Author
Charles R. Qi* Hao Su* @ Stanford 第一个是PHD, 第二个是Professor, 两人一直在一起做些3D的研究 还有个PointNet++
Abstract
点云是一种很重要的几何数据结构,因为它不规则的形式,很多研究都是将它转换成规则的3D体素或者collections,这样的话就会造成大量不必要的数据也会产生一些相应的问题。
点云最接近原始传感数据,它是坐标的,所以它可以轻易地转换成其他三种数据格式(mesh,体素,深度图),也可以由其他格式轻易地转成点云
本文设计了一种新型的网络结构直接作用于点云数据上,并且很好的利用了点云数据的随机排列不变性。PointNet是一个统一的框架可以适用于目标分类,part segmentation, scene semantic parsing.
它的性能比肩于甚至好于当前最好的结果,这个网络对于输入扰动和损坏具有很强的健壮性。
Introduction
传统的卷积结构需要高度规则的数据输入格式,为了进行共享权重和其他kernel optimizations.
将不规则数据转换成规则数据会引入一些不必要的数据,同时可能损失数据本身的一些内在不变性
点云比起meshes网格,避免了组合的不规则性以及复杂性,所以更加学习起来更加简便
点云本质上就是一个集合,所以随机排列都不变,这样就迫使网络计算过程中的对称性,同时还要考虑刚体运动的不变性
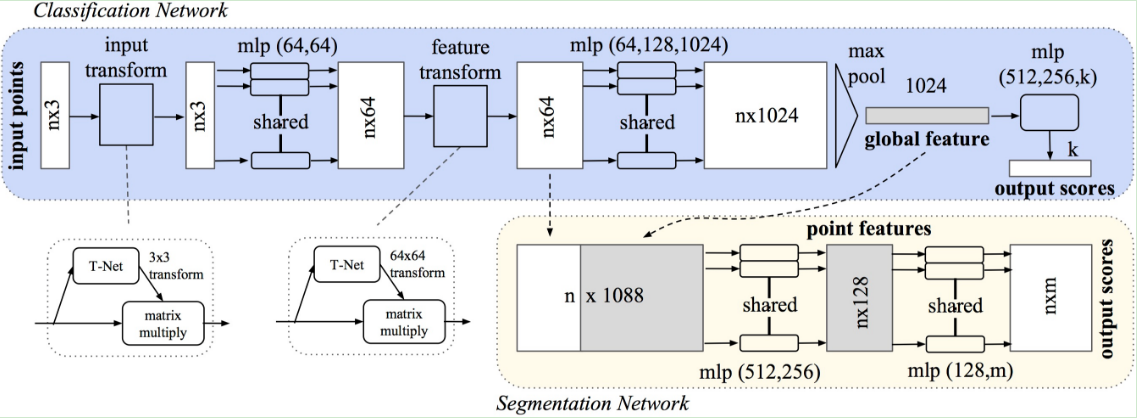
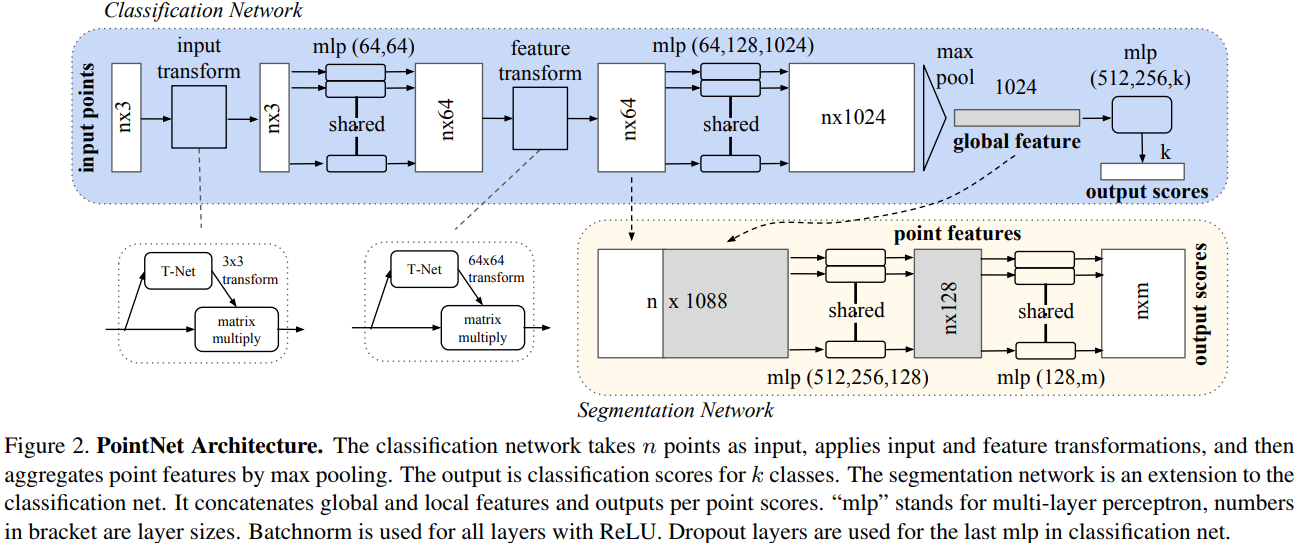
网络基本机构相当简单在初始阶段,对于每个点都是相同且独立的操作,每个点都是一个三维坐标(x,y,z), 另外的维度会通过计算一些通用或者局部全局的特征被加上
Key to our approach is the use of a single symmetric function, max pooling
网络学习了一系列优化函数/标准用以选择有趣或者富含信息的点同时enocde选择的原因
最终的一个全连接层将集合这些学习到的最优的值到全局的描述子用于整个形状(classification),或者用于预测每个点的标签(segmentation)
我们的数据格式易于使用刚体和放射变换,因为每个点的变换都是独立操作的。
因此我们在PointNet之前增加一个依赖数据的空间转换网络用来规范化数据
我们做了理论分析,也做了实验验证。理论上证明我们的网络可以拟合任意连续的函数。
有趣的是,我们的网络是在学习如何用一个关键点集合代表整个输入点云,可视化发现找到的是目标的一个skeleton
理论分析提供了一个分析为什么pointNet对输入点小扰动以及对outliers和missing data的鲁棒性
对网络的设计来源于两个挑战:
1. 设计网络可以适用于无序输入,数据输入的顺序对网络结果无影响

- 所以需要一个对称函数,不care输入数据的顺序, 比如说max, sum
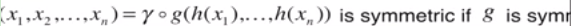

-
h is point embedding
- 任何连续的对称函数可以由pointNet近似
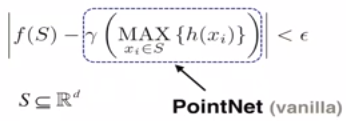
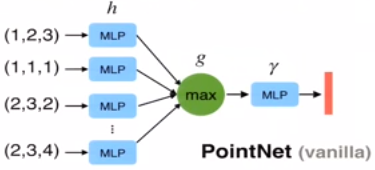
实验证明max pooling, 比average pooling以及weighted average pooling效果都更好
