采用netty,实例可以再多个线程中进行共享,不存在线程不安全的情况!可以减少线程数据了,更像 NIO 模式
源码分析:
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
// 我们可以自己定义一个redisTemplate来替换这个默认的!
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
// 默认的 RedisTemplate 没有过多的设置,redis 对象都是需要序列化!
// 两个泛型都是 Object, Object 的类型,我们后使用需要强制转换 <String, Object>
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean // 由于 String 是redis中最常使用的类型,所以说单独提出来了一个bean!
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
整合测试
1.导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
springboot 2.x后 ,原来使用的 Jedis 被 lettuce 替换。
jedis:采用的直连,多个线程操作的话,是不安全的。如果要避免不安全,使用jedis pool连接池!更像BIO模式
lettuce:采用netty,实例可以在多个线程中共享,不存在线程不安全的情况!可以减少线程数据了,更像NIO模式
我们在学习SpringBoot自动配置的原理时,整合一个组件并进行配置一定会有一个自动配置类xxxAutoConfiguration,并且在spring.factories中也一定能找到这个类的完全限定名。Redis也不例外。

那么就一定还存在一个RedisProperties类

@ConditionalOnClass注解中有两个类是默认不存在的,所以Jedis是无法生效的
然后再看Lettuce:

完美生效。
现在我们回到RedisAutoConfiguratio
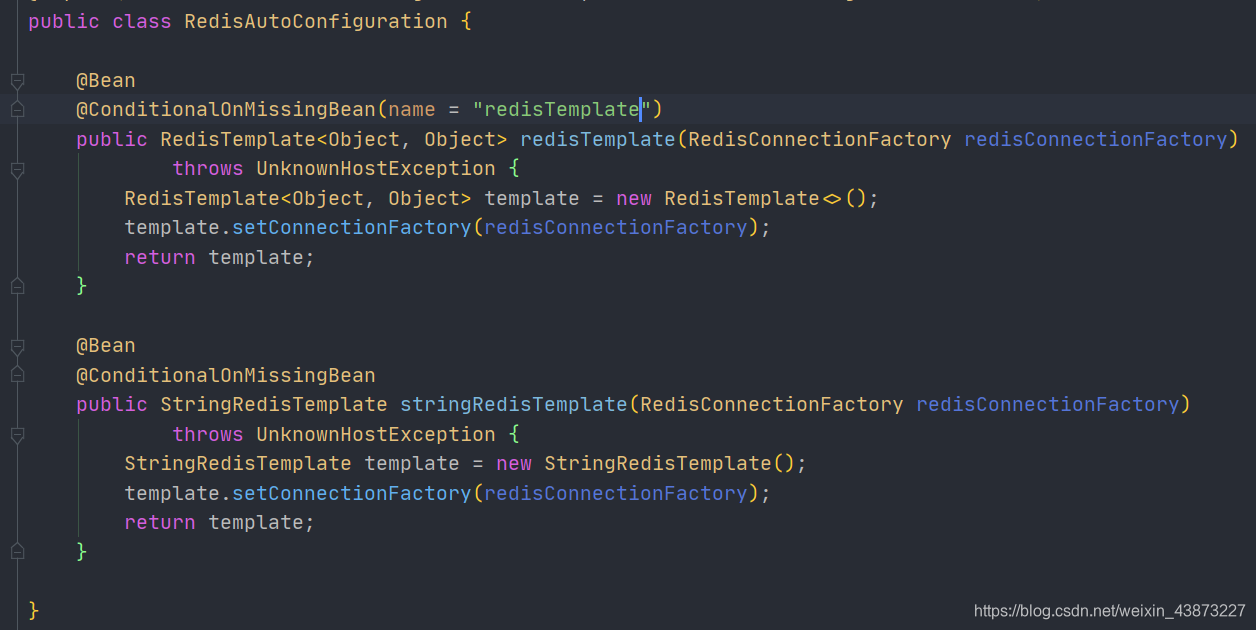
只有两个简单的Bean
- RedisTemplate
- StringRedisTemplate
当看到xxTemplate时可以对比RestTemplat、SqlSessionTemplate,通过使用这些Template来间接操作组件。那么这俩也不会例外。分别用于操作Redis和Redis中的String数据类型。
在RedisTemplate上也有一个条件注解,说明我们是可以对其进行定制化的
说完这些,我们需要知道如何编写配置文件然后连接Redis,就需要阅读RedisProperties

