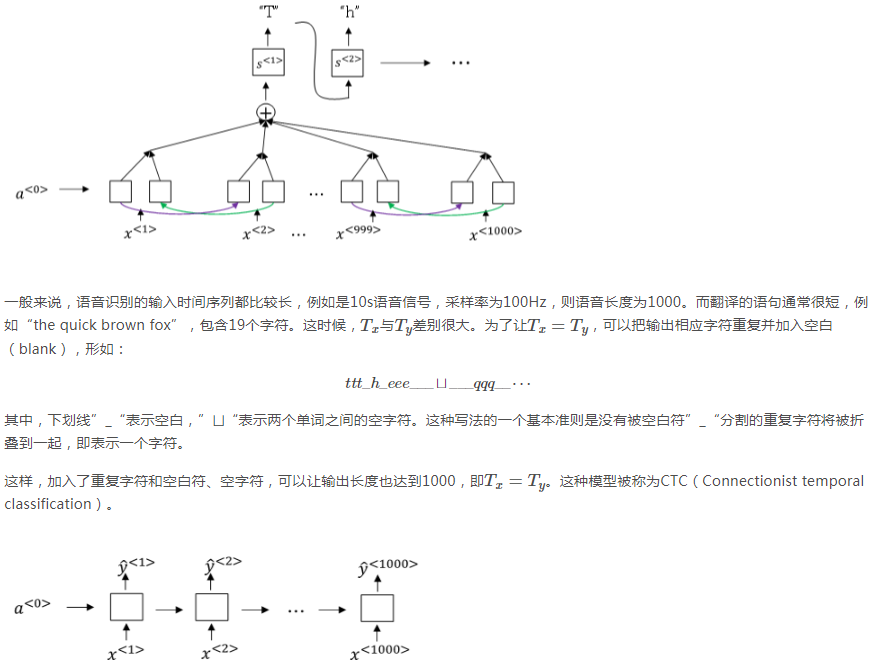
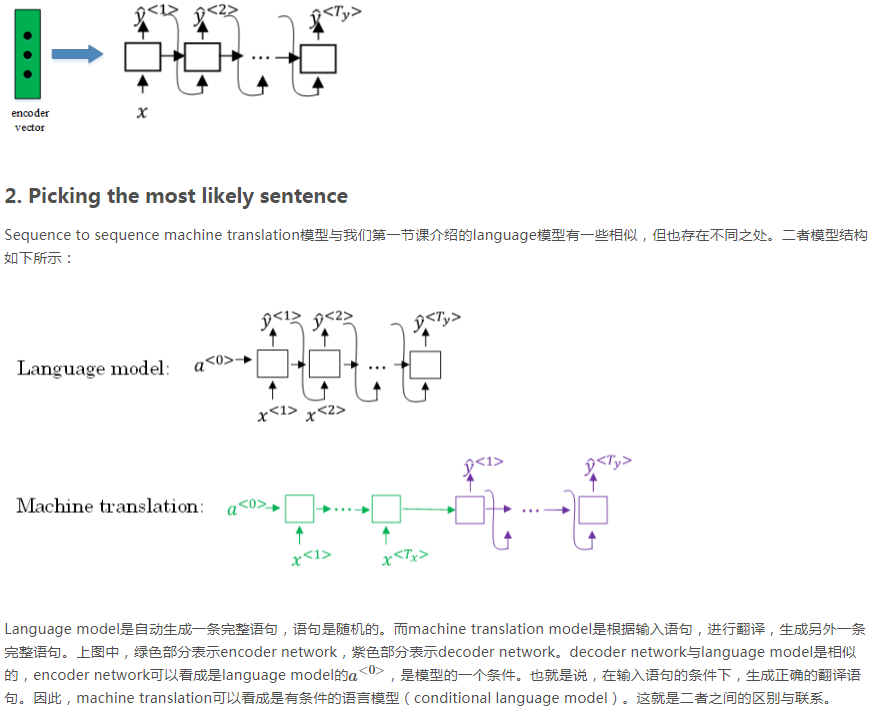

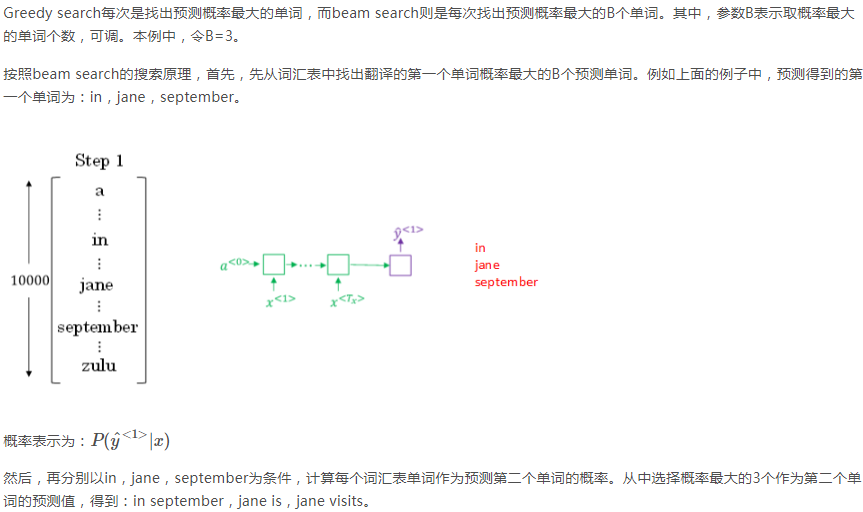
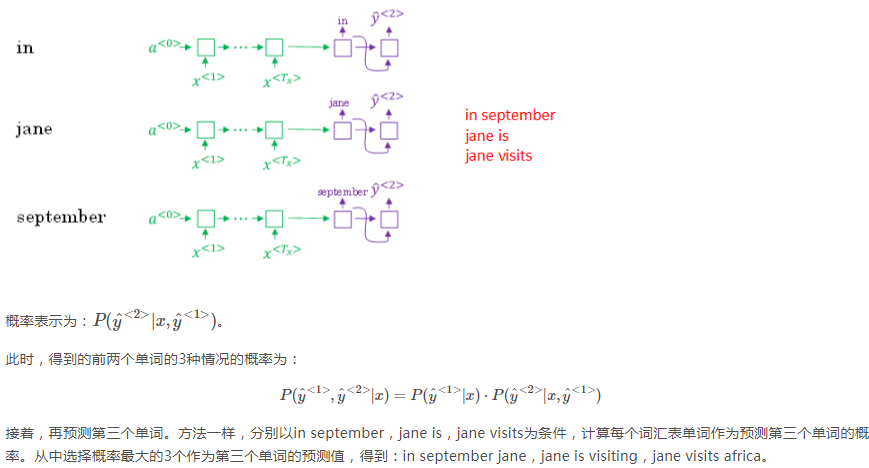
in、jane、semptember都有10000个备选词,所以一共有30000个选择,从这30000个里面选择三个概率最大的作为前两个单词。要注意,前两个词出现的概率=第一个词的概率*第二个词的概率


