阅读目录
拾遗
集合
https://www.cnblogs.com/l-hf/p/11528953.html
在for循环中修改被循环的对象
文件处理
初窥文件操作基本流程
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量 #2. 通过句柄对文件进行操作 #3. 关闭文件


#1. 打开文件,得到文件句柄并赋值给一个变量 f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r#2. 通过句柄对文件进行操作
data=f.read()#3. 关闭文件
f.close()
#1、由应用程序向操作系统发起系统调用open(...) #2、操作系统打开该文件,并返回一个文件句柄给应用程序 #3、应用程序将文件句柄赋值给变量f
关闭文件的注意事项
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 1、f.close() #回收操作系统级打开的文件 2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close()虽然我这么说,但是很多同学还是会很不要脸地忘记f.close(),对于这些不长脑子的同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文
with open('a.txt','w') as f:
passwith open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data)
文件编码
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
#这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。 f=open('a.txt','r',encoding='utf-8')
文件的打开模式
文件句柄 = open('文件路径', '模式')
模式可以是以下方式以及他们之间的组合:
| Character | Meaning |
| ‘r' | open for reading (default) |
| ‘w' | open for writing, truncating the file first |
| ‘a' | open for writing, appending to the end of the file if it exists |
| ‘b' | binary mode |
| ‘t' | text mode (default) |
| ‘+' | open a disk file for updating (reading and writing) |
| ‘U' | universal newline mode (for backwards compatibility; should not be used in new code) |

#1. 打开文件的模式有(默认为文本模式): r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 w,只写模式【不可读;不存在则创建;存在则清空内容】 a, 之追加写模式【不可读;不存在则创建;存在则只追加内容】#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
#"+" 表示可以同时读写某个文件 r+, 读写【可读,可写】 w+,写读【可读,可写】 a+, 写读【可读,可写】 x, 只写模式【不可读;不存在则创建,存在则报错】 x+ ,写读【可读,可写】 xb
由于历史的原因,换行符在不同的系统中有不同模式,比如在 unix中是一个 ,而在windows中是‘ ’,用U模式打开文件,就是支持所有的换行模式,也就说‘ ’ ' ' ' '都可表示换行 t是windows平台特有的所谓text mode(文本模式),区别在于会自动识别windows平台的换行符。
Files opened in binary mode (appending 'b' to the mode argument) return contents as bytes objects without any decoding. b是以二进制的形式来读文件,但是显示出来的却不是0101,而是以字节的形式显示出来。 一个字节是8位二进制,所以计算机是自动帮你进行了转换。 请不要误会b模式是按照字节读。
文件内的光标移动
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
with上下文管理
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为:
1、f.close() #回收操作系统级打开的文件
2、del f #回收应用程序级的变量
其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源,
而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close()
虽然我这么说,但是很多同学还是会很不要脸地忘记f.close(),对于这些不长脑子的同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文
with open('a.txt','w') as f: passwith open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data)
文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import oswith open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
data=read_f.read() #全部读入内存,如果文件很大,会很卡
data=data.replace('alex','SB') #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import oswith open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
for line in read_f:
line=line.replace('alex','SB')
write_f.write(line)os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
练习
1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数,求出本次购物花费的总钱数
apple 10 3
tesla 100000 1
mac 3000 2
lenovo 30000 3
chicken 10 3
2. 修改文件内容,把文件中的alex都替换成SB
函数
为什么要用函数
现在python届发生了一个大事件,len方法突然不能直接用了。。。
然后现在有一个需求,让你计算'hello world'的长度,你怎么计算?
这个需求对于现在的你其实不难,我们一起来写一下。
s1 = "hello world" length = 0 for i in s1: length = length+1print(length)
好了,功能实现了,非常完美。然后现在又有了一个需求,要计算另外一个字符串的长度,"hello eva".
于是,这个时候你的代码就变成了这样:
s1 = "hello world" length = 0 for i in s1: length = length+1print(length)
s2 = "hello eva"
length = 0
for i in s2:
length = length+1print(length)
这样确实可以实现len方法的效果,但是总感觉不是那么完美?为什么呢?
