主从机构
主:jobtracker
从:tasktracker
四个阶段
1、 split
2、 Mapper: key-value(对象)
3、 shuffle
a) 分区(partition,HashPartition:根据 key 的 hashcode值 和 Reduce 的数量 模运算),可以自定义分区,运算速度要快,一定要解决数据倾斜和reduce
的负载均衡。
b) 排序: 默认按照字典排序。WriterCompartor(比较)
c) 合并:减少当前mapper输出数据,根据key相同(比较),把value进行合并。
d) 分组(key相同(比较),value组成一个集合)(merge)
4、Reduce
a) 输入数据: key +迭代器
Hadoop2.5 HA 搭建
四台机器:hadoop1, hadoop2, hadoop3, hadoop4
|
NN |
DN |
ZK |
ZKFC |
JN |
RM |
NM(任务管理器) |
|
|
hadoop1 |
Y |
Y |
Y |
Y |
|||
|
hadoop2 |
Y |
Y |
Y |
Y |
Y |
Y |
|
|
hadoop3 |
Y |
Y |
Y |
Y |
|||
|
hadoop4 |
Y |
Y |
Y |
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bjsxt</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.200.128:2181,192.168.200.4:2181,192.168.200.5:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.5.2</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>bjsxt</value>
</property>
<property>
<name>dfs.ha.namenodes.bjsxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn1</name>
<value>192.168.200.128:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn2</name>
<value>192.168.200.4:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.bjsxt.nn1</name>
<value>192.168.200.128:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.bjsxt.nn2</name>
<value>192.168.200.4:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.200.4:8485;192.168.200.5:8485;192.168.200.6:8485/bjsxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.bjsxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/jn/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
- 准备 zookeeper
a) 三台 zookeeper: hadoop1, hadoop2, hadoop3
b) 编辑 zoo.cfg 配置文件
- 修改 dataDir=/opt/zookeeper
- server.1=192.168.200.128:2888:3888
server.2=192.168.200.4:2888:3888
server.3=192.168.200.5:2888:3888
c) 在dataDir目录中创建一个myid的文件,文件内容1,2,3
- 配置 hadoop中的slaves
- 启动三个zookeeper: ./zkServer.sh start
- 启动三个journalNode: ./Hadoop-daemon.sh start journalnode
- 在其中一个namenode上格式化: hdfs namenode –format
- 把刚刚格式化之后的元数据拷贝到另外 一个namenode上
a) 启动刚刚格式化的namenode
b) 在没有格式化的namenode上执行:hdfs namenode –bootstrapStandby
c) 启动第二个namenode
9. 在其中一个namenode上初始化 zkfc:hdfs zkfc –formatZK
10. 停止上面节点:stop-dfs.sh
11. 全面启动: start-dfs.sh
配置mapreduce
1>修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2> 修改yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3> 启动
./start-yarn.sh
访问路径
hadoop2.2.5mapreduce的web界面 http://192.168.200.128:8088/
hdfs web界面 http://192.168.200.128:50070/
手动切换命令
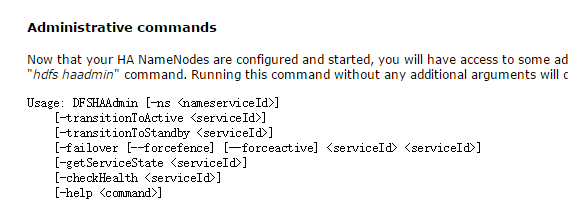
- transitionToActiove <serviceId> // serviceId指 nn1,nn2
建立输入文件目录
./hdfs dfs -mkdir -p /usr/input/hot
删除文件目录
./hdfs dfs -rm /usr/input/hot
上传文件到输入目录
./hdfs dfs -put /usr/data /usr/input/hot
查看目录下文件
./hdfs dfs -ls /usr/input/hot
./hadoop jar /usr/local/hadoop2.jar RunJob