1 网页结构
html:超文本标记语言------->类似人的鼻子耳朵,长在那里,大体骨架就是那个样子
css:层叠样式表------->这个是外观的深化,比如贴个双眼皮,橙色眼睛。。。
js:动态脚本语言----->人的技能,跳舞rap
学习网站:w3cshool
2 requests使用
(1)开发环境使用pycharm
(2)爬虫基本原理
request---->向服务器发送访问的请求
responce---->服务器收到用户请求以后,会验证请求的有效性然后向用户发送响应的内容。客户端收到响应并显示出来。
(3)get post请求方式
get:
post:
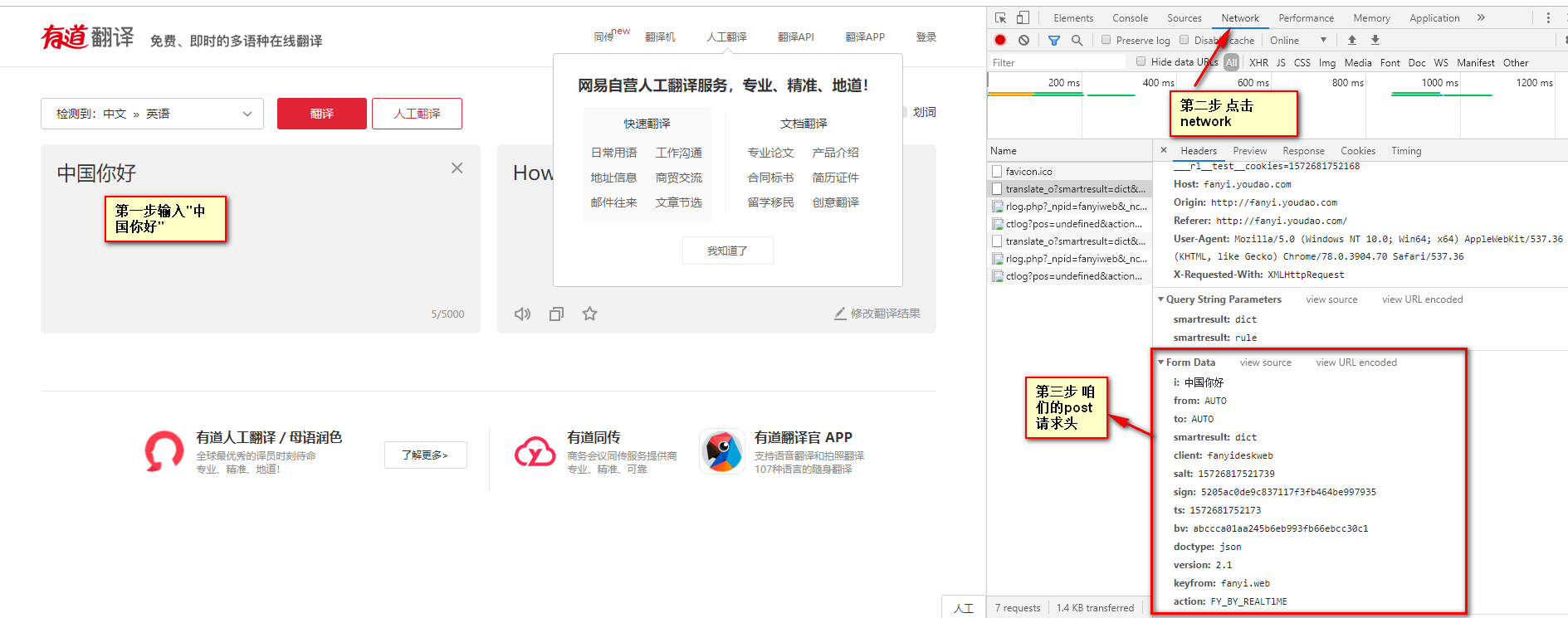
使用有道翻译网页作为案例,http://fanyi.youdao.com/,按F12进入开发者模式,单击network,此时为空。
在输入框中输入"中国你好"单击翻译
单击network---->XHR找到翻译数据
查看请求方式为post,并可以加那个headers中的URL复制出来,因为post需要自己构建请求头
使用request.post抓取有道翻译的结果


1 import requests 2 import json 3 def get_translate_date(word=None): 4 url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' 5 Form_data = {'i':word, 'from':'AUTO','to': 'AUTO','smartresult': 'dict', 'client':'fanyideskweb', 6 'salt':'1512399450582','sign':'78181ebbdcb38de9b4a3f4cd1d38816b','doctype':'json', 7 'version': '2.1','keyfrom':'fanyi.web','action':'FY_BY_CLICKBUTTION','typoResult':'false'} 8 9 response = requests.post(url, data=Form_data) # 请求表单数据 10 content = json.loads(response.text) # 将JSON格式字符串转字典 11 print(content) 12 print(content['translateResult'][0][0]['tgt']) # 打印翻译后的数据 13 if __name__ == '__main__': 14 get_translate_date('中国你好')
3 使用beautiful soup解析网页
通过requests可以抓取网页源码并解析提取数据,beautiful soup被移植到bs4库中,也就是安装它需要先安装bs4.官方中文文档https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
(1)打开网页
(2)筛选路径soup.select()
随便选择一句话----->右击检查(右侧弹出开发者界面)----->右击左边高亮数据------>选择copy----->选择copy selector
(3)引入re库
https://docs.python.org/zh-cn/3/library/re.html re中文官网
(4)最终代码
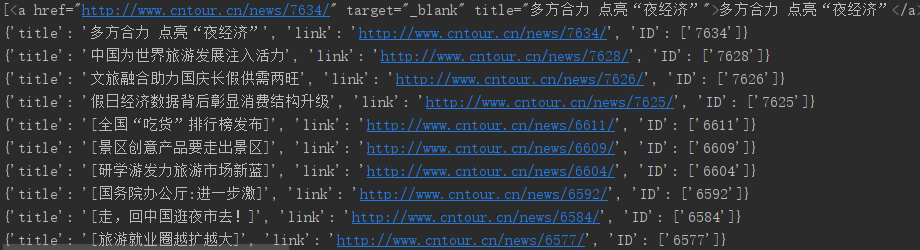
1 import requests 2 from bs4 import BeautifulSoup 3 import re 4 5 url="http://www.cntour.cn/" 6 strhtml=requests.get(url) 7 soup=BeautifulSoup(strhtml.text,'lxml')# 通过lxml解析后转换为树形结构,每个节点都是对象 8 data=soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a") 9 print(data) 10 for item in data: 11 result={ 12 'title':item.get_text(),#连接在<a>标签中用get_text 13 'link':item.get('href'),#在<a>href属性用get 14 'ID':re.findall('d+',item.get('href'))#d表示匹配数字 +表示匹配前一个字符1次或者多次 15 } 16 print(result)
(5)最后结果
完事!