首先,之前只要我们执行len方法就可以直接拿到一个字符串的长度了,现在为了实现相同的功能我们把相同的代码写了好多遍 —— 代码冗余
其次,之前我们只写两句话读起来也很简单,一看就知道这两句代码是在计算长度,但是刚刚的代码却不那么容易读懂 —— 可读性差
print(len(s1)) print(len(s2))
我们就想啊,要是我们能像使用len一样使用我们这一大段“计算长度”的代码就好了。这种感觉有点像给这段代码起了一个名字,等我们用到的时候直接喊名字就能执行这段代码似的。要是能这样,是不是很完美啊?
初识函数定义与调用
现在就教大家一个既能,让你们把代码装起来。
def mylen(): s1 = "hello world" length = 0 for i in s1: length = length+1 print(length)
我们一起来分析一下这段代码做了什么。
其实除了def这一行和后面的缩进,其他的好像就是正常的执行代码。我们来执行一下,哦,好像啥也没发生。
刚刚我们已经说过,这是把代码装起来的过程。你现在只会往里装,还不会往出拿。那么应该怎么往出拿呢?我来告诉大家:
mylen()
是不是很简单?是不是似曾相识?这就是代码取出来的过程。刚刚我们就写了一个函数,并且成功调用了它。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length)#函数调用
mylen()
总结一:
定义:def 关键词开头,空格之后接函数名称和圆括号(),最后还有一个":"。
def 是固定的,不能变,必须是连续的def三个字母,不能分开。。。它们要相亲相爱的在一起。
空格 为了将def关键字和函数名分开,必须空(四声),当然你可以空2格、3格或者你想空多少都行,但正常人还是空1格。
函数名:函数名只能包含字符串、下划线和数字且不能以数字开头。虽然函数名可以随便起,但我们给函数起名字还是要尽量简短,并能表达函数功能
括号:是必须加的,先别问为啥要有括号,总之加上括号就对了!
注释:每一个函数都应该对功能和参数进行相应的说明,应该写在函数下面第一行。以增强代码的可读性。
调用:就是 函数名() 要记得加上括号,好么好么好么。
函数的返回值
刚刚我们就写了一个函数,这个函数可以帮助我们计算字符串的长度,并且把结果打印出来。但是,这和我们的len方法还不是太一样。哪里不一样呢?以前我们调用len方法会得到一个值,我们必须用一个变量来接收这个值。
str_len = len('hello,world')
这个str_len就是‘hello,world’的长度。那我们自己写的函数能做到这一点么?我们也来试一下。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length)#函数调用
str_len = mylen()
print('str_len : %s'%str_len)
很遗憾,如果你执行这段代码,得到的str_len 值为None,这说明我们这段代码什么也没有给你返回。
那如何让它也想len函数一样返回值呢?
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 return length#函数调用
str_len = mylen()
print('str_len : %s'%str_len)
我们只需要在函数的最后加上一个return,return后面写上你要返回的值就可以了。
接下来,我们就来研究一下这个return的用法。
return关键字的作用
return 是一个关键字,在pycharm里,你会看到它变成蓝色了。你必须一字不差的把这个单词给背下来。
这个词翻译过来就是“返回”,所以我们管写在return后面的值叫“返回值”
要研究返回值,我们还要知道返回值有几种情况:分别是没有返回值、返回一个值、返回多个值
没有返回值
