1.确切值(Exact values) vs 全文文本(Full text)
Elasticsearch中索引的数据可以大致分为两种类型
(1) 确切值(Exact values)
确切值是需要精准匹配的值。比如一个date或用户ID,对于2019-11-8,只输入2019-11是不能被检索出来。
(2) 全文文本(Full text)
对于全文文本,Elasticsearch会对文本分析(analyzes),然后使用结果建立一个倒排索引,可以支持模糊匹配,忽略大小写,近义词匹配等。
2.Elasticsearch分析器
什么时候使用分析器?
当我们索引一个文档,它的全文域被分析成词条以用来创建倒排索引。同时,当我们在全文域搜索 的时候,将查询字符串也需要通过相同的分析过程 ,以保证我们搜索的词条格式与索引中的词条格式一致。
- 当你查询一个全文域时, 会对查询字符串应用相同的分析器,以产生正确的搜索词条列表。
- 当你查询一个精确值域时,不会分析查询字符串,而是搜索你指定的精确值。
Elasticsearch的分析器组成
es的分析器由3部分组成:
(1)字符过滤器(character filter)
首先字符串会经过字符过滤器,他们的工作是在分词前处理字符串。字符过滤器能够去除HTML标记,或者转化为“&”为“and”等。
(2)分词器( Tokenizer )
一个简单的分词器可以根据空格或逗号将单词分开,表征化为一个个独立的词(term)。
(3)标记过滤器 ( token filter )
最后,每个词都通过所有表征过滤(token filters),它可以修改词(例如将"Quick"转为小写),去掉词(例如停用词像"a"、"and"``"the"等等),或者增加词(例如同义词像"jump"和"leap")
内置分析器
Elasticsearch还附带了一些预装的分析器,你可以直接使用它们。简单介绍几个:
- 标准分析器,Elasticsearch默认使用的分析器,它是分析各种语言文本最常用的选择,根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写
- 简单分析器,在任何不是字母的地方分隔文本,将词条小写
- 空格分析器,在空格的地方划分文本
- 语言分析器,可以考虑指定语言的特点
3. Elasticsearch的映射
在传统数据库中,我们会为每个字段指定存储类型,例如:varchar,int,datetime等等,就是为了能更精确的存储数据,防止数据类型格式混乱。
同样,ES的索引字段也需要为其指定类型,它就像数据库中的 schema,这种在ES称为映射(mapping)。
动态映射和静态映射
动态映射: 文档写入es时,es可根据写入内容的类型自动识别,生成mapping。主要的内容和类型的自动映射关系如下:
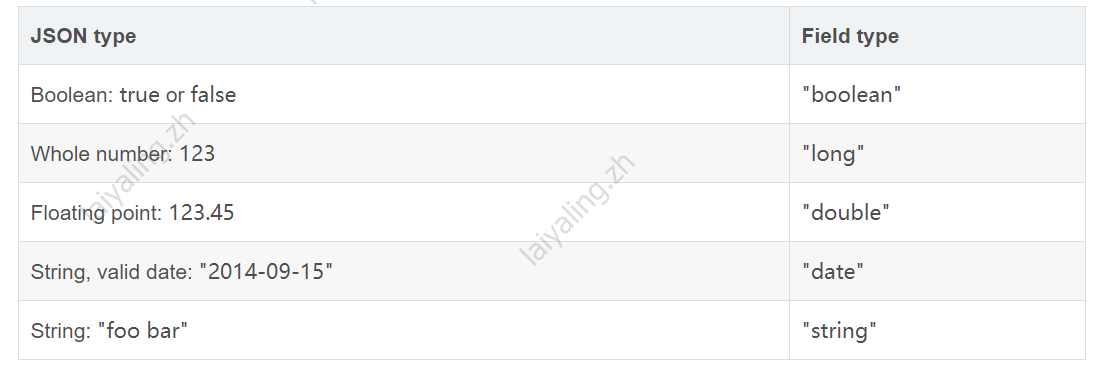
静态映射: 手动为索引指定字段类型
自定义MAPPING
创建索引时,可以先定义好索引的结构,即mapping,包括每个字段的类型,分析器,是否全文索引等。
1.type
es中的字段类型如下图:
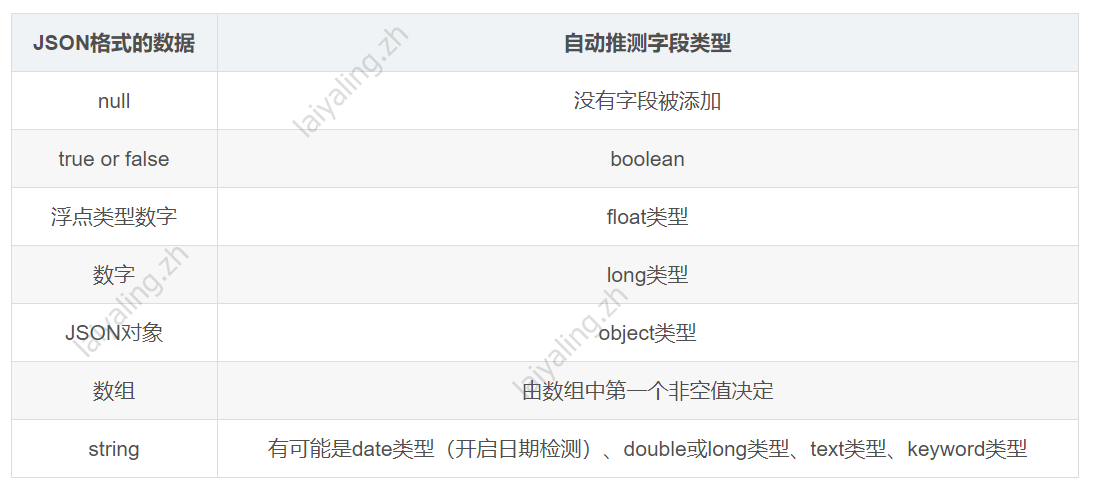
其中string中的text 和 keyword 的区别:
- text 用于索引全文值的字段,例如电子邮件正文或产品说明。他们在被索引之前会通过分词器将字符串转换为单个术语的列表。文本字段不用于排序,很少用于聚合。
- keyword 用于索引结构化内容的字段,例如电子邮件地址,主机名,状态代码,标签。它们通常用于过滤,排序,和聚合。keyword字段只能按其确切值进行搜索。