所以实际计算句子的概率时,用的是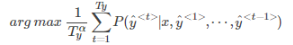 这个式子,而不是把每个词出现的概率相乘。
这个式子,而不是把每个词出现的概率相乘。
y*和y帽概率的计算方法和之前计算某个句子的概率的方法相同。

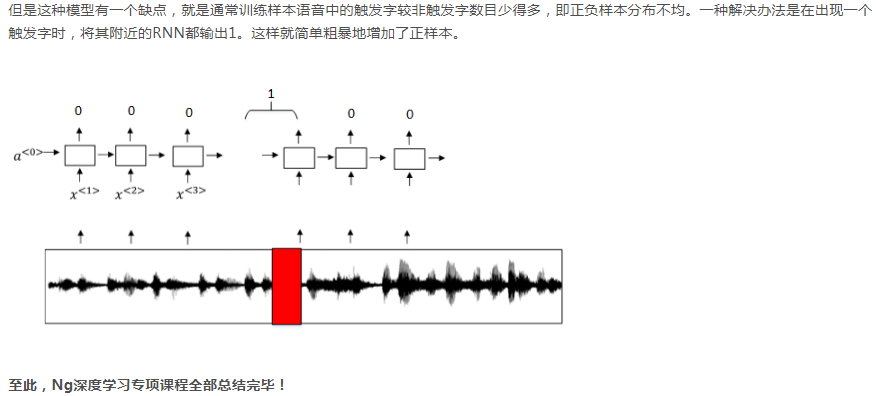
在实际应用时,可以列出一个表,把翻译错误的句子列出来,然后看看错误原因里束搜索和RNN模型占的比例,判断到底什么是导致错误出现的主要原因,再进行优化。