不写return的情况下,会默认返回一个None:我们写的第一个函数,就没有写return,这就是没有返回值的一种情况。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length)#函数调用
str_len = mylen()
#因为没有返回值,此时的str_len为None
print('str_len : %s'%str_len)
只写return,后面不写其他内容,也会返回None,有的同学会奇怪,既然没有要返回的值,完全可以不写return,为什么还要写个return呢?这里我们要说一下return的其他用法,就是一旦遇到return,结束整个函数。
def ret_demo(): print(111) return print(222)ret = ret_demo()
print(ret)
return None:和上面的两种情况一样,我们一般不这样写。
def ret_demo(): print(111) return None print(222)ret = ret_demo()
print(ret)
返回一个值
刚刚我们已经写过一个返回一个值的情况,只需在return后面写上要返回的内容即可。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 return length#函数调用
str_len = mylen()
print('str_len : %s'%str_len)
注意:return和返回值之间要有空格,可以返回任意数据类型的值
返回多个值
可以返回任意多个、任意数据类型的值
def ret_demo1(): '''返回多个值''' return 1,2,3,4def ret_demo2():
'''返回多个任意类型的值'''
return 1,['a','b'],3,4ret1 = ret_demo1()
print(ret1)
ret2 = ret_demo2()
print(ret2)
返回的多个值会被组织成元组被返回,也可以用多个值来接收
def ret_demo2(): return 1,['a','b'],3,4#返回多个值,用一个变量接收
ret2 = ret_demo2()
print(ret2)#返回多个值,用多个变量接收
a,b,c,d = ret_demo2()
print(a,b,c,d)#用多个值接收返回值:返回几个值,就用几个变量接收
a,b,c,d = ret_demo2()
print(a,b,c,d)
原因:
>>> 1,2 #python中把用逗号分割的多个值就认为是一个元组。 (1, 2) >>> 1,2,3,4 (1, 2, 3, 4) >>> (1,2,3,4) (1, 2, 3, 4)
#序列解压一 >>> a,b,c,d = (1,2,3,4) >>> a 1 >>> b 2 >>> c 3 >>> d 4 #序列解压二 >>> a,_,_,d=(1,2,3,4) >>> a 1 >>> d 4 >>> a,*_=(1,2,3,4) >>> *_,d=(1,2,3,4) >>> a 1 >>> d 4 #也适用于字符串、列表、字典、集合 >>> a,b = {'name':'eva','age':18} >>> a 'name' >>> b 'age'
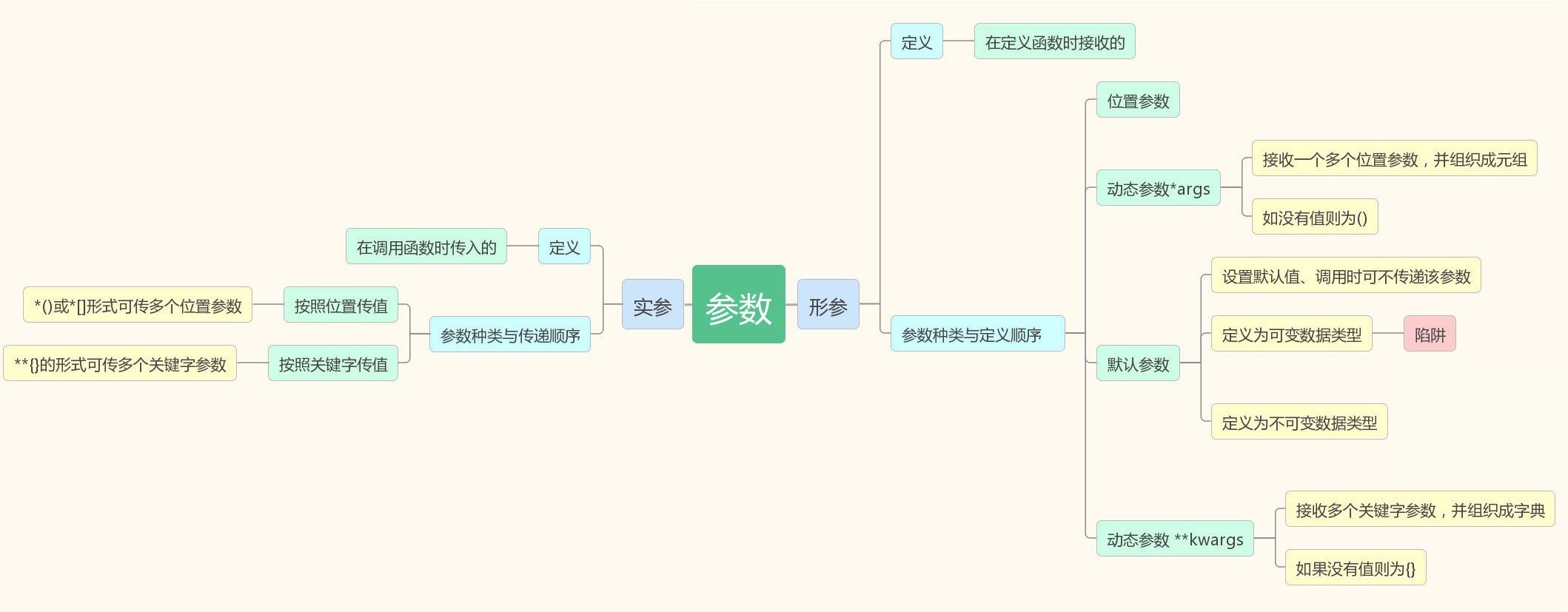
函数的参数
现在,我们已经把函数返回值相关的事情研究清楚了,我们自己已经完成了一个可以返回字符串长度的函数。但是现在这个函数还是不完美,之前我们使用len函数的时候得是length = len("hello world"),这样我可以想计算谁就计算谁的长度。但是现在我们写的这个函数,只能计算一个“hello world”的长度,换一个字符串好像就是不行了。这可怎么办?
