版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/u013517797/article/details/79438239
上一篇讲解了如何使用Java连接RabbitMQ服务,并实现一个简单队列模式。本篇讲解RabbitMQ的另一个队列模式----work模式。
work的队列模式图如下所示:
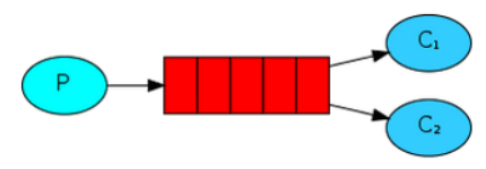
可以看到,该模式下有一个生产者,一个队列和多个消费者。
一个生产者将一个消息发送至队列,此时对于多个消费者,只能有一个消费者获取到消息,即是消费者谁先抢到谁拿到该消息。
那么以基本的简单模式的队列来实现work模式队列,是否能达到上面所说的效果呢?
我们在原来的“RabbitMQ_Test”工程上创建新的生产者和消费者进行测试。
首先创建生产者:
package cn.jack.rabbitmq.work;
import cn.jack.rabbitmq.connection.ConnectionUtil;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
public class Send {
private final static String QUEUE_NAME="test_queue_work";
public static void main(String[] args) throws Exception {
//获取到连接以及mq通道
Connection connection = ConnectionUtil.getConnection();
//从连接中创建通道
Channel channel = connection.createChannel();
//声明(创建)队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//发送100条信息
for(int i=0;i<100;i++){
//消息内容
String message = "Hello World!"+i;
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("[product] Send '"+ message +"'");
Thread.sleep(i*10);//随着发送的信息越多而间隔越长
}
//关闭通道和连接
channel.close();
connection.close();
}
}
在该生产者中,我们同样创建了连接和通道,定义了一个名为“test_queue_work”的队列,然后向队列以递增的间隔向队列发送消息,共100条。
然后是两个消费者Recv1和Recv2:

package cn.jack.rabbitmq.work;
import cn.jack.rabbitmq.connection.ConnectionUtil;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.QueueingConsumer;
public class Recv1 {
private final static String QUEUE_NAME = "test_queue_work";
public static void main(String[] argv) throws Exception {
// 获取到连接以及mq通道
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 定义队列的消费者
QueueingConsumer consumer = new QueueingConsumer(channel);
// 监听队列,手动返回完成
channel.basicConsume(QUEUE_NAME, false, consumer);
// 获取消息
int Count = 0;// 统计收到的信息历史条数
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(" [consumer1] Received '" + message + "'");
System.out.println(" now Received MessageSize:'" + ++Count + "'");
//休眠10ms
Thread.sleep(10);
// 返回确认状态
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
}
}
对于Recv1,它每休眠10ms再进行信息的接收。