2. 使网络对于输入的几何变换更加robust
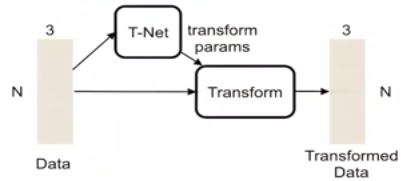
- 实现方法就是将点云与canonical space对齐
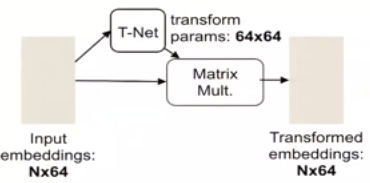
- mini PointNet: T-Net
Contribution
- 设计一个新型网络结构用于在3D中处理无序的点集
- 理论和实验分析了网络的stability and efficiency
- 提取的3D特征可以有很好的直观解释
Related Work
现在几乎很少有做点云feature learning的,现存的都是手工设计用于具体任务的
而且没有直接在点云上做深度学习的,如果要做深度,都是将点云事先转换成其他的表示方法(voxelization-3D CNN, Projection/Rendering-2D CNN, Feature extraction- Fullly Connected),再用现有的深度结构
最先开始的是在体素上的3D CNN, 限制在于:数据稀疏度导致分辨率低,计算3D卷积的cost
Multiview CNNs: render 3D Point cloud or shapes into 2D images then apply 2D conv nets (因为2D conv nets的高性能,这种方法在分类和检索任务中处于领先地位,但是在场景理解,point分类以及shape补全中不是很好)
Spectral CNNs: 最新的工作用在mesh上的,对于non-isometric物体不友好
Feature-based DNNs: 将3D data转换到vector,通过提取传统shape features然后利用全卷积网络进行分类,局限于representation power of the features extracted.
点云是个无序集合,
Problem Statement
Deep Learning on Point Sets
Properties of Point sets:
- Unordered
- Interaction among points
- 点都不是孤立的,模型需要capture local structures from nearby points and the combinatorial interactions among local structures
- Invariance under transformations
- 旋转,平移
Joint Alignment Network
因为希望预测的标签对点云的刚体变换保持不变,所以我们希望我们学习到的点的特征表示能够对这些变换无关
一个自然的解决方法是align all input set to a canonical space before feature extraction(比如说全部平移到坐标系中点)
We predict an affine transformation matrix by a mini-network: T-Net, and directly apply this transformation to the coordinates of input points.
T-Net类似于大网络,它由基础模块组成: 点独立的feature extraction, max pooling and fully connected layers.