#函数定义 def mylen(s1): """计算s1的长度""" length = 0 for i in s1: length = length+1 return length#函数调用
str_len = mylen("hello world")
print('str_len : %s'%str_len)
我们告诉mylen函数要计算的字符串是谁,这个过程就叫做 传递参数,简称传参,我们调用函数时传递的这个“hello world”和定义函数时的s1就是参数。
实参与形参
参数还有分别:
我们调用函数时传递的这个“hello world”被称为实际参数,因为这个是实际的要交给函数的内容,简称实参。
定义函数时的s1,只是一个变量的名字,被称为形式参数,因为在定义函数的时候它只是一个形式,表示这里有一个参数,简称形参。
传递多个参数
参数可以传递多个,多个参数之间用逗号分割。
def mymax(x,y): the_max = x if x > y else y return the_maxma = mymax(10,20)
print(ma)
也正是因为需要传递多个参数、可以传递多个参数,才会有了后面这一系列参数相关的故事。。。
位置参数
站在实参角度
1.按照位置传值
def mymax(x,y): #此时x=10,y=20 the_max = x if x > y else y return the_maxma = mymax(10,20)
print(ma)
2.按照关键字传值
def mymax(x,y): #此时x = 20,y = 10 print(x,y) the_max = x if x > y else y return the_maxma = mymax(y = 10,x = 20)
print(ma)
3.位置、关键字形式混着用
def mymax(x,y): #此时x = 10,y = 20 print(x,y) the_max = x if x > y else y return the_maxma = mymax(10,y = 20)
print(ma)
正确用法
问题一:位置参数必须在关键字参数的前面
问题二:对于一个形参只能赋值一次
站在形参角度
位置参数必须传值
def mymax(x,y): #此时x = 10,y = 20 print(x,y) the_max = x if x > y else y return the_max#调用mymax不传递参数
ma = mymax()
print(ma)#结果
TypeError: mymax() missing 2 required positional arguments: 'x' and 'y'
默认参数
1.正常使用
使用方法
为什么要有默认参数:将变化比较小的值设置成默认参数
2.默认参数的定义
def stu_info(name,sex = "male"): """打印学生信息函数,由于班中大部分学生都是男生, 所以设置默认参数sex的默认值为'male' """ print(name,sex)stu_info('alex')
stu_info('eva','female')
3.参数陷阱:默认参数是一个可变数据类型
def defult_param(a,l = []): l.append(a) print(l)defult_param('alex')
defult_param('egon')
动态参数
按位置传值多余的参数都由args统一接收,保存成一个元组的形式
def mysum(*args): the_sum = 0 for i in args: the_sum+=i return the_sumthe_sum = mysum(1,2,3,4)
print(the_sum)
def stu_info(**kwargs): print(kwargs) print(kwargs['name'],kwargs['sex'])stu_info(name = 'alex',sex = 'male')
实际开发中:
未来还会用到的场景。。。
问题:
位置参数、默认参数、动态参数定义的顺序以及接收的结果?
参数总结:
命名空间和作用域
命名空间的本质:存放名字与值的绑定关系
>>> import this The Zen of Python, by Tim PetersBeautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than right now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
在python之禅中提到过:命名空间是一种绝妙的理念,让我们尽情的使用发挥吧!
