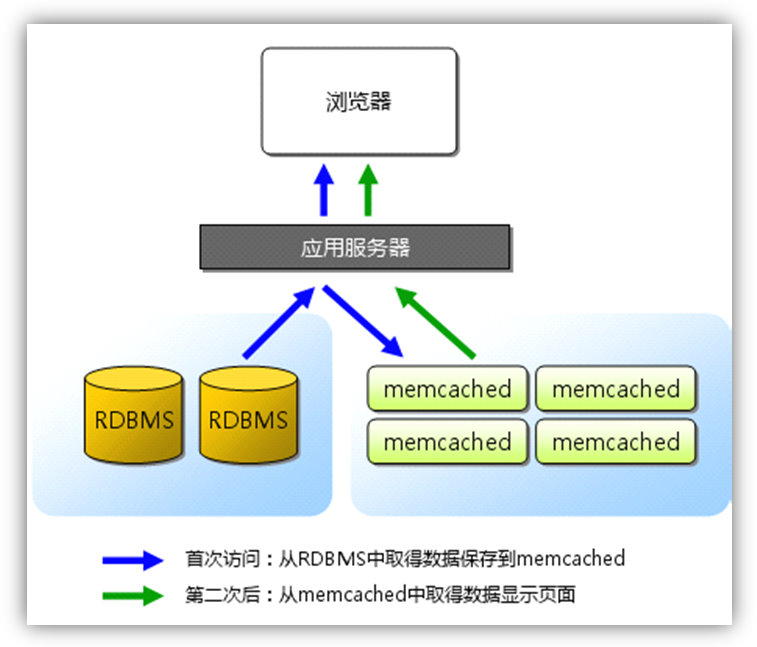
Memcached概述

什么是Memcached?
先看看下面几个概念:
Memory:内存存储,不言而喻,速度快,对于内存的要求高,不指出的话所缓存的内容非持久化。对于CPU要求很低,所以常常采用将Memcached服务端和一些CPU高消耗Memory低消耗应用部属在一起。
Cache:在ASP.NET中已经可以实现对页面局部进行缓存,而使用Memcached的缓存比 ASP.NET的局部缓存更加灵活,可以缓存任意的对象,不管是否在页面上输出。ASP.NET的缓存是基于本地(单机)的,受到服务器空闲内存空间的限制,以及多台web服务器本地缓存的同步,但是没有网络存取的延迟。而Memcached最大的优点是可以分布式的部署,这对于大规模应用来 说也是必不可少的要求。最初的缓存做法是在线程内对对象进行缓存,但这样进程间就无法共享缓存,命中率非常低,导致缓存效率极低。后来出现了共享内存的缓存,多个进程或者线程共享同一块缓存,但毕竟还是只能局限在一台机器上,多台机器做相同的缓存同样是一种资源的浪费,而且命中率也比较低。
分布式扩展:Memcached的很突出一个优点,就是采用了可分布式扩展的模式。可以将部属在一台机器上的多个Memcached服务实例或者部署在多个机器上的Memcached服务器组成一个虚拟的服务端,对于调用者来说完全屏蔽和透明。提高的单机器的内存利用率。
Socket通信:传输内容的大小以及序列化的问题需要注意,虽然Memcached通常会被放置到内网作为Cache,Socket传输速率应该比较高(当前支持TCP和UDP两种模式,同时根据客户端的不同可以选择调用方式),但是序列化成本和带宽成本还是需要注意。这里也提一下序列化,对于对象序列化的性能往往让大家头痛,但是如果对于同一类的Class对象序列化传输,第一次序列化时间比较长,后续就会优化,其实也就是说序列化最大的消耗不是对象序列化,而是类的序列化。因此在Memcached中保存的往往是较小的内容。
Memcached 原理
Memcached是一个独立的,高性能的,分布式的内存对象缓存系统。通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视 频、文件以及数据库检索的结果等。它的缓存是一种分布式的,也就是可以允许不同主机上的多个用户同时访问这个缓存系统, 这种方法不仅解决了共享内存只能是单机的弊端,同时也解决了数据库检索的压力,最大的优点是提高了访问获取数据的速度!Memcached 使用libevent(网络接口的封装)来进行网络并发连接的处理,能够保持在很大并发情况下,仍旧能够保持快速的响应能力互联网公司使用代表:Sina,Sohu,Yahoo,Twitter等等。
Memcached的机制就是一个很简单的Cache,把东西放进去,然后可以取出来,如果发现所提供的Key没有命中,那么就很直白的告诉你,你这个key没有任何对应的东西在缓存里,去数据库或者其他地方取,当你在外部数据源取到的时候,可以直接将内容置入到Cache中,这样下次就可以命中了。这里会提到怎么去同步这些数据,两种方式,一种就是在你修改了以后立刻更新Cache内容,这样就会即时生效。