文件读写
open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
- file: 必需,文件路径(相对或者绝对路径)
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
| 模式 | 描述(mode参数说明) |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
文件的遍历代码:
fname = input("请输入要打开的文件: ")
fo = open(fname, "r")
for line in fo:
print(line)
fo.close()
文件的打印代码:
fname = input("请输入要打开的文件: ")
fo = open(fname, "r")
for line in fo.readlines():
print(line)
fo.close()
一.excel转csv。
def ExcelToCsv_1(StartName, SheetName, EndName): ''' 函数功能: 将excel格式文件转换为csv格式文件,使用iat方法 StartName: excel表格的文件路径 SheetNmae: excel表格中的表格名称 EndName: csv文件的保存路径 ''' grade = pd.read_excel(StartName, sheet_name=SheetName) for i in range(len(grade.index)): for j in range(1, len(grade.columns)): if grade.iloc[i, j] == '优秀': grade.iat[i, j] = 90 elif grade.iloc[i, j] == '良好': grade.iat[i, j] = 80 elif grade.iloc[i, j] == '合格': grade.iat[i, j] = 60 else: grade.iat[i, j] = 0 grade.to_csv(EndName) def ExcelToCsv_2(StartName, SheetName, EndName): ''' 函数功能: 将excel格式文件转换为csv格式文件,使用replace方法 StartName: excel表格的文件路径 SheetNmae: excel表格中的表格名称 EndName: csv文件的保存路径 ''' grade = pd.read_excel(StartName, sheet_name=SheetName) Grade = grade.replace("优秀", "90") Grade = Grade.replace("良好", "80") Grade = Grade.replace("不合格", "60") Grade = Grade.replace("合格", "60") Grade = Grade.fillna(value = 0) Grade.to_csv(EndName) ExcelToCsv_2("C:/Users/86135/Desktop/Python成绩登记信计.xlsx", "Sheet1", "C:/Users/86135/Desktop/Python成绩登记信计.csv")

