
语法:
选取节点:
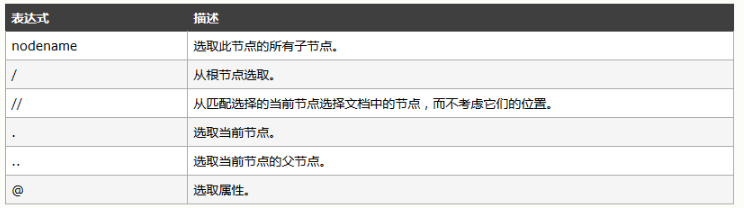
实例:

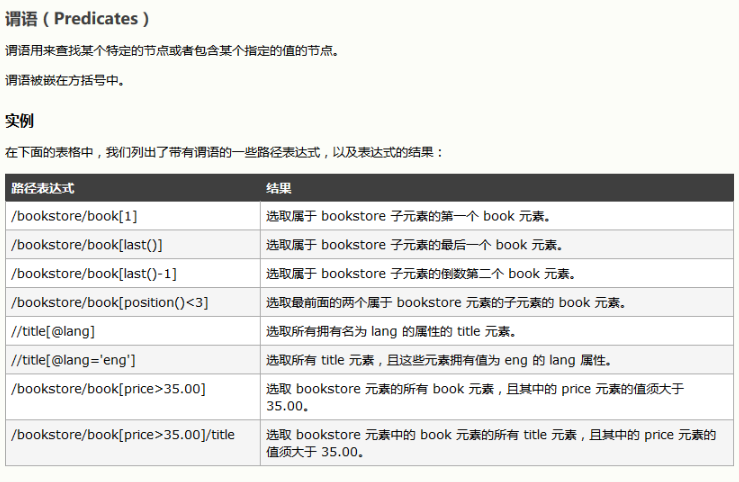

 (贴图转载自w3school)
(贴图转载自w3school)
补充:
/a/@href #获取a标签的href属性
当<div class="demo"></div>种情况的时候我们可以写成/div[@class="demo"]
但如果是
<div class="demo1 demo2 demo3"></div>
这种情况我们如果匹配demo2就不能直接用等于的方法
可以用/div[contains(@class,'demo2')]
如果选择demo2和demo3
可以用/div[contains(@class,'demo2') and contains(@class,'demo3')]
/*网上的一个相关解答还有一个*/
如果目标Class不一定是第一个,那么
//div[contains(concat(' ',@class,' '),'demo')]
没看明白,但是暂且保留
python下用lxml模块
导入的时候只需要一个etree来接收就可以
import ...
from lxml import etree
...
html = urllib.request.urlopen(url)
content = etree.HTML(html)
cont_list = content.xpath('/div[@class="test"]')
//cont_list接收的是一个匹配成功的列表