这篇博文主要是解释偏差和方差,以及如何利用偏差和方差理解机器学习算法的泛化性能
综述
在有监督学习中,对于任何学习算法而言,他们的预测误差可分解为三部分
- 偏差
- 方差
- 噪声
噪声属于不可约减误差,无论使用哪种算法,都无法减少噪声。 通常噪声是从问题的选定框架中引入的错误,也可能是由诸如未知变量之类的因素引起的,这些因素会影响输入变量到输出变量的映射。噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。而剩下两种误差则与我们选择的学习算法相关,并且可以通过一些方法减小
数学推导
对于测试样本 x, 令
上面的期望预测是针对 不同 数据集 D, f 对 x 的预测值取其期望, 也被叫做 average predicted. 使用样本数目相同的不同训练集产生的方差为
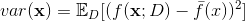
期望输出与真实标记的差别成为偏差

噪声
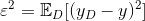
算法的期望泛化误差E(f ;D)为
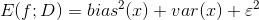
偏差
偏差度量了学习算法的期望预测和真实值之间的差别,刻画了学习算法本身的拟合能力.
- 低偏差:表明期望输出和真实标记之间误差小,学习算法拟合能力更强
- 高偏差:表明期望输出和真实标记之间误差大,学习算法拟合能力较差
低偏差机器学习算法的示例包括:决策树,kNN和支持向量机;高偏差机器学习算法的示例包括:线性回归,线性判别分析和逻辑回归
通常来说线性算法学习速度更快,更易于理解,但灵活性较低而无法从数据集中学习复杂的信号,具有较高的偏差.因此,它们针对复杂问题具有较低的预测性能.想象一下,将线性回归拟合到具有非线性模式的数据集:
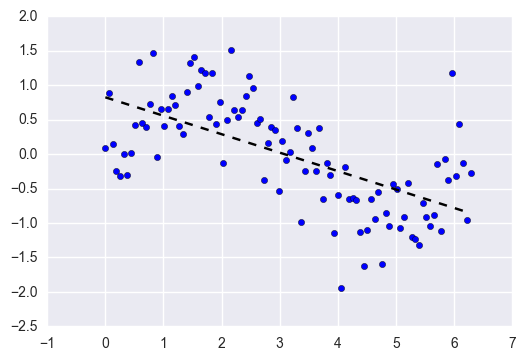
无论我们采集多少观察值/样本,线性回归都将无法对数据中的曲线建模,期望输出与真实标记之间有很大差别也就是说模型具有很高的偏差,这就是欠拟合.
方差
方差度量了样本量相同的的不同训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
目标函数是由机器学习算法从训练数据中估算出来的,因此我们应该期望算法具有一定的方差。理想情况下,从一个训练数据集到下一个训练数据集的方差不应太大,这也意味着该算法能学习到输入和输出变量之间的隐藏底层映射。而具有高方差的机器学习算法容易受到训练数据细节的强烈影响.
