


使用pycharm debug调试效率会比较慢,因为每次调试都需要向url发送请求,等返回信息,scrapy提供一种方便调试的功能,如下:
>>>(third_project) bigni@bigni:pachong$ scrapy shell http://blog.jobbole.com/112239/ >>> title = response.xpath('//*[@id="post-112239"]/div[1]/h1') >>> title [<Selector xpath='//*[@id="post-112239"]/div[1]/h1' data='<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'>] >>> title.extract() ['<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'] >>> title = response.xpath('//*[@id="post-112239"]/div[1]/h1/text()') >>> title [<Selector xpath='//*[@id="post-112239"]/div[1]/h1/text()' data='谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征'>]
extract()方法可以取到select list里的date,text()方法可以取到内容。
In [37]: title2 = response.xpath("//*[@id='post-112239']/div[1]/h1").extract() In [38]: title2 Out[38]: ['<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'] In [39]: title2 = response.xpath("//*[@id='post-112239']/div[1]/h1") In [40]: title2 Out[40]: [<Selector xpath="//*[@id='post-112239']/div[1]/h1" data='<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'>] In [41]: title2 = response.xpath("//*[@id='post-112239']/div[1]/h1/text()").extr ...: act() In [42]: title2 Out[42]: ['谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征'] In [43]:
PS:在chrome里,按F12看到的代码是加载完所有插件后的,比如JS,如果通过通过根路径来定位要找的内容是容易出错的,因为xpath搜索的不会把js等生成的元素计算在内,这个可以通过鼠标右键查看源码来判断哪些是js生成的,然后过滤掉。
对于属性里有多个值的情况,比如class 里有多个值:

可以使用scrapy内置的contains方法:
In [44]: ret = response.xpath("//div[contains(@class,'post-112239')]") In [45]: ret Out[45]: [<Selector xpath="//div[contains(@class,'post-112239')]" data='<div class="post-112239 post type-post s'>]
如果要爬取下面这个内容,可以这么操作:
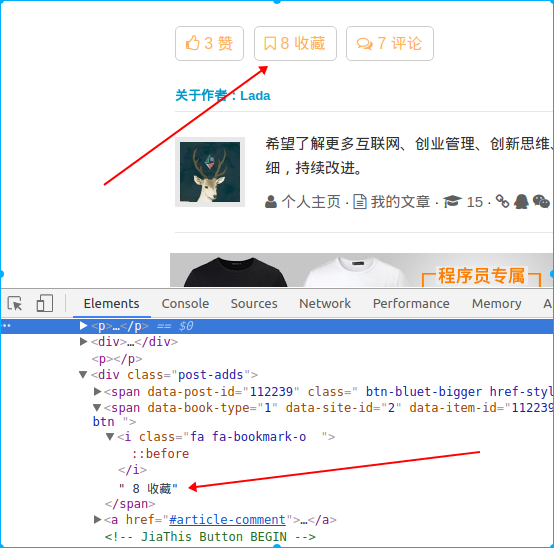
In [54]: rest = response.xpath('//*[@id="post-112239"]/div[3]/div[4]/span[2]/tex ...: t()').extract()[0] In [55]: rest Out[55]: ' 8 收藏'
接着再用正则去掉别的信息,由于在scrapy shell中直接调用re模块会报错,那可以用ipython调试
In [71]: ret = re.match(r".*(d+).*",' 8 收藏') In [72]: ret.group(1) Out[72]: '8'