package cn.jack.rabbitmq.work;
import cn.jack.rabbitmq.connection.ConnectionUtil;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.QueueingConsumer;
public class Recv2 {
private final static String QUEUE_NAME = "test_queue_work";
public static void main(String[] argv) throws Exception {
// 获取到连接以及mq通道
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 定义队列的消费者
QueueingConsumer consumer = new QueueingConsumer(channel);
// 监听队列,手动返回完成
channel.basicConsume(QUEUE_NAME, false, consumer);
// 获取消息
int Count = 0;// 统计收到的信息历史条数
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(" [consumer2] Received '" + message + "'");
System.out.println(" now Received MessageSize:'" + ++Count + "'");
//休眠1000ms
Thread.sleep(1000);
// 返回确认状态
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
}
}
对于Recv2,它每休眠1000ms再进行信息的接收。
开始运行生产者和两个消费者,首先运行两个消费者进行监听,然后再运行生产者:
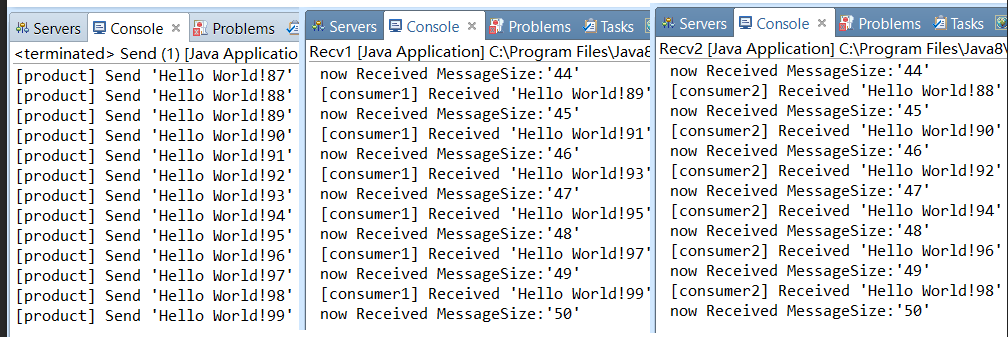
然后发现以下结论:
(1)消费者1和消费者2获取到的信息内容是不同的,同一个信息只能被一个消费者获取。
(2)消费者1和消费者2获取到的信息的数量是相同的,一个是奇数一个是偶数。
但是这样是不合理的,因为消费者1休眠的时间段,按理说应该要比消费者2拿到的信息多才对。
所以这里就牵扯到了work模式的“能者多劳”机制。
对于“能者多劳”机制,自然就是我们一开始所想的,获取信息速度快的人就会拿到的信息多一些。
实现“能者多劳”机制,关键在于对消费者的设定,我们需要在消费者声明队列后添加以下代码:
channel.basicQos(1);
即是同一时刻服务器只会发一条消息给消费者,它是指RabbitMQ服务器在同一个时刻,只向客户端/消费者发送一条消息。
我们为Recv1和Recv2在声明队列后添加channel.basicQos(1);代码:
//...前面代码省略
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 同一时刻服务器只会发一条消息给消费者
channel.basicQos(1);
// 定义队列的消费者
QueueingConsumer consumer = new QueueingConsumer(channel);
//...后面代码省略
然后重新运行消费者1和2,然后再运行生产者,本次运行结果为;
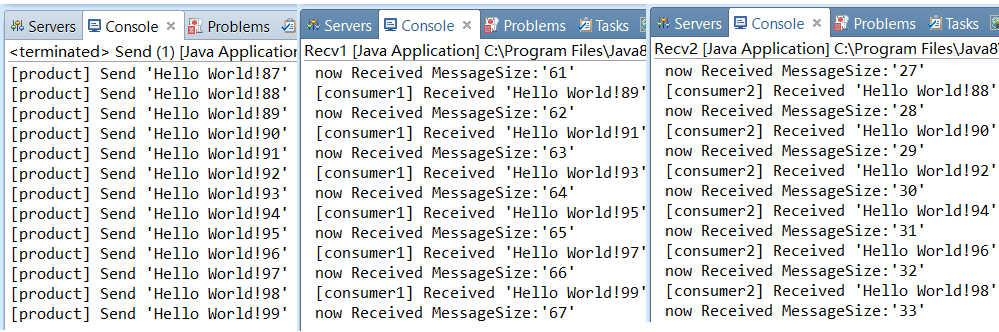
这样就实现了“能者多劳”的机制了。
work模式能够用来做什么呢?即是它的应用场景是什么呢?其实,work模式之所以叫做“工作”模式,就好像是老板给员工分配任务一样,每个人拿到的任务是不同的,谁领到什么任务就做什么任务。
例如某系统作用是写数据到数据库,如果其它系统都去访问它压力会比较大,于是乎就会做一个集群,再部署一个相同的系统,也做写数据这个事情。要求它们写数据的时候是不能写重复的数据的,那么其它系统去调用它的时候,相当于再给它下发任务(发消息),通过work模式,此时集群中两台服务器拿到的任务(消息)不一样,则插入的数据也会不一样,避免了重复插入数据的情况。
以上就是RabbitMQ的“work”队列模式。
转载请注明出处:http://blog.csdn.net/acmman/article/details/79438239
————————————————
版权声明:本文为CSDN博主「光仔December」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/acmman/article/details/79438239