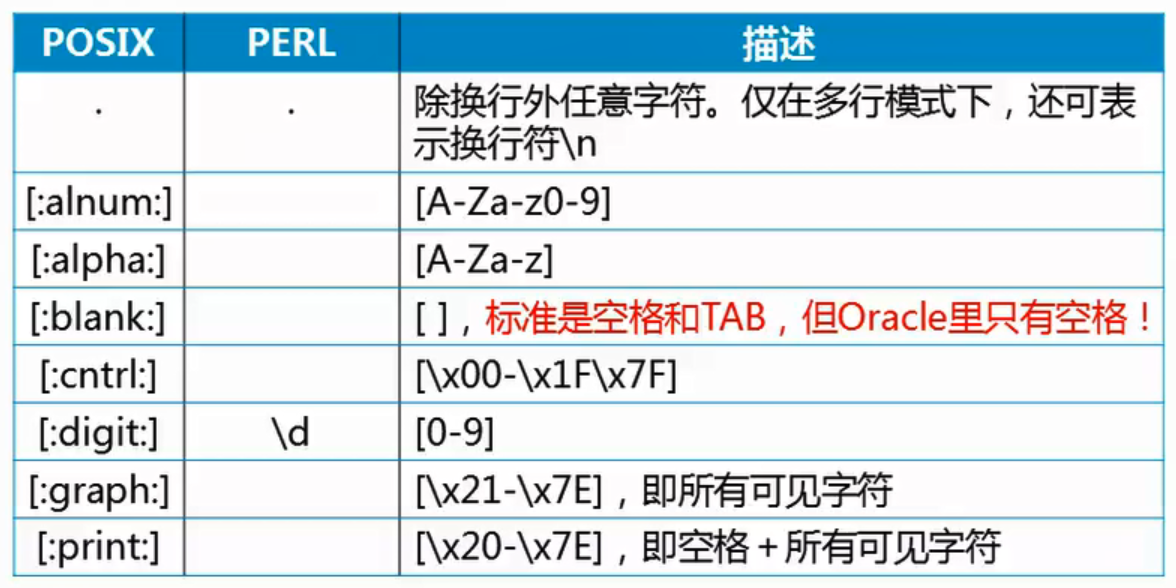
字符集合


边界符集合

重复次数集合

select regexp_substr('aaaabbccc','(aa|a){2}') from dual;
组合操作符


匹配操作符

regexp函数


select regexp_instr('aaaabbaccca123addd','a[^a]+',1,1,0) from dual; select regexp_substr('aaaabbaccca123addd','a[^a]+',1,1) from dual; select regexp_instr('aaaabbaccca123addd','a[^a]+',1,1,1) from dual; select regexp_instr('aaaabbaccca123addd','a[^a]+',1,2,0) from dual; select regexp_instr('aaaabbaccca123addd','a[^a]+',1,2,1) from dual;

select * from ascii_table where regexp_like(s,'[[:digit:]]'); select * from ascii_table where regexp_like(s,'[[:lower:]]'); select * from ascii_table where regexp_like(s,'[[:upper:]]'); select * from ascii_table where regexp_like(s,'[[:blank:]]'); select * from ascii_table where regexp_like(s,'[[:space:]]'); select * from ascii_table where regexp_like(s,'[[:punct:]]'); select * from ascii_table where regexp_like(s,'[[:cntrl:]]'); select * from ascii_table where n=7; select * from ascii_table where regexp_like(s,'D'); select * from ascii_table where regexp_like(s,'[^[:digit:]]');y
应用



格式化
将IPV4的地址每段都格式化为三位数的,不够的前面补0
create table ip (str varchar2(20) ); select * from ip; insert into ip values('30.0.0.1'); insert into ip values('130.10.202.11'); insert into ip values('8.8.8.8'); commit; select str, replace(str,'.','..'), '.'||replace(str,'.','..')||'.', regexp_replace('.'||replace(str,'.','..')||'.','.(d).','.001.') regexp_replace1, regexp_replace(regexp_replace('.'||replace(str,'.','..')||'.','.(d).','.001.'),'.(dd).','.01.') regexp_replace2, trim('.' from regexp_replace(regexp_replace('.'||replace(str,'.','..')||'.','.(d).','.001.'),'.(dd).','.01.')) trim1, replace(trim('.' from regexp_replace(regexp_replace('.'||replace(str,'.','..')||'.','.(d).','.001.'),'.(dd).','.01.')),'..','.') replace2 from ip;

将字符串str逐字符重复4次,例如abc变为aaaabbbbcccc
select regexp_replace('abc','(.)','1111') from dual;
剔除str中除了逗号和数字之外的字符
select regexp_replace('1a,2b3c','[^[:digit:],]') from dual;
提取
从str中提取第一个单词(只有字母组成的才算单词)
select regexp_substr('2 1s as2 sa5 as dsa','([[:alpha:]]+)') from dual; select regexp_substr('2 1s as2 sa5 as dsa','([[:lower:]]+)',1,1,'i') from dual;
将可能是日期的字符串提取出来(yyyy-mm-dd格式)
select regexp_substr('12 s sa s 1111-2222-33-44-5555-66-77','d{4}-d{2}-d{2}') from dual;
网页源文件的片段已存入str中,从中提取出第一个标签
select regexp_substr('sdaa <body> sada <head>','<[^>]+>') from dual; select regexp_substr('sdaa <body> sada <head>','<.+?>') from dual;
select regexp_substr('哈哈嘿嘿哦俸','俸',1,1) from dual;