上节说到Pipeline会拦截item,根据设置的优先级,item会依次经过这些Pipeline,所以可以通过Pipeline来保存文件到json、数据库等等。
下面是自定义json
#存储item到json文件 class JsonWithEncodingPipeline(object): def __init__(self): #使用codecs模块来打开文件,可以帮我们解决很多编码问题,下面先初始化打开一个json文件 import codecs self.file = codecs.open('article.json','w',encoding='utf-8') #接着创建process_item方法执行item的具体的动作 def process_item(self, item, spider): import json #注意ensure_ascii入参设置成False,否则在存储非英文的字符会报错 lines = json.dumps(dict(item),ensure_ascii=False) + " " self.file.write(lines) #注意最后需要返回item,因为可能后面的Pipeline会调用它 return item #最后关闭文件 def spider_close(self,spider): self.file.close()
scrapy内置了json方法:
from scrapy.exporters import JsonItemExporter
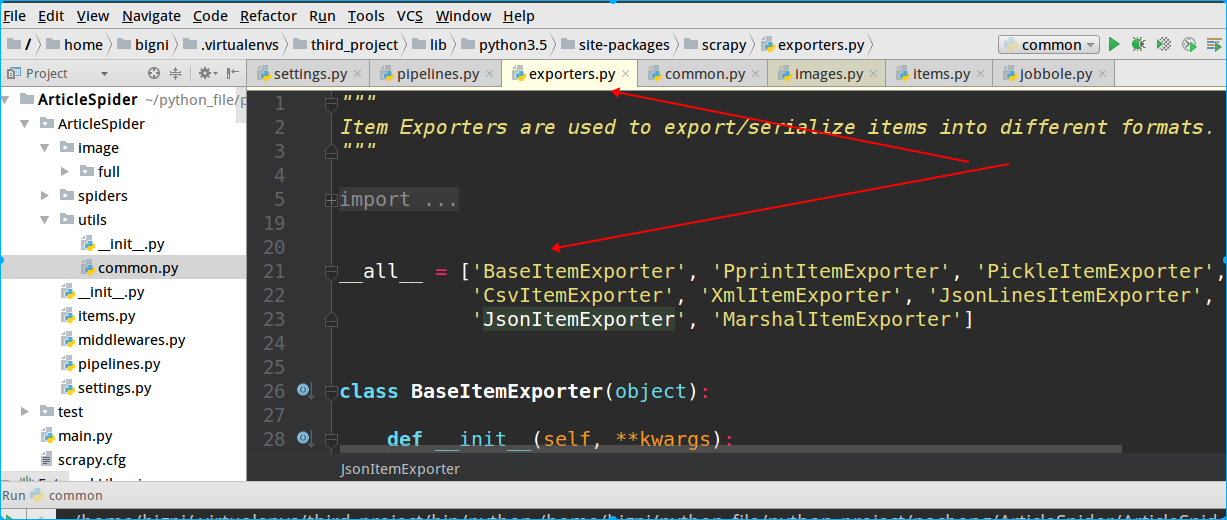
除了JsonItemExporter,scrapy提供了多种类型的exporter
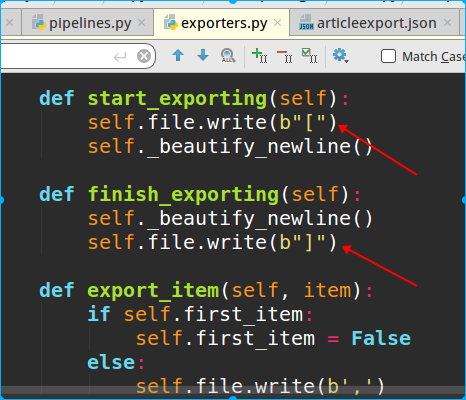
class JsonExporterPipeline(object): #调用scrapy提供的json export导出json文件 def __init__(self): #打开一个json文件 self.file = open('articleexport.json','wb') #创建一个exporter实例,入参分别是下面三个,类似前面的自定义导出json self.exporter = JsonItemExporter(self.file,encoding='utf-8',ensure_ascii=False) #开始导出 self.exporter.start_exporting() def close_spider(self,spider): #完成导出 self.exporter.finish_exporting() #关闭文件 self.file.close() #最后也需要调用process_item返回item def process_item(self, item, spider): self.exporter.export_item(item) return item
和自定义json相比,存的文件由【】
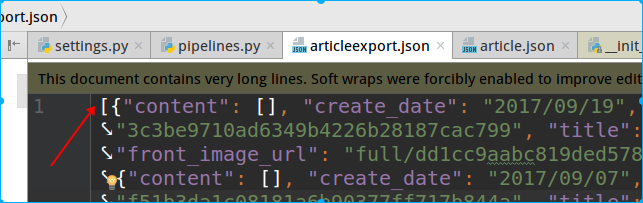
通过源码可以看到如下:
接着是如何把数据存储到mysql,我这开发环境是ubuntu,支持的mysql-client工具不多,免费的就用Mysql Workbench,也可以使用navicat(要收费)
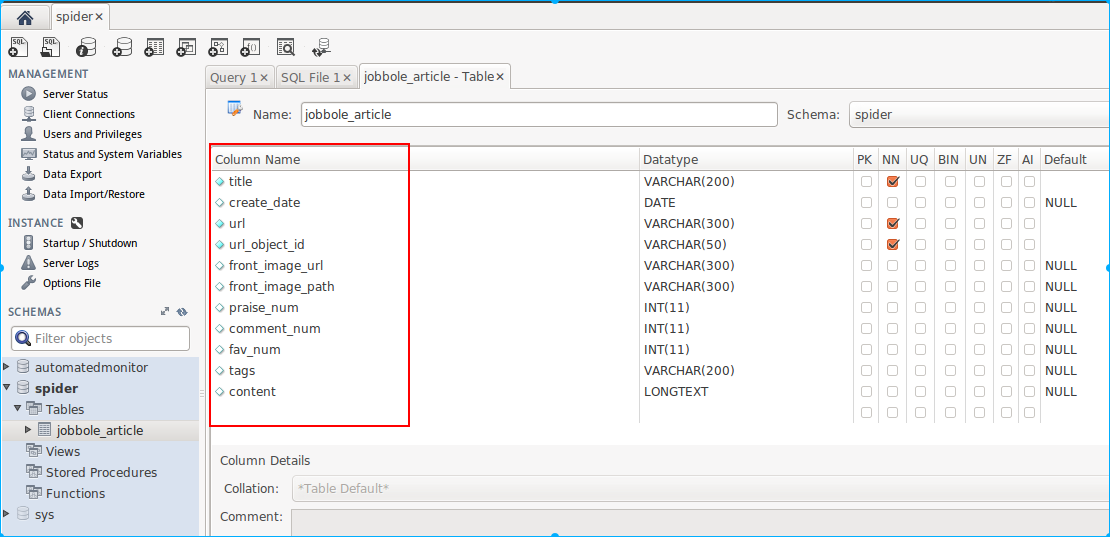
spider要创建的一张表,和ArticleSpider项目里的item一一对应就行。
然后接下来是配置程序连接mysql
这里我使用第三方库pymysql来连接mysql,安装方式很简单,可以使用pycharm内置的包安装,也可以在虚拟环境用pip安装
然后直接在pipline里创建mysql的pipline
import pymysql class MysqlPipeline(object): def __init__(self): """ 初始化,建立mysql连接conn,并创建游标cursor """ self.conn = pymysql.connect( host='localhost', database='spider', user='root', passwd='123456', charset='utf8', use_unicode=True ) self.cursor = self.conn.cursor() def process_item(self,item,spider): #要执行的sql语句 insert_sql = """ insert into jobbole_article(title,create_date,url,url_object_id, front_image_url,front_image_path,praise_num,comment_num,fav_num,tags,content) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) """ #使用游标的execute方法执行sql self.cursor.execute(insert_sql,(item["title"],item['create_date'], item['url'],item['url_object_id'], item['front_image_url'],item['front_image_path'], item['praise_num'],item['comment_num'],item['fav_num'], item['tags'],item['content'])) #commit提交才能生效 self.conn.commit() return item
