随机森林的一般步骤:
- 对原始数据集进行可放回随机抽样成K组子数据集
- 从样本的N个特征随机抽样m个特征
- 对每个子数据集构建最优学习模型
- 对于新的输入数据,根据K个最优学习模型,得到最终结果
采用bagging的方法可以降低方差,但不能降低偏差
公式法分析bagging法模型的方差问题:
假设子数据集变量的方差为,两两变量之间的相关性为
所以,bagging法的方差:
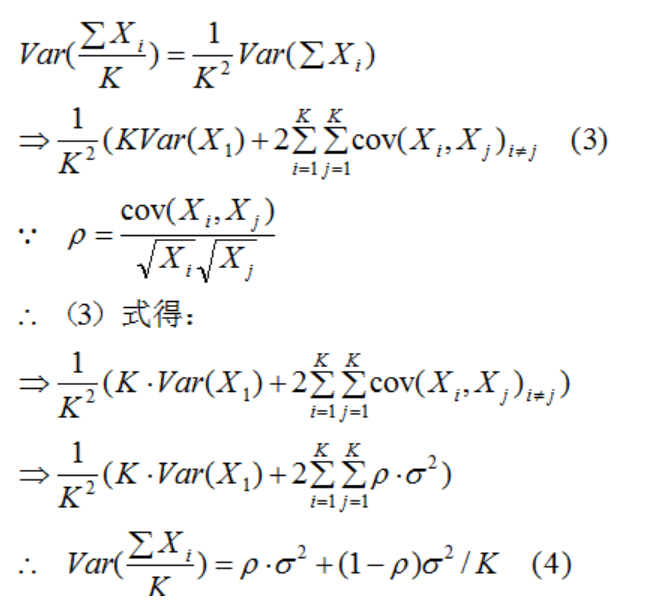
由(4)式可得,bagging法的方差减小了
结论:bagging法的模型偏差与子模型的偏差接近,方差较子模型的方差减小。所以,随机森林的主要作用是降低模型的复杂度,解决模型的过拟合问题。
随机森林是指利用多棵决策树对样本进行训练并预测的一种算法。也就是说随机森林算法是一个包含多个决策树的算法,其输出的类别是由个别决策树输出的类别的众树来决定的。在Sklearn模块库中,与随机森林算法相关的函数都位于集成算法模块ensemble中,相关的算法函数包括随机森林算法(RandomForestClassifier)、袋装算法(BaggingClassifier)、完全随机树算法(ExtraTreesClassifier)、迭代算法(Adaboost)、GBT梯度Boosting树算法(GradientBoostingClassifier)、梯度回归算法(GradientBoostingRegressor)、投票算法(VotingClassifier)。
最后总结一下随机森林的优缺点:
一、优点:
1、对于大部分的数据,它的分类效果比较好。
2、能处理高维特征,不容易产生过拟合,模型训练速度比较快,特别是对于大数据而言。
3、在决定类别时,它可以评估变数的重要性。
4、对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化。
二、缺点:
1、对少量数据集和低维数据集的分类不一定可以得到很好的效果。
2、 计算速度比单个的决策树慢。
3、 当我们需要推断超出范围的独立变量或非独立变量,随机森林做得并不好。
参考链接:
【1】http://www.sohu.com/a/279136744_163476
【2】https://baijiahao.baidu.com/s?id=1612329431904493042&wfr=spider&for=pc