命名空间一共分为三种:
全局命名空间
局部命名空间
内置命名空间
*内置命名空间中存放了python解释器为我们提供的名字:input,print,str,list,tuple...它们都是我们熟悉的,拿过来就可以用的方法。
三种命名空间之间的加载与取值顺序:
加载顺序:内置命名空间(程序运行前加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)
取值:
在局部调用:局部命名空间->全局命名空间->内置命名空间
x = 1 def f(x): print(x)print(10)
在全局调用:全局命名空间->内置命名空间
x = 1 def f(x): print(x)f(10)
print(x)
print(max)
作用域
作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
局部作用域:局部名称空间,只能在局部范围内生效
globals和locals方法
print(globals()) print(locals())
def func(): a = 12 b = 20 print(locals()) print(globals())func()
global关键字
a = 10 def func(): global a a = 20print(a)
func()
print(a)
函数的嵌套和作用域链
函数的嵌套调用
def max2(x,y): m = x if x>y else y return mdef max4(a,b,c,d):
res1 = max2(a,b)
res2 = max2(res1,c)
res3 = max2(res2,d)
return res3# max4(23,-7,31,11)
函数的嵌套定义
def f1(): print("in f1") def f2(): print("in f2")f2()f1()
def f1(): def f2(): def f3(): print("in f3") print("in f2") f3() print("in f1") f2()f1()
函数的作用域链
def f1(): a = 1 def f2(): print(a) f2()f1()
def f1(): a = 1 def f2(): def f3(): print(a) f3() f2()f1()
def f1(): a = 1 def f2(): a = 2 f2() print('a in f1 : ',a)f1()
nonlocal关键字
# 1.外部必须有这个变量
# 2.在内部函数声明nonlocal变量之前不能再出现同名变量
# 3.内部修改这个变量如果想在外部有这个变量的第一层函数中生效
def f1(): a = 1 def f2(): nonlocal a a = 2 f2() print('a in f1 : ',a)f1()
函数小结
面向过程编程的问题:代码冗余、可读性差、可扩展性差(不易修改)
定义函数的规则:
1.定义:def 关键词开头,空格之后接函数名称和圆括号()。
2.参数:圆括号用来接收参数。若传入多个参数,参数之间用逗号分割。
参数可以定义多个,也可以不定义。
参数有很多种,如果涉及到多种参数的定义,应始终遵循位置参数、*args、默认参数、**kwargs顺序定义。
如上述定义过程中某参数类型缺省,其他参数依旧遵循上述排序
3.注释:函数的第一行语句应该添加注释。
4.函数体:函数内容以冒号起始,并且缩进。
5.返回值:return [表达式] 结束函数。不带表达式的return相当于返回 None
def 函数名(参数1,参数2,*args,默认参数,**kwargs):
"""注释:函数功能和参数说明"""
函数体
……
return 返回值
调用函数的规则:
1.函数名()
函数名后面+圆括号就是函数的调用。
2.参数:
圆括号用来接收参数。
若传入多个参数:
应按先位置传值,再按关键字传值
具体的传入顺序应按照函数定义的参数情况而定
3.返回值
如果函数有返回值,还应该定义“变量”接收返回值
如果返回值有多个,也可以用多个变量来接收,变量数应和返回值数目一致
无返回值的情况:
函数名()
有返回值的情况:
变量 = 函数名()
多个变量接收多返回值:
变量1,变量2,... = 函数名()
命名空间:
一共有三种命名空间从大范围到小范围的顺序:内置命名空间、全局命名空间、局部命名空间
作用域(包括函数的作用域链):
小范围的可以用大范围的
但是大范围的不能用小范围的
范围从大到小(图)
练习题
1、任一个英文的纯文本文件,统计其中的每个单词出现的个数,注意是每个单词。。
2、写函数,计算传入数字参数的和。(动态传参)
3、写函数,用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的批量修改操作
4、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。
5、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容(对value的值进行截断),并将新内容返回给调用者,注意传入的数据可以是字符、list、dict