上面的这种mysql存储方式是同步的,也就是execute和commit不执行玩,是不能继续存储数据的,而且明显的scrapy爬取速度会比数据存储到mysql的速度快些,
所以scrapy提供了另外一种异步的数据存储方法(一种异步的容器,还是需要使用pymysql)
首先把mysql的配置连接信息写进setting配置文件,方便后期修改
MYSQL_HOST = "localhost" MYSQL_DBNAME = 'spider' MYSQL_USER = "root" MYSQL_PASSWORD = "123456"
接着在pipeline中导入scrapy提供的异步的接口:adbapi
from twisted.enterprise import adbapi
完整的pipeline如下:
class MysqlTwistedPipeline(object): #下面这两个函数完成了在启动spider的时候,就把dbpool传入进来了 def __init__(self,dbpool): self.dbpool = dbpool #通过下面这种方式,可以很方便的拿到setting配置信息 @classmethod def from_settings(cls,setting): dbparms = dict( host = setting['MYSQL_HOST'], db = setting['MYSQL_DBNAME'], user = setting['MYSQL_USER'], password = setting['MYSQL_PASSWORD'], charset = 'utf8', #cursorclass = pymysql.cursors.DictCursor, use_unicode = True, ) #创建连接池, dbpool = adbapi.ConnectionPool("pymysql",**dbparms) return cls(dbpool) # 使用twisted将mysql插入变成异步执行 def process_item(self, item, spider): # 指定操作方法和操作的数据 query = self.dbpool.runInteraction(self.do_insert,item) #处理可能存在的异常,hangdle_error是自定义的方法 query.addErrback(self.handle_error,item,spider) def handle_error(self,failure,item,spider): print(failure) def do_insert(self,cursor,item): #执行具体的插入 # 根据不同的item 构建不同的sql语句并插入到mysql中 insert_sql = """ insert into jobbole_article(title,create_date,url,url_object_id, front_image_url,front_image_path,praise_num,comment_num,fav_num,tags,content) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) """ # 使用游标的execute方法执行sql cursor.execute(insert_sql, (item["title"], item['create_date'], item['url'], item['url_object_id'], item['front_image_url'], item['front_image_path'], item['praise_num'], item['comment_num'], item['fav_num'], item['tags'], item['content']))
注意:导入pymysql需要单独导入cursors
import pymysql import pymysql.cursors
一般我们只需要修改do_insert方法内容就行
还有,传递给的item要和数据表的字段对应上,不能以为不传值就会自动默认为空(但是存储到json文件就是这样)
除了pymysql,还可以通过安装mysqlclient连接数据库,但安装前需要先安装别的包,否则会报错
ubuntu需要安装:
(one_project) laoni@ubuntu:~$ sudo apt-get install libmysqlclient-dev
centos下需要安装:
(one_project) laoni@ubuntu:~$ sudo yum install python-devel mysql-devel