这是一些基本的配置属性。
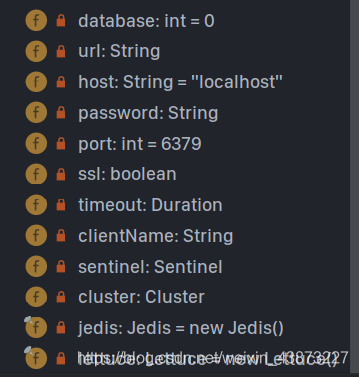
还有一些连接池相关的配置。注意使用时一定使用Lettuce的连接池。
2.编写配置文件
# 配置redis
spring.redis.host=39.99.xxx.xx
spring.redis.port=6379
3.使用RedisTemplate
@SpringBootTest class Redis02SpringbootApplicationTests {@Autowired private RedisTemplate redisTemplate; @Test void contextLoads() { // redisTemplate 操作不同的数据类型,api和我们的指令是一样的 // opsForValue 操作字符串 类似String // opsForList 操作List 类似List // opsForSet // opsForHash // opsForZSet // opsForGeo // opsForHyperLog // 除了基本的操作,我们常用的方法都可以直接通过redisTemplate操作,比如事务和基本的CRUD // 获取连接对象 //RedisConnection connection = redisTemplate.getConnectionFactory().getConnection(); //connection.flushDb(); //connection.flushAll(); redisTemplate.opsForValue().set("mykey","kuangshen"); System.out.println(redisTemplate.opsForValue().get("mykey")); }
}
4.测试结果
此时我们回到Redis查看数据时候,惊奇发现全是乱码,可是程序中可以正常输出。这时候就关系到存储对象的序列化问题,在网络中传输的对象也是一样需要序列化,否者就全是乱码。
RedisTemplate内部的序列化配置是这样的
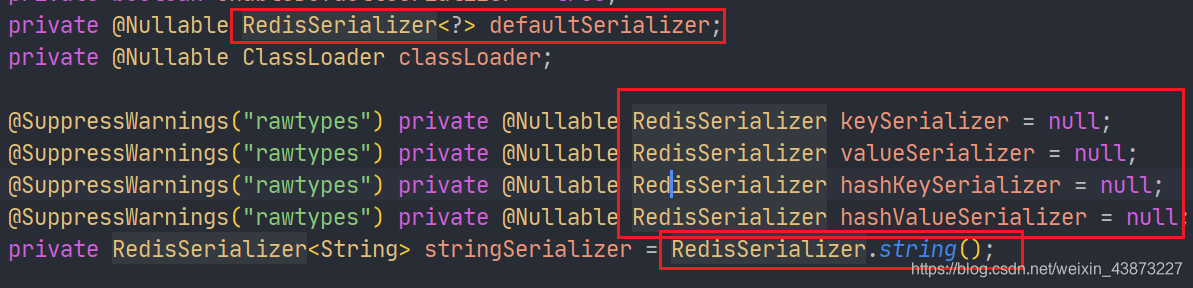
默认的序列化器是采用JDK序列化器
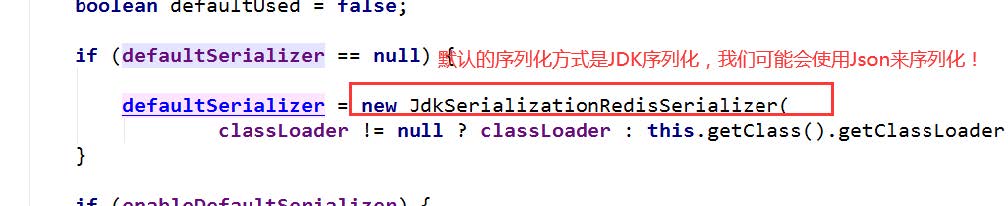
后续我们定制RedisTemplate就可以对其进行修改。
RedisSerializer提供了多种序列化方案:
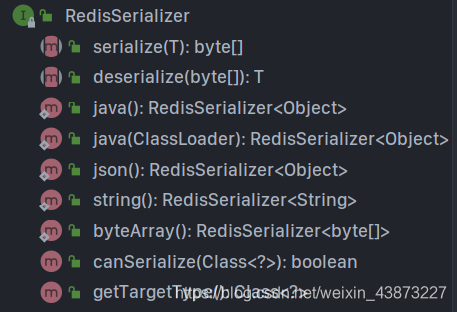
我们来编写一个自己的 RedisTemplete
import com.fasterxml.jackson.annotation.JsonAutoDetect; import com.fasterxml.jackson.annotation.PropertyAccessor; import com.fasterxml.jackson.databind.ObjectMapper; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.StringRedisSerializer; @Configuration public class RedisConfig { // 这是我给大家写好的一个固定模板,大家在企业中,拿去就可以直接使用! // 自己定义了一个 RedisTemplate @Bean @SuppressWarnings("all") public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { // 我们为了自己开发方便,一般直接使用 <String, Object> RedisTemplate<String, Object> template = new RedisTemplate<String, Object>(); template.setConnectionFactory(factory);// Json序列化配置 Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); // String 的序列化 StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // key采用String的序列化方式 template.setKeySerializer(stringRedisSerializer); // hash的key也采用String的序列化方式 template.setHashKeySerializer(stringRedisSerializer); // value序列化方式采用jackson template.setValueSerializer(jackson2JsonRedisSerializer); // hash的value序列化方式采用jackson template.setHashValueSerializer(jackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; }
}
所有的redis操作,其实对于java开发人员来说,十分的简单,更重要是要去理解redis的思想和每一种数据结构的用处和作用场景!