6、写函数,返回一个扑克牌列表,里面有52项,每一项是一个元组
例如:[(‘红心’,2),(‘草花’,2), …(‘黑桃A’)]
7、写函数,传入n个数,返回字典{‘max’:最大值,’min’:最小值}
例如:minmax(2,5,7,8,4)
返回:{‘max’:8,’min’:2}
8、写函数,专门计算图形的面积
- 其中嵌套函数,计算圆的面积,正方形的面积和长方形的面积
- 调用函数area(‘圆形’,圆半径) 返回圆的面积
- 调用函数area(‘正方形’,边长) 返回正方形的面积
- 调用函数area(‘长方形’,长,宽) 返回长方形的面积
#代码模板 def area(): def 计算长方形面积(): passdef 计算正方形面积():
passdef 计算圆形面积():
pass
9、写函数,传入一个参数n,返回n的阶乘
例如:cal(7)
返回计算7*6*5*4*3*2*1的结果
10、如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
portfolio = [ {‘name’: ‘IBM’, ‘shares’: 100, ‘price’: 91.1}, {‘name’: ‘AAPL’, ‘shares’: 50, ‘price’: 543.22}, {‘name’: ‘FB’, ‘shares’: 200, ‘price’: 21.09}, {‘name’: ‘HPQ’, ‘shares’: 35, ‘price’: 31.75}, {‘name’: ‘YHOO’, ‘shares’: 45, ‘price’: 16.35}, {‘name’: ‘ACME’, ‘shares’: 75, ‘price’: 115.65} ]
- 通过哪个内置函数可以计算购买每支股票的总价
- 用filter过滤出,单价大于100的股票有哪些
11、有列表 li = [‘alex’, ‘egon’, ‘smith’, ‘pizza’, ‘alen’], 请将以字母“a”开头的元素的首字母改为大写字母;
12、有列表 li = [‘alex’, ‘egon’, ‘smith’, ‘pizza’, ‘alen’], 请以列表中每个元素的第二个字母倒序排序;
13、有名为poetry.txt的文件,其内容如下,请删除第三行;
昔人已乘黄鹤去,此地空余黄鹤楼。
黄鹤一去不复返,白云千载空悠悠。
晴川历历汉阳树,芳草萋萋鹦鹉洲。
日暮乡关何处是?烟波江上使人愁。
14、有名为username.txt的文件,其内容格式如下,写一个程序,判断该文件中是否存在”alex”, 如果没有,则将字符串”alex”添加到该文件末尾,否则提示用户该用户已存在;
pizza
alex
egon
15、有名为user_info.txt的文件,其内容格式如下,写一个程序,删除id为100003的行;
pizza,100001 alex, 100002 egon, 100003
16、有名为user_info.txt的文件,其内容格式如下,写一个程序,将id为100002的用户名修改为alex li;
pizza,100001 alex, 100002 egon, 100003
作业
1.股票查询程序开发
把以下股票数据存入stock_data.txt

数据来源:东方财富网
开发程序对stock_data.txt进行以下操作:
1.程序启动后,给用户提供查询接口,允许用户重复查股票行情信息(用到循环)
2.允许用户通过模糊查询股票名,比如输入“啤酒”, 就把所有股票名称中包含“啤酒”的信息打印出来
3.允许按股票价格、涨跌幅、换手率这几列来筛选信息,比如输入“价格>50”则把价格大于50的股票都打印,输入“市盈率<50“,则把市盈率小于50的股票都打印,不用判断等于。
思路提示:加载文件内容到内存,转成dict or list结构,然后对dict or list 进行查询等操作。 这样以后就不用每查一次就要打开一次文件了,效率会高。
程序启动后执行效果参考:
1 股票查询接口>>:换手率>25
2 ['序号', '代码', '名称', '最新价', '涨跌幅', '涨跌额', '成交量(手)', '成交额', '振幅', '最高', '最低', '今开', '昨收', '量比', '换手率', '市盈率', '市净率']
3 ['18', '603697', '有友食品', '22.73', '10.02%', '2.07', '34.93万', '7.68亿', '8.23%', '22.73', '21.03', '21.17', '20.66', '1.4', '43.94%', '38.1', '4.66']
4 ['23', '603956', '威派格', '22.52', '10.01%', '2.05', '18.33万', '4.01亿', '10.60%', '22.52', '20.35', '20.35', '20.47', '2.16', '43.02%', '-', '9.82']
5 ['36', '300748', '金力永磁', '59.7', '10.01%', '5.43', '11.02万', '6.38亿', '6.98%', '59.7', '55.91', '56.88', '54.27', '0.9', '26.49%', '234.09', '23.54']
