import requests
import re
from fake_useragent import UserAgent
ua = UserAgent()
kv = {'user-agent': ua.random}
url = 'https://movie.douban.com/top250?start=0&filter='
index = 0
for i in range(0, 10):
sum_page = i*25
new_url = re.sub('start=d+', 'start=%d'%sum_page, url, re.S)
r = requests.get(new_url, headers=kv)
r.encoding = 'utf-8'
text = r.text
pictures_part = re.findall('<div class="pic">(.*?)</div>', text, re.S)
for picture in pictures_part:
img = re.findall('src="(.*?)" class', picture, re.S)
pic = requests.get(img[0], headers=kv)
fp = open('imgs\' + str(index) + '.jpg', 'wb')
fp.write(pic.content)
fp.close()
print('picture' + str(index) + ' has been dawnload')
index += 1
代码部分的解释
- 需要对爬虫的请求头部加以修改,引入fake_useragent库来进行轻微的伪造
- 利用了index在标记爬取图片数量的同时方便为爬取的图片命名
- 关于re库中的sub翻页,利用sub方法进行分页爬取
- 图片保存要以二进制形式写入
- 需要提前在和代码同目录下创建imgs文件夹
- 爬取时不无聊加了这个东西
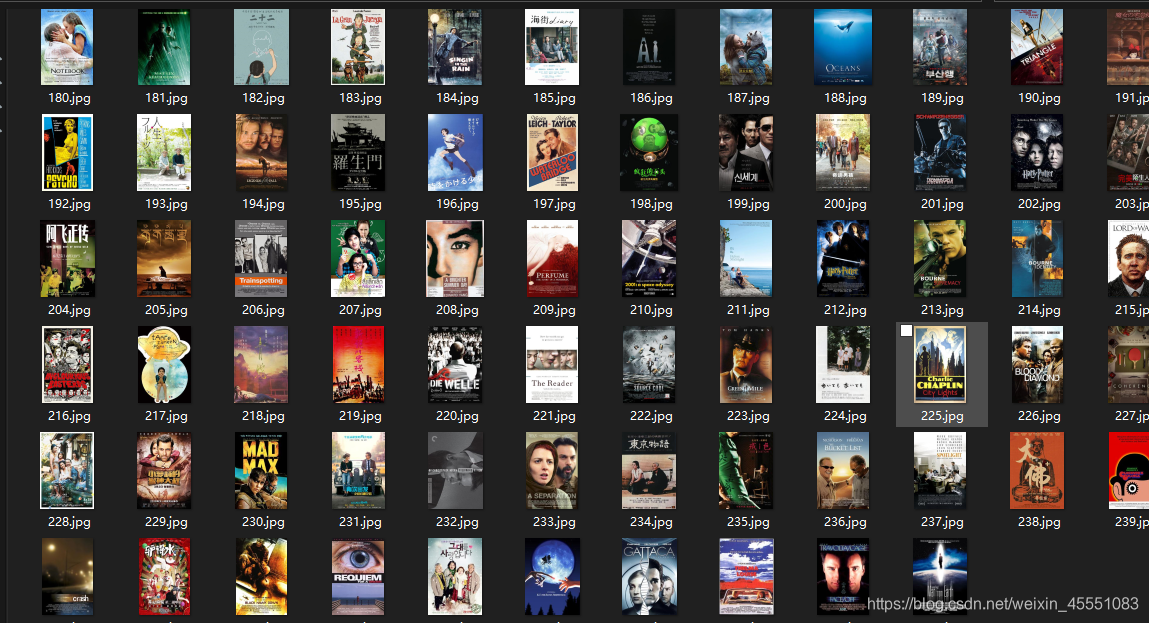
- 爬取的图片