另一种是说容许有失效时间,到了失效时间,自然就会将内容删除,此时再去去的时候就会命中不了,然后再次将内容置入Cache,用来更新内容。后者用在一些时时性要求不高,写入不频繁的情况。刚才我们提到Memcached 的传输协议,因此传输的数据必须序列化,C# class里使用[Serializable]标示,并且为了性能,Memcached Client采用了压缩的机制使传输的数据更小。其实Memcached服务端本身是单实例的,只是在客户端实现过程中可以根据存储的主键作分区存储,而这个区就是Memcached服务端的一个或者多个实例
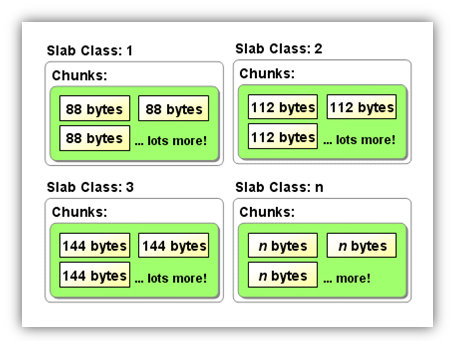
内存分配机制:首先要说明的是Memcached支持最大的存储对象为1M。它的内存分配比较特殊,但是这样的分配方式其实也是对于性能考虑的,简单的分配机制可以更容易回收再分配,节省对于CPU的使用。这里用一个酒窖比喻来说明这种内存分配机制,首先在Memcached起来的时候可以通过参数设置使用的总共的Memory,当你第一次往Memcached存储数据时, Memcached会去申请1MB的内存, 把该块内存称为一个slab, 也称为一个page, 如果可以存储这个数据的最佳的chunk大小为128B,那么Memcached会把刚申请的slab以128B为单位进行分割成8192块. 当这页slab的所有chunk都被用完时,并且继续有数据需要存储在128B的chunk里面时,如果已经申请的内存小于最大可申请内存10MB 时, Memcached继续去申请1M内存,继续以128B为单位进行分割再进行存储;如果已经无法继续申请内存,那么Memcached会先根据LRU 算法把队列里面最久没有被使用到的chunk进行释放后,再将该chunk用于存储. 这个就是建造一个酒窖,然后在有酒进入的时候,首先申请(通常是1M)的空间,用来建酒架,酒架根据这个酒瓶的大小分割酒架为多个小格子安放酒瓶,将同样大小范围内的酒瓶都放置在一类酒架上面。例如20cm半径的酒瓶放置在可以容纳20-25cm的酒架A上,30cm半径的酒瓶就放置在容纳25-30cm的酒架B上。回收机制也很简单,首先新酒入库,看看酒架是否有可以回收的地方,如果有直接使用,如果没有申请新的地方,如果申请不到,采用配置的过期策略。这个特点来看,如果要放的内容大小十分离散,同时大小比例相差梯度很明显,那么可能对于使用空间来说不好,可能在酒架A上就放了一瓶酒,但占用掉了一个酒架的位置。
为了避免使用Memcached时出现异常, 使用Memcached的项目需要注意:
1. 不能往Memcached存储一个大于1MB的数据.
2. 往Memcached存储的所有数据,如果数据的大小分布于各种chunk大小区间,从64B到1MB都有,可能会造成内存的极大浪费以及Memcached的异常.
举个例子:
Memcached最大可申请内存为2M, 你第一次存储一个10B的数据,那么Memcached会申请1MB的内存,以64B进行分割然后存储该数据, 第二次存储一个90B的数据,那么Memcached会继续申请1M的内存,以128B进行分割然后存储该数据, 第三次如果你想存储一个150B的数据, 如果可以继续申请内存, Memcached会申请1M内存以256B的大小进行分割, 但是由于最大可申请仅仅为2MB,所以会导致该数据无法存储.
