使用selenium模拟登陆网站时,有些网站会识别chrome driver里的json信息,从而判断是不是爬虫程序,做到反爬效果。(比如知乎)
下面说明下怎么手动启动chromedriver
1)、启动chrome
给开始菜单里的chrome或者桌面快捷方式,右键打开文件夹所在路径
2)打开dos,切到chrome路径,执行:chrome.exe --remote-debugging-port=9090(端口自定义),表示以debug模式启动,监听端口是9090

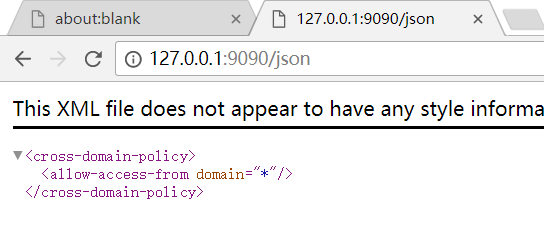
3)获取json,在启动前,需确保所有chrome实例已经关闭,否则会返回拒绝连接。
class ZhihuSpider(scrapy.Spider): name = 'zhihu_2' allowed_domains = ['zhihu.com'] start_urls = ['http://zhihu.com/'] headers = { "HOST": "www.zhihu.com", "Referer": "https://www.zhizhu.com", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36" } custom_settings = { "COOKIES_ENABLED": True, "HTTPERROR_ALLOWED_CODES" : [400] } def parse(self, response): from selenium import webdriver from scrapy.selector import Selector from selenium.webdriver.chrome.options import Options chrome_option = Options() chrome_option.add_argument("--disable-extensions") chrome_option.add_experimental_option("debuggerAddress","127.0.0.1:9090") project_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__))) chromedriver_dir = os.path.join(project_dir, "tools\chromedriver.exe") browser = webdriver.Chrome( executable_path=chromedriver_dir,chrome_options=chrome_option) browser.get("https://www.zhihu.com/signup?next=%2F") # 模拟登录知乎,选择登录选项 info = response.xpath('//*[@id="root"]/div/main/div/div/div/div[2]/div[2]/span/text()') browser.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div/div[2]/div[2]/span').click() # 输入账号//*div[@class='SignFlow-accountInput Input-wrapper']/input browser.find_element_by_xpath( '//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/div[1]/div[2]/div[1]/input').send_keys( "656521736@qq.com") # 输入密码 browser.find_element_by_xpath( '//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/div[2]/div/div[1]/input').send_keys("*****") # 模拟登录知乎,点击登录按钮 #//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/button # browser.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/button').click() # def start_requests(self): # return [ Request('https://www.zhihu.com/signup?next=%2F', headers=self.headers, encoding="utf-8", dont_filter=True, callback=self.parse)]
调用
webdriver.Chrome方法是,加上一个参数chrome_options即可