同时可以用于alignment of feature space, 这个要比之前的alignment,也就是spatial transform matrix大很多,一个是64x64,一个是3x3, 所以提高了优化的难度。
因此我们在softmax training loss中增加了一个正则化项,我们约束这个feature transformation matrix尽可能近似于正交矩阵

正交变换不会丢失输入的信息,我们发现加上了这个正则项后我们的网络更加stable而且能够得到更好的结果
Theoretical Analysis
略,其实是看不懂
Result
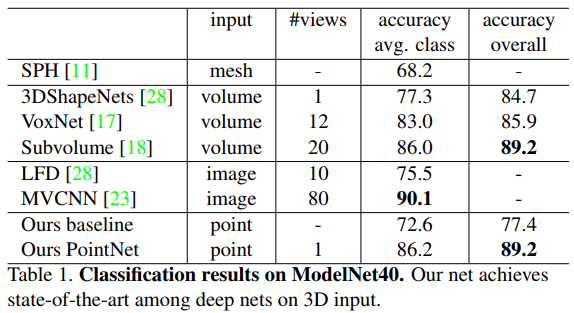
MVCNN[23] 效果比pointnet好,是因为due to the loss of fine geometry details that can be captured by rendered images.
数据集: ModelNet40
12311 CAD models 40类, 9843 training 2468 testing
在每个object上均匀sample 1024个点作为点云数据,augment数据(绕up-axis随机旋转,每个position加高斯噪声(0,0.02))

数据集: ShapeNet part data set
16881 16个类, 总共50个part 每个类有2-5个part
mIoU, 计算IoU(交集除以并集) between groudtruth and prediction,
对类比C的所有part计算IoU,然后做平均
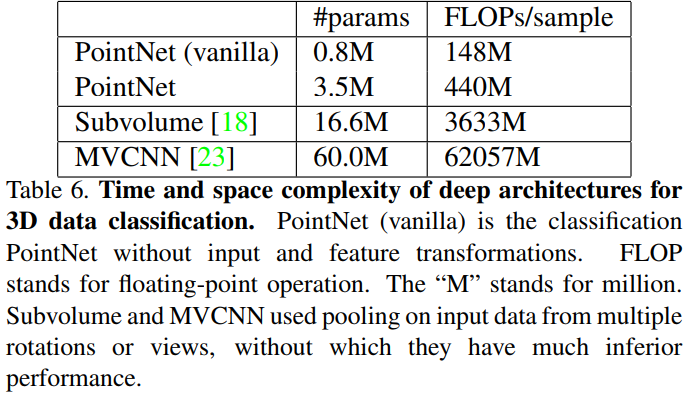
vanilla就是没有加上变换
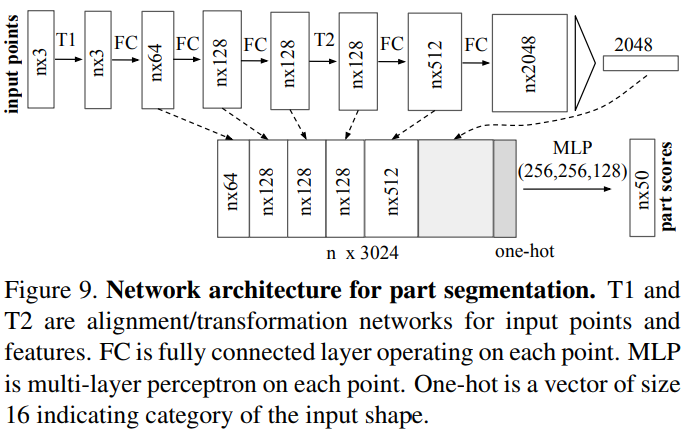
参考:https://www.leiphone.com/news/201708/ehaRP2W7JpF1jG0P.html
作者问答
Q:输入的原始三维点云数据需要做归一化吗?
A:和其他网络的输入一样,输入点云数据需要做零均值的归一化,这样才能保证比较好的实验性能。
Q:深层神经网络处理三维离散点云的难点在哪里?PointNet是如何解决这些难点的?
A:深度神经网络处理三维离散点云数据的难点主要在于点云的无序性和输入维度变化。在本篇文章中,我使用了深度神经网络中的常用对称函数 :Max Pooling 来解决无序性问题,使用共享网络参数的方式来处理输入维度的变化,取得了比较好的效果。
Q:是否可以使用RNN/LSTM来处理三维点云数据?
A:RNN/LSTM可以处理序列数据,可以是时间序列也可以是空间序列。因此从输入输出的角度来讲,他们可以用来处理三维点云数据。但是点云数据是无序的,这种点和点之间的先后输入顺序并没有规律,因此直接使用RNN/LSTM效果不会太好。
Q:T-Net在网络结构中起的本质作用是什么?需要预训练吗?
A:T-Net 是一个预测特征空间变换矩阵的子网络,它从输入数据中学习出与特征空间维度一致的变换矩阵,然后用这个变换矩阵与原始数据向乘,实现对输入特征空间的变换操作,使得后续的每一个点都与输入数据中的每一个点都有关系。通过这样的数据融合,实现对原始点云数据包含特征的逐级抽象。
Q:PointNet 与 MVCNN 的实验结果比较中,有些指标稍差,背后的原因是什么?
A:PointNet提取的是每一个独立的点的特征描述以及全局点云特征的描述,并没有考虑到点的局部特征和结构约束,因此与MVCNN相比,在局部特征描述方面能力稍弱。面对这样的问题,我们基于PointNet已经做了一些改进和提升,新的网络命名为 PointNet++,已经上传到Arxiv,欢迎大家阅读并讨论交流。