数据过期方式
• Lazy Expiration
Memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过
期。这种技术被称为lazy(惰性)expiration。因此,Memcached不会在过期监视上耗费
CPU时间。
• LRU
Memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不
足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间。顾名思
义,这是删除“最近最少使用”的记录的机制。因此,当Memcached的内存空间不足时
(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空
间分配给新的记录。从缓存的实用角度来看,该模型十分理想。
分布式
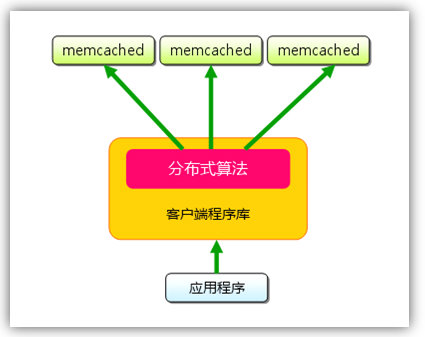
假设有3个客户端1, 2, 3,3台Memcached A, B, C:
Client 1想把数据”barbaz”以key “foo”存储。Client 1首先参考节点列表(A, B, C),计算key “foo”的哈希值,假设Memcached B被选中。接着,Client 1直接connect到Memcached B,通过key “foo”把数据”barbaz”存储进去。Client 2使用与Client 1相同的客户端库(意味着key的哈希算法相同),也拥有同样的Memcached列表(A, B, C)。于是,经过相同的哈希计算,Client 2计算出key “foo”在Memcached B上,然后它直接请求Memcached B,得到数据”barbaz”。
Memcached的使用场合
当运行在单独的Web服务器上,你可以很容易地清除一个已经确认被改变了的缓存。可惜,ASP.NET没有一个很好的方法来支持多服务器。每个服务器上的缓存都对其他缓存的改变一无所知。ASP.NET允许通过基于文件系统和数据库表的触发器取消一个缓存。然而,这也存在问题,比如数据库触发器需要使用昂贵的轮询,以及触发器本身冗长的编程。好像.NET4.0有了新的解决方法。我们还有别的选择,Memcached就一种。但是Memcached不是万能的,它也不是适用在所有场合。 Memcached是“分布式”的内存对象缓存系统,那么就是说,那些不需要“分布”的,不需要共享的,或者干脆规模小到只有一台服务器的应用, Memcached不会带来任何好处,相反还会拖慢系统效率,因为网络连接同样需要资源,即使是UNIX本地连接也一样。Memcached本地读写速度要比直接ASP.NET缓存(IIS进程)内存慢很多倍,请看下面的测试数据。可见,如果只是 本地级缓存,使用Memcached是非常不划算的。Memcached在很多时候都是作为数据库前端cache使用的。因为它比数据库少了很多SQL解析、磁盘操作等开销,而且它是使用内存来管理数据的, 所以它可以提供比直接读取数据库更好的性能,在大型系统中,访问同样的数据是很频繁的,Memcached可以大大降低数据库压力,使系统执行效率提升。Memcached也经常作为服务器之间数据共享的存储媒介,存储一些系统的共享数据。
需要注意的是,Memcached使用内存管理数据,所以它是易失的,当服务器重启,或者Memcached进程中止,数据便会丢失,所以 Memcached不能用来持久保存数据。很多人的错误理解,Memcached的性能非常好,好到了内存和硬盘的对比程度,它的实际瓶颈在于网络连接,它和使用磁盘的数据库系统相比,好处在于它本身非常“轻”,因为没有过多的开销和直接 的读写方式,它可以轻松应付非常大的数据交换量,,Memcached进程本身并不占用多少CPU资源的情况。如果web系统采用ASP.NET缓存 + Memcached的方式。性能将会有个不错的提升。
ASP.NET缓存:本地的,速度更快,一般将highly common的数据或者程序控制数据用ASP.NET缓存。
Memcached:存一些来自数据库的数据或者web服务器的共享数据。
来源:
http://www.cnblogs.com/purplefox2008/archive/2010/08/17/1801631.html
相关:
http://baike.baidu.com/link?url=dFyRv0YKbxTwSoV-i13fLsHAqzFCehKRJlrWd3FcdrayQng_Edsb1I7g8gWRb4bWKfgSgoTOZfLHwfhpuEpeZK