Skip list(跳跃表)是一种可以代替平衡树的数据结构。Skip lists应用概率保证平衡,平衡树采用严格的旋转(比如平衡二叉树有左旋右旋)来保证平衡,因此Skip list比较容易实现,而且相比平衡树有着较高的运行效率。目前开源软件 Redis 和 LevelDB 都有用到它,它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,就能轻松实现一个 SkipList。
http://www.cnblogs.com/davad/articles/3049086.html
空间复杂度: O(n) (期望)
跳跃表高度: O(log n) (期望)
相关操作的时间复杂度:
查找: O(log n) (期望)
插入: O(log n) (期望)
删除: O(log n) (期望)
http://www.cppblog.com/mysileng/archive/2013/04/06/199159.html
Skip List构造步骤:
1、给定一个有序的链表。
2、选择连表中最大和最小的元素,然后从其他元素中按照一定算法(随机)随即选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层。
3、为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素
4、重复2、3步,直到不再能选择出除最大最小元素以外的元素。
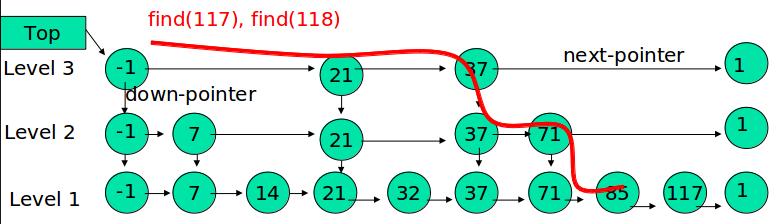
一、查找
二、插入
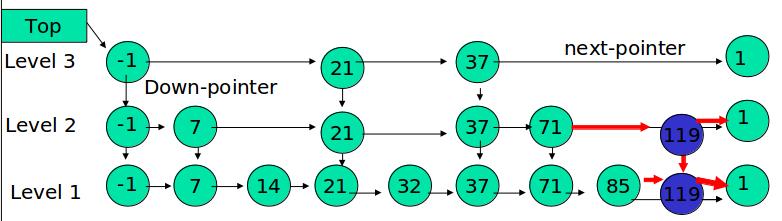
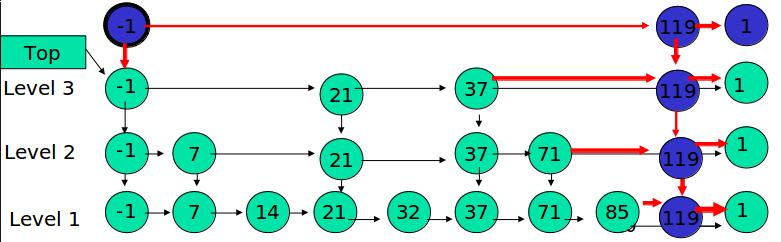
目的:向跳跃表中插入一个元素x
首先明确,向跳跃表中插入一个元素,相当于在表中插入一列从S0中某一位置出发向上的连续一段元素。有两个参数需要确定,即插入列的位置以及它的“高度”。
关于插入的位置,我们先利用跳跃表的查找功能,找到比x小的最大的数y。根据跳跃表中所有链均是递增序列的原则,x必然就插在y的后面。
而插入列的“高度”较前者来说显得更加重要,也更加难以确定。由于它的不确定性,使得不同的决策可能会导致截然不同的算法效率。为了使插入数据之后,保持该数据结构进行各种操作均为O(logn)复杂度的性质,我们引入随机化算法(Randomized Algorithms)。
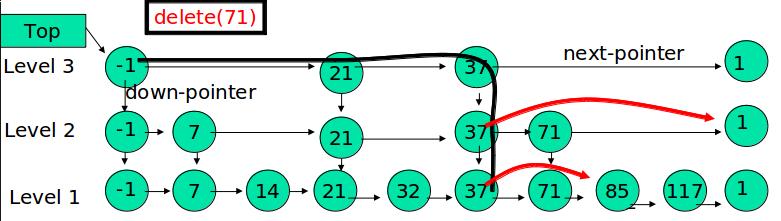
三、删除