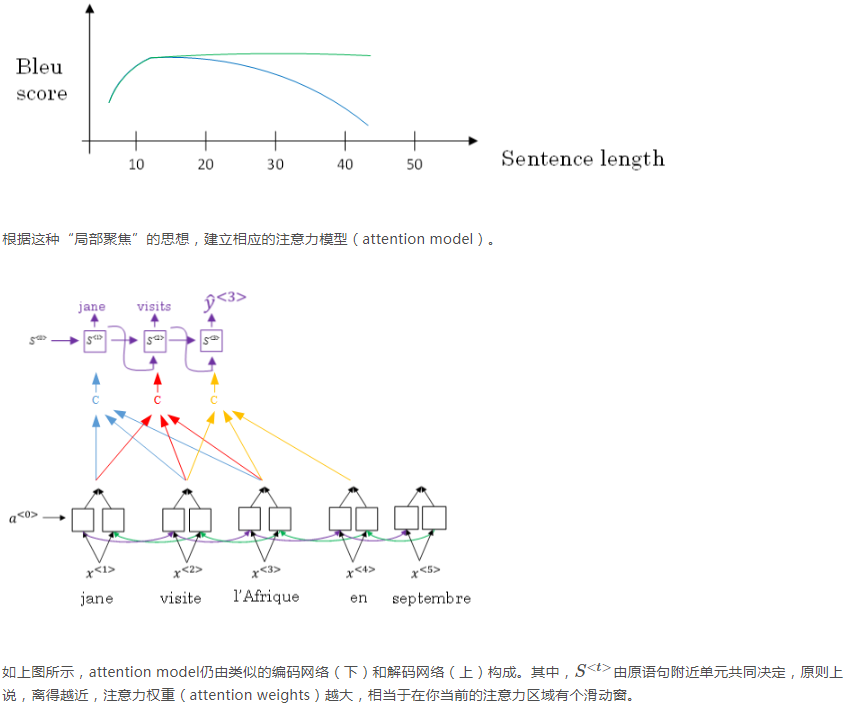
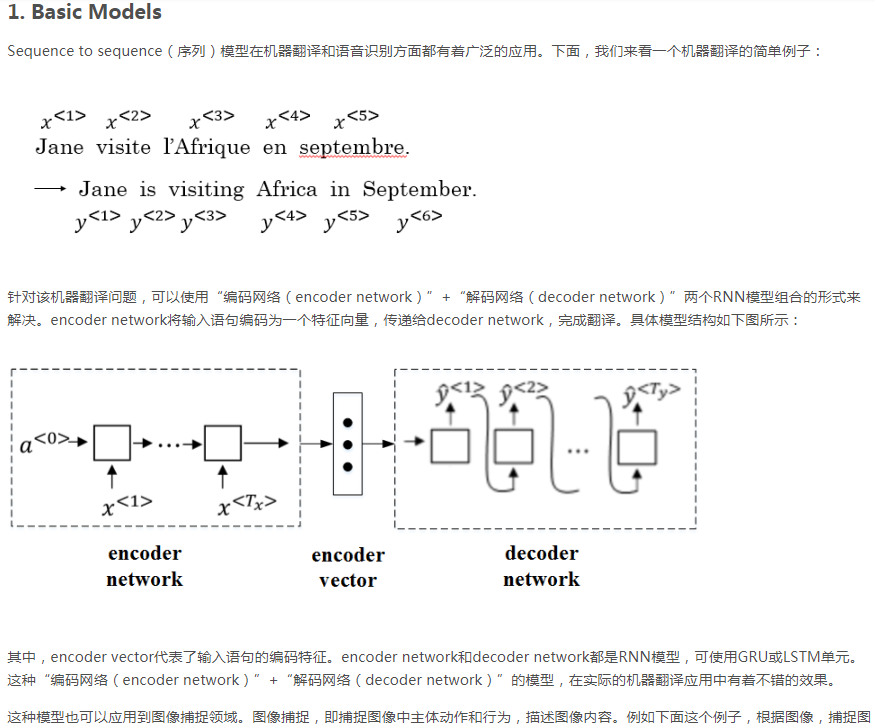
编码网络的作用是将原法语的每个词都转换为对应的特征向量,然后每个词的特征向量再乘一个对应的权重α,加权和作为解码网络的输入。
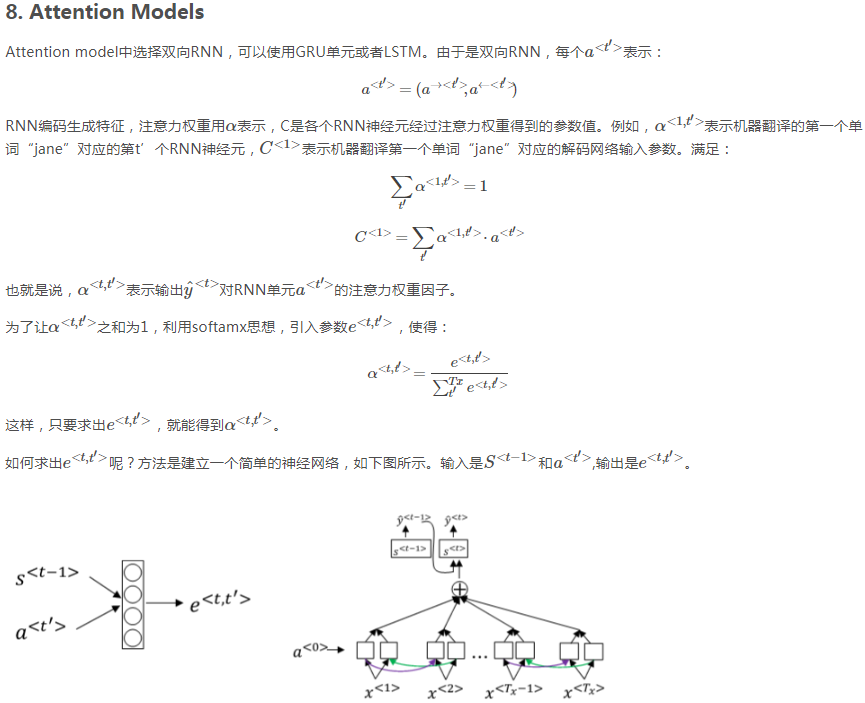
需要注意的是,s<t>的输入有两部分,一部分是y<t-1>帽,另一部分是编码网络特征向量的加权和。
(注:带 ' 的是原法语 不带 ' 的是译文)