在测试计划页面首先添加 ,点击浏览按钮找到jar包,打开即可,通过jar包连接mysql数据库
,点击浏览按钮找到jar包,打开即可,通过jar包连接mysql数据库
右键线程组添加->配置原件->JDBC Connection Configuration,在Variable Name文本框里输入一个变量名,其余的按图中填写,Database URL那要包含连接的服务器IP、端口和数据库,也可以在数据库stu后面输入useUnicode=true&characterEncoding=utf8&allowMultiQueries=true,或者allowMultiQueries=true也行,如下图:
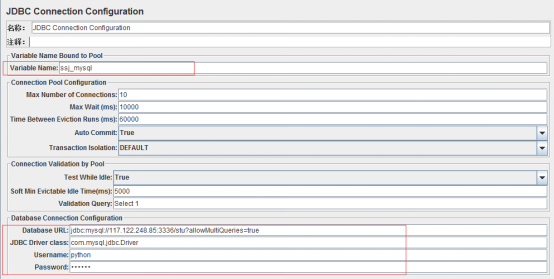
各参数分析:
Variable Name:JDBC创建连接池的名称,因为这里测试的是MySQL,所以设置为MySQL,这里一定注意要与JDBC Request中的Variable Name保持一致
Max Number of Connections:JDBC连接池的最大连接数,如果该值设置为0,则表示线程之间独立不使用共享线程池,如果要使用共享线程池,则确保该值大于或等于最大线程数
Pool Timeout:创建连接池时的超时时间,如果超过这个时间,则系统会抛出错误信息
Idle Cleanup Interval(ms):连接池的空闲时间,默认是1分钟
Auto Commit:是否自动提交,默认选择为True
Transaction Isolation:数据库事务隔离级别,默认为default。MySQL数据库事务隔离级别有4种,分别是Read Uncommited、Read Commited、Repeatable Read 、Serializable。级别越低,支持的并发往往会更大,并且系统开销也会越小
Keep-Alive:是否开启长连接机制,如果开启keep-alive,则需要设定keep-alive的超时时间
Max Connection Age(ms):keep-alive的超时时间,在连接超时之前,新的请求会重用之前建立的连接,而不会重新创建新的连接,如果超过这个超时时间,则会断开原有连接,新的请求会重新创建新的连接
Validation Query:测试JDBC连接是否畅通,默认是select 1 from default
Database URL:JDBC连接字符串,因为这里测试的是MySQL,所以写成jdbc:mysql://192.168.2.115:3306[port]/dbname(bugfree)?allowMultiQueries=true
JDBC Driver class:com.mysql.jdbc.Driver
Username:XXX
Password:XXXXXX
点击测试计划,点击浏览按钮,找到对应的jar包,将其添加到Library或jmeter的lib目录下,JDBC Request里填写的内容如下,保存后点击 ,在查看结果树里看运行是否成功
,在查看结果树里看运行是否成功
右键线程组添加->Sampler->JDBC Request,在Variable Name文本框里输入一个变量名,保证Variable Name和JDBC Connection Configuration的一致,在JDBC Request的Query页面写sql语句,当Query Type选择Select Statement时,sql语句里不能有update操作,否则执行会报错,同理当Query Type选择Update Statement时,sql语句里不能有select操作,否则执行会报错,选择Query Type时可以有一条insert操作,再有一条update操作也可以