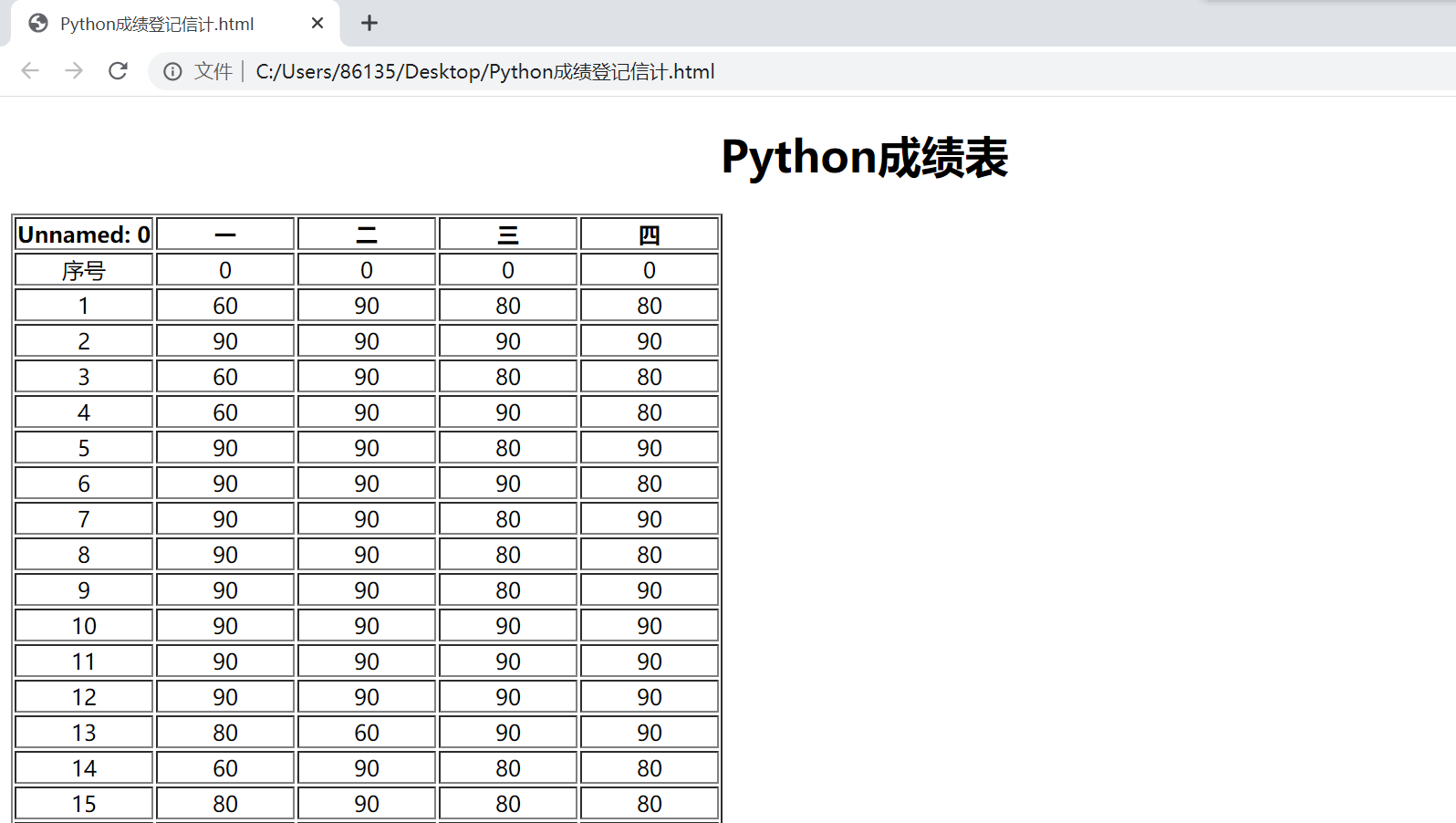
二.csv转为html格式文件。
def fill_data(excel, length=4): ''' 函数功能:填充表格的一行数据,返回html格式的字符串text excel: 表格中的一行数据 length: 表格中需要填充的数据个数(即列数),默认为4个 由于生成csv文件时自动增加了1列数据,因此在format()函数从1开始 ''' text = '<tr>' for i in range(length): tmp = '<td align="center">{}</td>'.format(excel[i+1]) text += tmp text += "</tr> " return text def GetCsv(csvFile): ''' 函数功能:打开csv文件并获取数据,返回文件数据 csvFile: csv文件的路径和名称 ''' ls = [] csv = open(csvFile, 'r', encoding="utf-8") for line in csv: line = line.replace(' ', '') ls.append(line.split(',')) return ls def CsvToHtml(csvFile, HTMLFILE, thNum): ''' 函数功能:将csv格式文件转换为html格式文件 csvFile: 需要打开和读取数据的csv文件路径 HTMLFILE: 保存的html文件路径 thNum: csv文件的列数,需注意其中是否包括csv文件第1列无意义的数据, 此处包含因此在调用时需要增加1 ''' # HTML1 HTML2 分别为html文件的首部和尾部 HTML1 = ''' <!DOCTYPE HTML> <html> <body> <meta charset=gbk2313> <h1 align=center>Python成绩表</h2> <table border='blue'> ''' HTML2 = "</table> </body> </html>" csv_list = GetCsv(csvFile) # 获得csv文件数据 hF = open(HTMLFILE, 'w') # 创建html文件 hF.write(HTML1) # 写入html文件首部 for i in range(1, thNum+1): # 写入表格的表头(即第1行) hF.write('<th width="20%">{}</th> '.format(csv_list[0][i])) hF.write("</tr> ") for i in range(1, len(csv_list)): # 写入表格的数据,从第2行开始为数据 hF.write(fill_data(csv_list[i], 5)) hF.write(HTML2) # 写入html文件尾部 hF.close() # 关闭html文件 CsvToHtml("C:/Users/86135/Desktop/Python成绩登记信计.csv", "C:/Users/86135/Desktop/Python成绩登记信计.html", 5)