- 低方差:表明训练数据集的变化对目标函数的估计值造成较小的变动
- 高方差:表明训练数据集的变化对目标函数的估计值造成较大的变动
通常,具有很大灵活性的非线性机器学习算法具有很大的方差.例如,决策树具有很高的方差,如果在使用前不对决策树进行减枝,则差异更大。
低方差机器学习算法的示例包括:线性回归,线性判别分析和逻辑回归。
高方差机器学习算法的示例包括:决策树,kNN和支持向量机
例如,假设有一个算法可以完全不受约束的拟合上面的同一数据集:
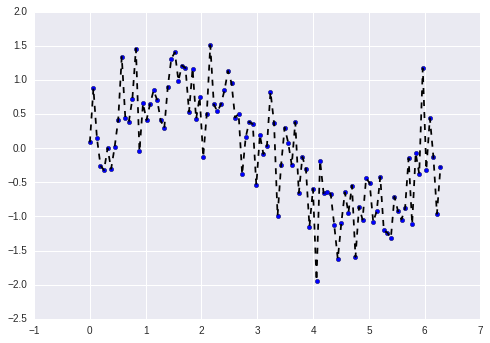
上述模型基本上已经拟合了全部训练数据,甚至是噪声,因此当训练数据发生轻微变化时会导致模型以及模型预测值产生很大的变动,这被称为过拟合
方差-偏差折衷
偏差-方差分解说明,泛化性能是由学习算法的能力,数据充分性以及学习任务本身的难度决定的.给定学习任务为了取得更好的泛化性能,则需要使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小.任何监督式机器学习算法的目标都是实现低偏差和低方差,这意味着算法应该有一个好的的预测性能.从上面的示例中我们也可以看到:
- 线性机器学习算法通常具有高偏差低方差
- 非线性机器学习算法通常具有较低的偏差但具有较高的方差
机器学习算法的参数化通常就是在偏差和方差中寻求平衡,以下是为特定算法进行偏差方差折衷的一个示例:
- 支持向量机算法具有低偏差和高方差,但是可以通过增加C参数来改变权衡,该参数会影响训练数据中允许的余量的违反次数,从而增加偏差但减小方差。
一般来说偏差和方差是有冲突的,在机器学习中,偏差和方差之间始终存在如下的关系
- 增加偏差将减小方差
- 增加方差将减少偏差
下图给出了一个示意图,当算法复杂度不够或者是训练程度不足时,学习器的拟合能力不足,偏差主导泛化错误率.随着算法复杂度加深或训练程度加强,学习器的拟合能力逐渐增强,训练数据的扰动逐渐被学习器学习到,此时方差逐步主导了泛化错误率.而我们要做的就是在在偏差和方差之间寻找一个平衡点,即泛化误差最小的点, 达到optimal balance.

我们选择的算法以及平衡偏差和方差方式会产生不同的折衷效果.
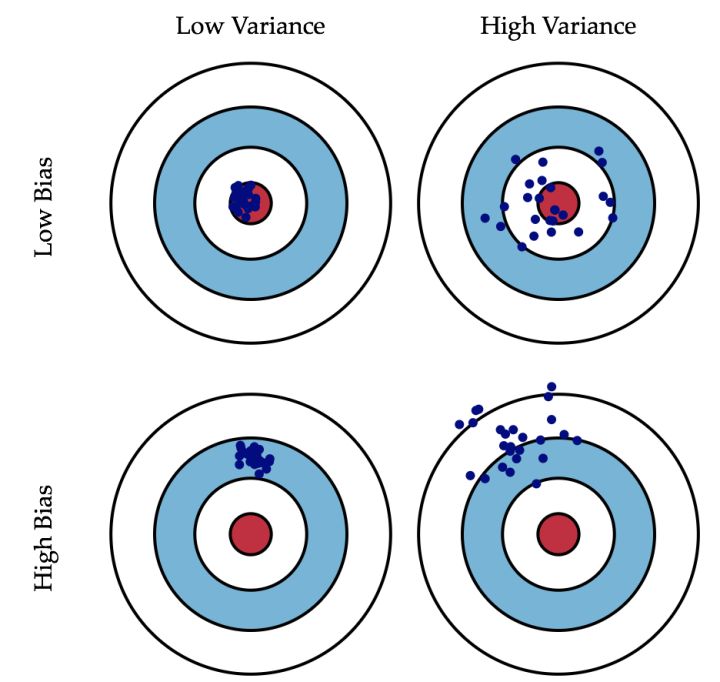
上图中蓝色的点表示预测值,中心红点表示真实值,蓝点越靠近中心点表明预测值与真实值越接近,偏差越小.蓝色点越分散表明预测值之间差别很大,方差大,反之蓝色点越集中表明预测值之间差别很小,从而方差小
实际上我们无法计算真实的偏差和方差值,因为我们不知道真正的的目标函数是什么,但我们可以利用偏差和方差帮助我们更好的理解机器学习算法的性能,在偏差和方差之间寻求平衡可以使我们的模型避免过拟合或者欠拟合.
reference <机器学习>---周志华
Gentle Introduction to the Bias-Variance Trade-Off in Machine Learning--Jason Brownlee
Understanding the Bias-Variance Tradeoff
WTF is the Bias-Variance Tradeoff? (Infographic)