string类型的字段,默认的,考虑到包含全文本,它们的值在索引前要经过分析器分析,并且在全文搜索此字段前要把查询语句做分析处理。
对于string字段,两个最重要的映射参数是index和analyer。
2.index
index参数控制字符串以何种方式被索引。它包含以下三个值当中的一个:

string类型字段默认值是analyzed。如果我们想映射字段为确切值,我们需要设置它为not_analyzed:
{
"tag": {
"type": "string",
"index": "not_analyzed"
}
}
其他简单类型——long、double、date等等——也接受index参数,但相应的值只能是no和not_analyzed,它们的值不能被分析。
3.analyzer
对于analyzed类型的字符串字段,使用analyzer参数来指定哪一种分析器将在搜索和索引的时候使用。默认的,Elasticsearch使用standard分析器,但是你可以通过指定一个内建的分析器来更改它,例如whitespace、simple或english。中文的可以使用ik分析器。
{
'value': {
'type': 'text',
'analyzer': 'ik_max_word',
'search_analyzer': 'ik_max_syn',
}
}
下面给出一个自定义mapping的示例
示例1:
"mappings": {
"doc": {
"properties": {
"uid": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "english",
"search_analyzer": "standard"
}
}
}
}
示例2:
mapping = {
"settings": {
"analysis": {
"analyzer": {
"ik_max_syn": {
"tokenizer": "ik_max_word",
"filter": ["synonym", "stopword"]
},
"ik_smart_syn": {
"tokenizer": "ik_smart",
"filter": ["synonym", "stopword"]
}
},
"filter": {
"synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt",
"updateable": True
},
"stopword": {
"type": "stop",
"stopwords_path": "analysis/stopwords.txt",
"updateable": True
}
}
},
"similarity": {
"my_custom_similarity": {
"type": "BM25",
"k1": 1.2,
"b": 0.75,
"discount_overlaps": False
}
}
},
"mappings": {
'properties': {
'value': {
'type': 'text',
'analyzer': 'ik_max_word',
'search_analyzer': 'ik_max_syn',
},
'attr': {
'type': 'text',
'analyzer': 'ik_max_word',
'search_analyzer': 'ik_max_syn',
},
'node': {
"type": "keyword",
}
}
}
}
参考链接:https://blog.csdn.net/z69183787/article/details/78133883