allowMultiQueries=true,是执行多条select操作的意思,当有多条select操作时,所有的sql语句都被执行,但是只显示第一条的结果,这是jmeter的问题,Query Type选择Callable Statement时可以看到所有的select执行结果,Callable Statement一般是调用存储过程时候用的
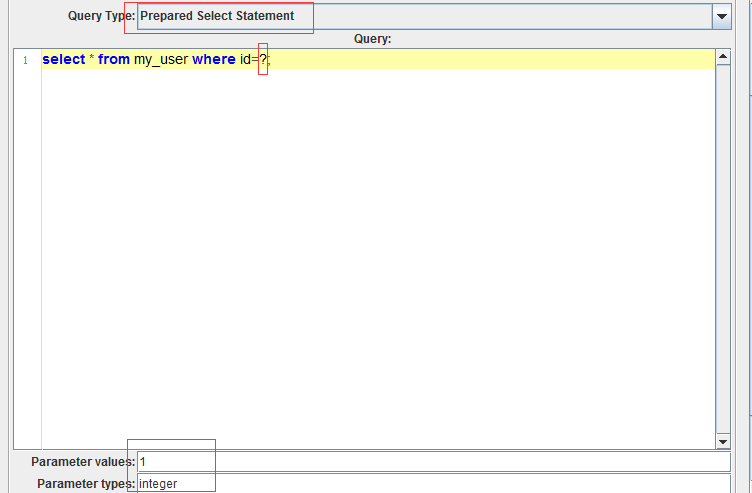
当sql语句的值写?时,Query Type要选择Prepared Select Statement(预编译查询),Parameter values输入想查询的id值,Parameter types选择integer或bigint,Variable names输入id,name,在JDBC Request下面添加一个Debug PostProcessor,会把查询到的数据保存到这两个变量里,id_#和name_#是count(id)和count(name)的意思,id_1就是第一个id,name_1就是第一个name,id_2和name_2以此类推
Result variable name输入xxx,会把返回的结果保存到xxx里,xxx是一个list,里面有多个{id=1,name='cc'}

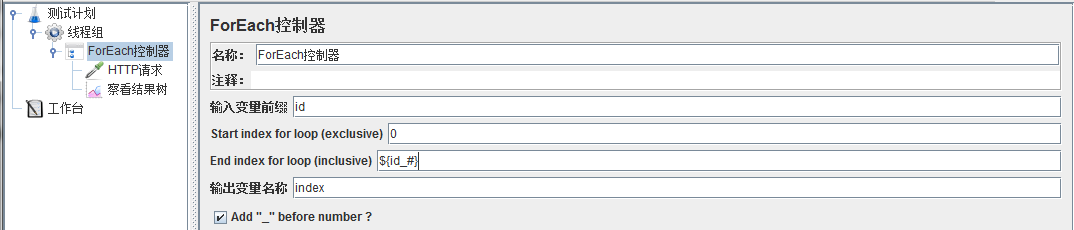
ForEach控制器:
输入变量前缀输入id,循环开始的下标输入0,结束的下标是${id_#},结束的下标也可以写死,比如3,就是循环3次,把0,1,2的下标打印出来,如果在线程组里设置多个线程,每个线程取值都是一样的,输出变量名称用index,在HTTP请求里的参数值就是${index}
勾上Add "_" before number?勾上它就在变量前加上下划线
计数器
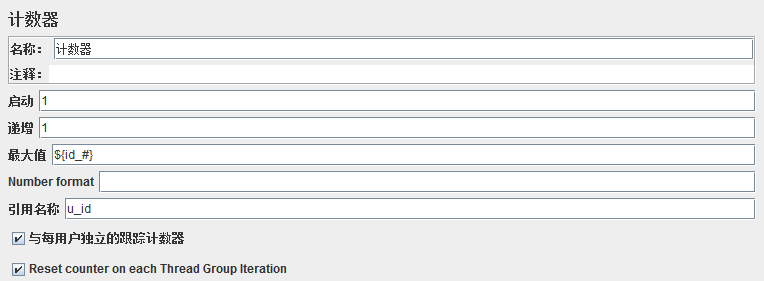
启动从1开始,递增1个,最大值就是${id_#},Number format就是00,000的格式,不写就是1,2...格式,如果最大值写6,3个线程,循环2次,就是1,2,3,4,5,6顺序取值
勾上与每用户独立的跟踪计数器,每个线程有自己的计数器,5个线程,循环1次,都取1,如果3个线程,循环2次,就是1,2 1,2 1,2,勾上Reset counter on each Thread Group Iteration(在每个线程组迭代上重置计数器),如果3个线程,循环2次就是1,1,1,1,1,1
如果最大值写${id_#},线程只能写1,只能控制循环次数,才能逐个取值
如果线程数多,最大值就得写真实的数字,不能写${id_#},函数助手里有个__V,来设置HTTP请求里的value
仅一次控制器 把JDBC Request放到仅一次控制器的下面,线程组里有一个线程就执行一次,跟线程数对应
吞吐量控制器,跟吞吐量没有关系,选择Total Executions,吞吐量输入1,吞吐量控制器下面的请求只执行一次,即便有100个线程也执行一次,吞吐量输入几就执行几次,如果再勾选Per User就是每个用户执行一次,100个请求就执行100次,勾选Per User跟吞吐量就没有关系了
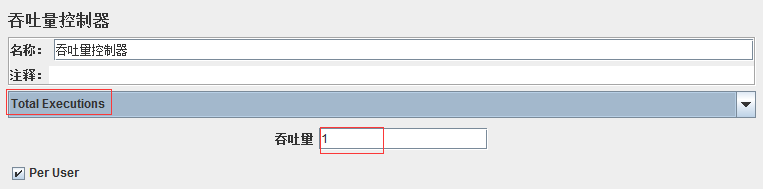
选择Percent Executions,吞吐量输入20,就是20%*2(线程组里的请求次数=线程数*循环次数)=0.4,四舍五入为0,查看结果树里没有请求,如果大于0.5就是1次请求,如果再勾选Per User就是几个线程执行几次

select id,name from test_user limit ${u_id},1就是每次取一条,就是依次把数据都取出来了