6 ['37', '300767', '震安科技', '41.13', '10.00%', '3.74', '6.22万', '2.49亿', '10.32%', '41.13', '37.27', '37.48', '37.39', '3.86', '31.11%', '43.32', '3.68']
7 ['38', '603045', '福达合金', '32', '10.00%', '2.91', '17.06万', '5.31亿', '9.87%', '32', '29.13', '29.13', '29.09', '1.39', '25.17%', '52.74', '4.02']
8 ['39', '2952', '亚世光电', '58.98', '10.00%', '5.36', '4.18万', '2.41亿', '7.42%', '58.98', '55', '55.91', '53.62', '3.04', '27.44%', '53.09', '5.51']
9 找到6条
10 股票查询接口>>:最新价<5
11 ['序号', '代码', '名称', '最新价', '涨跌幅', '涨跌额', '成交量(手)', '成交额', '振幅', '最高', '最低', '今开', '昨收', '量比', '换手率', '市盈率', '市净率']
12 ['2', '2676', '顺威股份', '3.69', '10.15%', '0.34', '15.23万', '5516万', '9.55%', '3.69', '3.37', '3.37', '3.35', '1.16', '2.11%', '-', '2.58']
13 ['3', '601619', '嘉泽新能', '4.91', '10.09%', '0.45', '16.55万', '8006万', '8.52%', '4.91', '4.53', '4.54', '4.46', '1.82', '3.28%', '52.26', '3.64']
14 找到2条
15 股票查询接口>>:食品
16 ['18', '603697', '有友食品', '22.73', '10.02%', '2.07', '34.93万', '7.68亿', '8.23%', '22.73', '21.03', '21.17', '20.66', '1.4', '43.94%', '38.1', '4.66']
17 找到1条
18 股票查询接口>>:能源
19 ['9', '2828', '贝肯能源', '14.25', '10.04%', '1.3', '17.83万', '2.52亿', '4.71%', '14.25', '13.64', '13.8', '12.95', '3.45', '18.03%', '-', '3.08']
20 找到1条
21 股票查询接口>>:科技
22 ['12', '2866', '传艺科技', '13.81', '10.04%', '1.26', '13.59万', '1.83亿', '9.72%', '13.81', '12.59', '12.61', '12.55', '2.63', '16.86%', '33.37', '3.43']
23 ['19', '300777', '中简科技', '24.92', '10.02%', '2.27', '5952', '1483万', '0.00%', '24.92', '24.92', '24.92', '22.65', '3.45', '1.49%', '102.24', '11.49']
24 ['21', '300245', '天玑科技', '11.53', '10.02%', '1.05', '26.86万', '3.05亿', '9.64%', '11.53', '10.52', '10.52', '10.48', '1.06', '10.35%', '127.47', '2.57']
25 ['26', '300391', '康跃科技', '7.8', '10.01%', '0.71', '3.9万', '3027万', '10.01%', '7.8', '7.09', '7.09', '7.09', '0.75', '1.94%', '27.35', '1.89']
26 ['37', '300767', '震安科技', '41.13', '10.00%', '3.74', '6.22万', '2.49亿', '10.32%', '41.13', '37.27', '37.48', '37.39', '3.86', '31.11%', '43.32', '3.68']
27 ['40', '603327', '福蓉科技', '21.56', '10.00%', '1.96', '3586', '773.1万', '0.00%', '21.56', '21.56', '21.56', '19.6', '2.81', '0.70%', '31.97', '8.05']
28 找到6条
2.递归二分查找
请https://www.cnblogs.com/l-hf/p/11528959.html根据博客学习二分查找算法。
并自己找一个递归相关的练习题进行练习,上交题目和代码。